代碼書寫注意事項:
1.用字符串常量構造字符串對象時,std::wstring時用宏L;構造CString和別的隨配置可變字寬類型對象時用宏_T;
2.用系統函數時要選用可隨系統配置變化的API如:::GetDirect(),並傳入可變字寬的字符串對象如LPCTSTR,
不提昌用::GetDirectA()或::GetDirectW()這樣被定死的;
3.當需要外來參數向本地代碼參數傳值或相反情況時,如果其中一個參數是可隨配置變化的,另一個是定死的,此時
建議用宏把代碼區分開:#ifdef _UNICODE
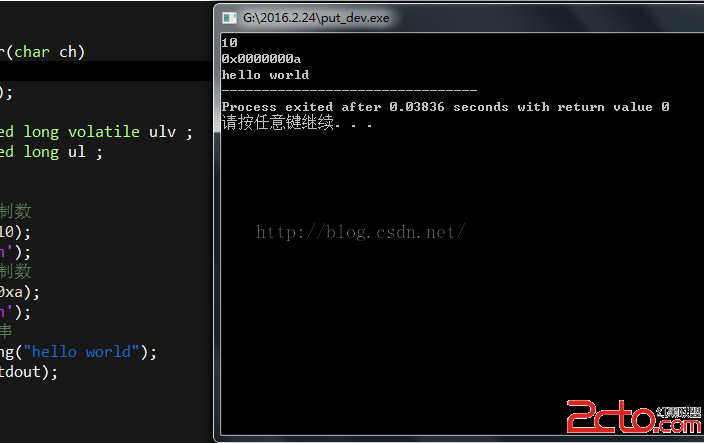
m_img = new Gdiplus::Image(szFilename,FALSE);
#else
m_img = new Gdiplus::Image(A2W(szFilename), FALSE);
#endif
4.構造CString類對象時,要用_T,不然雖能編過(內部轉換),CString("古月方")即使以UNICODE編譯的在非本地語言機子上顯示還是亂碼。
我是比較喜愛CString的高效易用和靈活性的。它內部的引用計數機制和隨配置字寬可變性是很好的。
5.替換常用的正則表達式:
_T\({"[^"]*"}\)
L\1
MessageBox\(L{"[^"]*"}
MessageBox(_T(\1)
MessageBox\({[^,]*},L{"[^"]*"}
MessageBox(\1,_T(\2)
MessageBox\({[^,]*}, {[^,]*}, L{"[^"]*"}
MessageBox(\1, \2, _T(\3)
C 語言原本是在英文環境中設計的,主要的字符集是7 位的ASCII 碼。從此開始,8 位的byte(字節)變成最常見的字符編碼單位,但是國際化軟件必須能夠表示不同的字符,ISO C 可以標准化兩種表示大型字符集的方法:寬字符(wide character,該字符集內每個字符使用相同的位長)以及多字節字符(multibyte character,每個字符可以是一到多個字節不等,而某個字節序列的字符值由字符串或流(stream)所在的環境背景決定)。
注意:雖然C現在提供抽象機制,可以處理和轉換不同種類的編碼集合,但語言本身並沒有定義或指定任何編碼集合,或任何字符集(除基本源代碼字符集和基本運行字符集外)。換句話說,這部分是由個別的實現版本指定如何編碼寬字符,以及要支持什麼類型的多字節字符編碼機制。
自從1994 年的增補之後,C 不只提供char類型,還提供wchar_t類型(寬字符),此類型定義在stddef.h 頭文件中。wchar_t 類型足以表示某個實現版本擴展字符集的任何元素。雖然C 標准沒有支持Unicode 字符集,許多實現版本使用Unicode 轉換格式UTF-16 和UTF-32來處理寬字符。
C 提供了一些標准函數,可以將多字節字符轉換為wchar_t,或將寬字符轉換為多字節字符。比方說,如果C 編譯器使用Unicode 標准的UTF-16 和UTF-8,下面函數就可以獲得字符的多字節表示方式(注:wctomb = WideCharToMultiByte())。
C++的中英文字符串默示(string,wstring),字符串類的模板原型是basic_string
string完全可以存儲中文(有效編碼只有""\0""=0,其他字符均不為0),然則在顯示、字符操縱等方面是無法包管正確的!
前者string是常用類型,可以看作char[],其實這恰是與string定義中的_Elem=char相一致。而wstring,應用的是wchar_t類型,這是寬字符,用於滿足非ASCII字符的請求,例如Unicode編碼,中文,日文,韓文什麼的。對於wchar_t類型,實際上C++中都用與char函數相對應的wchar_t的函數,因為他們都是從同一個模板類似於上方的體式格式定義的。是以也有wcout,wcin,werr等函數。實際上string也可以應用中文,然則它將一個漢字寫在2個char中,但有些函數操作出錯。而若是將一個漢字看作一個單位wchar_t的話,那麼在wstring中就只占用一個單位,其它的非英文文字和編碼也是如此。如許才真正的滿足字符串操縱的請求,尤其是國際化等工作。
(CSDN資料)VS2010中字符集配置:定義是否應該設置 _UNICODE 或 _MBCS。在適當的地方還影響鏈接器入口點。
可以通過用字母 L 作為字符的前綴將任何 ASCII 字符表示為寬字符形式。例如,L'\0' 是寬(16 位)NULL 字符。同樣,可以通過用字母 L 作為 ASCII 字符串的前綴 (L"Hello") 將任何 ASCII 字符串表示為寬字符字符串形式。
C 運行時庫有兩類內部代碼頁:區域設置和多字節。在程序執行期間可以更改當前代碼頁(有關 setlocale 和 _setmbcp 函數的信息,請參見文檔)。而且,運行時庫可以獲取並使用操作系統代碼頁的值。在 Windows 2000 中,操作系統代碼頁是“系統默認 ANSI”代碼頁。此代碼頁在程序的執行期間保持不變。
內碼是指操作系統內部的字符編碼。早期操作系統的內碼是與語言相關的使用7位的ASCII編碼。為了處理漢字,程序員設計了用於簡體中文的Windows內碼GBK。目前Windows的內核已經支持Unicode字符集,然後用代碼頁適應各種語言,“內碼”的概念就比較模糊了。微軟一般將缺省代碼頁指定的編碼說成是內碼,即缺省用什麼編碼來解釋字符。例如Windows的記事本打開了一個文本文件,裡面的內容是字節流:BA、BA、D7、D6。Windows應該去怎麼解釋它呢?是按照Unicode編碼解釋、還是按照GBK解釋?
答案是Windows按照當前的缺省代碼頁去解釋文本文件裡的字節流。缺省代碼頁可以通過控制面板的區域選項設置。記事本的另存為中有一項ANSI,其實就是按照缺省代碼頁的編碼方法保存。
Windows的內碼是Unicode,它在技術上可以同時支持多個代碼頁。只要文件能說明自己使用什麼編碼,用戶又安裝了對應的代碼頁,Windows就能正確顯示。Unicode也是一種字符編碼方法,不過它是由國際組織設計,可以容納全世界所有語言文字的編碼方案。
Unicode最早的編碼想法,就是把每一個碼點(code point)都存儲在兩個字節中,這也就導致了大多數人的誤解,於是非常聰明的UTF-8的概念被引入了,用來存儲字符串所對應的Unicode的碼點。
UTF-8就是以8位為單元對UCS(Unicode字符集)進行編碼。
讀者可以用記事本測試一下我們的編碼是否正確。需要注意,UltraEdit在打開utf-8編碼的文本文件時會自動轉換為UTF-16,可能產生混淆。你可以在設置中關掉這個選項。更好的工具是Hex Workshop。
C語言中,字符(character)這個術語具有兩個層次上的含義:書寫源程序的字符和程序處理的字符。
例如,printf("你好,C!\n"); 之內的“你好\n”就屬於程序要處理的字符。
從某種意義上來說,編輯/編譯器是一種接受字符輸入,輸出可執行文件的軟件,由它產生可執行文件經過加載成為內存中的程序,這個程序通常也不可避免地要處理字符。
編輯/編譯器所要處理的字符就是書寫C語言源程序所用的字符,這種字符的集合叫源字符集(sourcecharacter set)。而應用程序要處理的字符所構成的集合叫執行字符集(execution character set)。這兩者又不同於編碼時的字符集及其配置的概念。