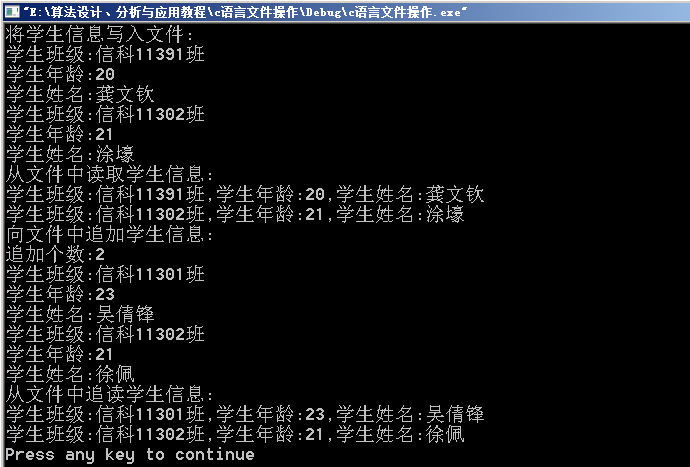
The Development of the C Language*
Dennis M. Ritchie
Bell Labs/Lucent Technologies
Murray Hill, NJ 07974 USA
不滿足網上的譯文,yqj2065自己翻譯一下。備用。【】是譯注、補充。
概要
在1970s早期,C編程語言是作為新生的Unix操作系統的系統實現語言而設計的。衍生於無類型(typeless)語言BCPL,它進化出了一個類型結構【類型系統】;在弱小的機器上,作為改善簡陋編程環境工具的這一創新,它已然成為當今主流語言之一。本文研究它的進化。
NOTE: *Copyright 1993 Association for Computing Machinery, Inc. This electronic reprint made available by the author as a courtesy. For further publication rights contact ACM or the author. This article was presented at Second History of Programming Languages conference, Cambridge, Mass., April, 1993.
It was then collected in the conference proceedings: History of Programming Languages-II ed. Thomas J. Bergin, Jr. and Richard G. Gibson, Jr. ACM Press (New York) and Addison-Wesley (Reading, Mass), 1996; ISBN 0-201-89502-1.
簡介
本文講述C程序設計語言的發展、它所受到的影響以及它誕生的條件。簡潔起見,我省略了對C自身、它的父親B[Johnson 73]和祖父BCPL[Richards 79]的完整描述,而是關注每一種語言的特性要素和它們如何演化。
在1969-1973年間,C的出現,伴隨著Unix操作系統早期的發展,最富創造性的時期是1972年。另一個一連串改變的高峰期是1977到1979年間,此時Unix系統的可移植性得以證實。第二個階段期間,出現了第一份被廣為傳播的該語言的描述:The C Programming Language,通常被稱為‘白皮書’或K&R[Kernighan 78]。最後,在1980年代中期,該語言被ANSI X3J11委員會正式標准化,並作出進一步修改。截止1980年代早期,盡管已有各種機器結構及操作系統的【C的各種】編譯器,該語言幾乎與Unix特別密切關聯;更近一些,它的使用傳播得更廣,而今天它是整個計算機產業中最廣泛使用的語言之一。
歷史背景
1960s晚期,是Bell Telephone Laboratories(貝爾電話實驗室)的計算機系統研究(中心)的動蕩歲月[Ritchie 78] [Ritchie 84]。計算機被從Multics項目組拖走[Organick 78],該項目是MIT(麻省理工學院)、General Electric(通用電氣公司)和貝爾實驗室的合作項目。到1969年,貝爾實驗室管理層、甚至研究人員認為,Multics項目不能按期完成並且代價高昂。甚至在GE-645 Multics機器被撤走之前,早期由Ken Thompson領導的一個非正式小組,已經著手一些其它的研究。
Thompson希望按照自己的設計、使用可用的任何方式,創造一個舒適的計算環境。事後諸葛亮地說,他的計劃集成了Multics的許多創新方面,包括關於進程的清晰概念——控制塊,樹型結構的文件系統、作為用戶級程序的命令解釋器、文本文件的簡單表示和訪問設備的通用化。他們排除了其余特性,比如對內存和文件的統一訪問。此外,
開始的時候,他與我們這些俗人遵循[推遲?]Multics的另一個先驅性(雖然不是原創)特性,即幾乎僅用高級語言來編程。PL/I【Programming Language One,IBM公司在1950s發明的高級編程語言】——Multics的實現語言不太符合我們的口味,因而我們也使用其他語言,包括BCPL,我們擔心【regretted?】失去使用在匯編程序的級別以上的語言進行編程的優勢,即容易編寫、易於理解。當時我們並未特別關注可移植性,到後來才有了這方面的興趣。
Thompson面臨的硬件環境,即使在那個時代也是又擁擠又簡陋:他從1968年就開始使用的DEC PDP-7,只有8K的18bit字(長)的內存,並且沒有對他有用的軟件。雖然心想著使用高級語言,他還是用PDP-7匯編器編寫了最初的Unix系統。剛開始的時候,他甚至並未在PDP-7上編程,而是在一台GE-635機器上使用GEMAP匯編器的一些宏。一個後處理器(postprocessor)生成PDP-7可讀的紙帶。
這些紙帶從GE機器拿到PDP-7上進行測試,直到一個原始的Unix內核(kernel)、一個編輯器、匯編器、一個簡單的外殼(shell)(命令解釋器)和一些工具(像Unix rm, cat, cp命令)被完成。此後,這個操作系統可以自我支持:可以編寫和測試程序,勿需借助紙帶,並且程序開發可以在PDP-7上持續進行。
Thompson的PDP-7匯編器在簡明性上甚至優於DEC的;它對表達式求值並得到對應的比特流【二進制源代碼】。沒有庫、沒有裝載器或沒有鏈接器:程序的全部源文件提交給匯編器,而其輸出文件(the output file)——有一個固定名字——是可以直接執行的(這個名字,a.out,道出了一點Unix淵源;它是匯編器的輸出。甚至在系統有了鏈接器和有了顯式指定另一個名字的方式之後,它仍被保留作為編譯器的默認可執行文件(名))。
Unix在PDP-7上首次運行後不久,1969年Doug McIlroy創造了這一新系統的第一個高級語言:一個McClure的TMG實現[McClure 65]。TMG是一種自頂而下,遞歸降解(top-down, recursive-descent)風格的編寫編譯器(更一般地,TransMoGrifiers)的語言,它將上下文無關的語法表示法與過程(式程序)元素相結合。McIlroy和Bob Morris使用TMG為Multics編寫了早期的PL/I編譯器。
受McIlroy重造TMG事跡的刺激,Thmopson認為Unix(當時可能還沒有取這個名字)需要一種系統編程語言。經過用Fortran的短暫而受阻的嘗試後,他創造了一門他自己的語言,他稱之為B。B可被視為沒有類型的C。更准確地,它是塞進8K字節內存,經過Thompson大腦過濾後的BCPL。它的名字最有可能表示為BCPL的縮寫,盡管另一種理論認為它源自於Bon[Thompson 69],Thompson在Multics的那些日子創造的一門不相關的語言。Bon進而二中其一,可能是以他妻子Bonnie的名字,或者(根據它的操作手冊中的一個百科全書般的引用)以一種宗教命名,該教儀式涉及咕隆咕隆的神奇咒語。【不知道是不是西藏的原始宗教:苯教(Bon)】【太難搞了】
起源:這些語言
BCPL是由Martin Richards於1960年代中期,在訪問麻省理工學院時設計,在1970年代早期被用在幾個有趣的項目中,其中包括位於牛津的OS6操作系統[Stoy 72],和施樂公司PARC研究中心的創造性項目Alto的一部分[Thacker 79]。我們熟悉該語言,是因為Richards工作過的MIT CTSS系統[Corbato 62]被用於Multics開發。最初的BCPL編譯器被Rudd Canaday和貝爾實驗室的一些人們移植到Multics和GE-635 GECOS系統上[Canaday 69];在貝爾實驗室的Multics項目奄奄一息階段,它成為隨後轉入Unix的一幫人選擇的語言。
BCPL、B和C都歸屬於以Fortran和Algol 60為代表的傳統過程式家族。它們格外地傾向面向系統編程、小巧、描述簡潔,而且可被簡單的編譯器輕易地翻譯。它們接近機器,它們所引入的抽象以傳統計算機所提供的具體數據類型和操作為基礎,它們依賴於例程庫以輸入輸出以及與操作系統的其它交互。盡管不太成功,它們還使用庫程序指定其他有趣的控制結構,如協程和過程關閉。同時,它們的抽象層次足夠高,足夠用心的話,能達到機器間的可移植性。
BCPL, B和C在很多細節上存在語法差異,但總體上它們是相似的。程序由一系列的全局聲明和函數(過程)聲明組成。BCPL中,過程能夠嵌套,但不能引用定義在外包過程中的非靜態對象。B和C通過更強行的限制避免了它:基本就沒有嵌套過程。每一種語言(除了早期的B版本)都認可(文件的)分別編譯,並提供了從指定文件中包含(including)文本的方式。
BCPL中的若干語法和詞法機制較B和C中的更優雅和正式的。例如,BCPL的過程和數據聲明擁有更一致的結構,並且它提供了一套更完整的循環結構。盡管BCPL程序名義上是由分界的字符流構成,聰明的規則使得以每一行結束的語句可以省略其分號。B和C忽視了這種便利,大多數語句以分號來結束。刨除這些差異,BCPL的大多數語句和操作符直接對應B和C中的相應物。
BCPL和B之間的一些結構化的差異源於介質存儲的限制。比如,BCPL聲明采用這樣的形式
let P1 be command
and P2 be command
and P3 be command
...
此處的由命令表示的程序文本包含完整過程。這些子聲明相互關聯而且同時出現,所以名字P3在過程P1內可見。相似地,BCPL能在求得一個值的表達式裡包含一組聲明和語句,例如
E1 := valof ( declarations ; commands ; resultis E2 ) + 1
BCPL編譯器在產生輸出前,通過存儲和分析內存中該完整程序的解析過的表示,可以容易地處理此類構造。B編譯器所受的存儲限制決定了一種一次通過( one-pass)技術,由此盡可能快生成輸出,而這一語法上的重新設計將這種可能帶入到C。
BCPL中一些不令人滿意的地方歸因於它的技術問題,在B的設計中它們被有意識的避免了。例如,BCPL使用一個“全局向量”(global vector)機制以在分離編譯的程序間通信。在這種模式中,程序員使用一個全局向量的數值偏移量,顯式關聯每個外部可見過程和數據對象的名字。鏈接使用這些數值偏移量,在被編譯過的代碼上完成。B起初堅持,整個程序一次性全部傳遞給編譯器,來規避這個麻煩。B的後期實現,和C的全部實現,使用一個傳統的鏈接器,來解決出現在分離編譯文件中的外部名字,而不是把指定偏移量的負擔推給程序員。
BCPL到B的轉換中引入的其它變化,大概是因為風格的緣故,一些仍是有爭議的,例如賦值使用單個字符=代替:=。類似地,B使用/**/來括起注釋,而B使用//注釋直至行末的文本。這顯然是從PL/I繼承來的。(C++重新啟用了BCPL的注釋慣例。) Fortran影響了聲明的語法:B的聲明以一個auto, static這樣的類型指定符開始,跟著一列名字,C不僅遵循這種風格,還把它的類型關鍵字,加入這種聲明的開始處。
在Richards的書中文檔化的BCPL與B之間的差別,並非都是經過深思熟慮的;我們是從一個BCPL[Richards 79]的早期版本開始工作的。例如,用於跳離switchon語句的endcase在我們1960年代開始學習該語言時,並沒有出現,所以B和C中重復出現的,用於跳離switch語句的關鍵字break,乃是一種背離的發展,而不是清醒的改變。
對比B產生過程中發生的普遍的語法變化,BCPL的核心語義內容——類型結構和表達式求值——保持不變。它們兩種語言都是無類型的,或更恰當地說有一種單一的數據類型,“字”(word)或“單元”(cell),一個固定長度的位模式。這些語言中的內存由此類單元的線形數組組成,每一個單元的內容的含義與應用的運算相關。例如,求和運算符使用機器的整數加法指令,簡單相加其運算對象,其它算術運算同樣不清楚它們運算對象的含義。因為內存是一個線形數組,只可能解析單元的值為該數組的索引,並且BCPL為這個目的提供一個運算符。在最初的語言中,它被拼寫為rv,後來為!,但是B使用一元*。因此,如果p是單元,包含另一個單元的索引(其地址,或指向的指針),*p引用被指向單元的內容,作為表達式的值或賦值對象。
因為指針在BCPL和B中只不過是整型內存數組的索引,對它們進行算術運算是有意義的:如果p是一個單元的地址,那麼p+1是下一個單元的地址。這種約定是兩種語言中數組語義的基礎。在BCPL中,一個人這樣寫
let V = vec 10
或在B中,
auto V[10];
效果是一樣的:分配了一個名字為V的單元,然後保留另一組10個連續單元,它們中第一個的內村索引,被存放在V中。按照一般的規則,在B中的表達式
*(V+i)
把V和i相加,並指向V後第i個位置。BCPL和B都增加了特別的符號,使這種對數組的訪問更簡潔;在B中的等價表達式是
V[i]
在BCPL中是
V!i
這種引用數組的方法甚至在當時仍是不常見的;C後來同化它為一種更不常規的方式。
BCPL,B或C都沒有強烈支持字符數據;每一個都把字符串當作整型數組,並通過一些慣例提供了一些一般規則。字符串字面值在BCPL和B中表示一個使用串內字符初始化的靜態區的地址,被包裝成單元。在BCPL中,第一個被包裝的單元包含串所擁有的字符個數;在B中,沒有此計數,字符串以一個特別的字符終結,在B中杯拼寫為“*e”。這個改變部分是為了避免把計數值放在一個8位或9位槽(slot)產生的串長度限制,部分是因為維護這個計數,從我們的經驗看來,不如使用一個終結符方便。
在BCPL,串中每個字符的使用,是通過被展開為另一個數組,一個字符對應一個單元,然後進行再次包裝;B提供了對應的例程,但人們更多地使用,另外的訪問或替換一個串內字符的庫函數。
更多歷史
在TMG版本B工作後,Thompson利用B重寫了B(編譯器)(一個bootstrapping步驟)。在開發中,他不斷與內存限制作斗爭:每次語言版本使編譯器膨脹令內存幾乎不夠使用,但每次重寫利用語言特征的優點,減少了它的尺寸。例如,B引入通用賦值運算符,使用x=+y來把y加入x。這個符號經過McIlroy引自Algol 68[Wijngaarden 75],他將它合並到他實現的一個TMG版本。(在B和早期C,該運算符被拼作=+而不是+=;這個由B的詞法分析的第一種形式的迷惑捷徑導致的錯誤,在1967年被修復。)
Thompson通過發明自增++和自減--運算符,走出了更深遠的一步;它們的前綴或後綴位置決定變更是發生在計算運算對象值之前或之後。它們沒有出現在B的最早版本中,而是隨後才出現的。人們經常猜測,它們被創造是為了使用,C和Unix在其上首次流行的DEC PDP-11提供的自增和自減地址模式。這在歷史上來說是不可能的,因為B被發明的時候還沒有PDP-11。PDP-7有一些“自增”內存單元,使用這種特性,一個間接內存引用通過它們來自增單元。這些特征可能提示Thompson創造了那些自增運算符;他把前綴和後綴一般化。甚至,自增單元沒有被直接用於實現這些運算符,並且這種創新一個更強烈的動機可能是,他發覺++x的翻譯在尺寸上小於x=x+1。
PDP-7上的B編譯器不產生機器指令,而是一個由編譯器輸出組成代碼段地址序列,執行基本運算的解釋模式的threaded代碼[Bell 72]。這些操作——特別對B——典型地運行在一個簡單堆棧機器上。
在PDP-7的Unix系統上,除了B本身只有幾個東西是B寫的,因為這個機器太小和太慢,除了試驗而不能做更多事情;完全用B重寫操作系統和其它應用程序,是看起來不可行的代價高昂的動作。Thompson在某些地方,通過提供一個利用換頁解釋器代碼和數據,允許解釋超過8K字節的程序的“虛擬B”編譯器,來釋放地址空間,但它對通用程序來說太慢以致不實用。盡管如此,一些用B寫的工具還是出現了,包括一個早期版本的,Unix用戶熟悉的可變精度計算器dc[McIlroy 79]。我做的最有雄心壯志的工作,是一個把B翻譯為GE-635機器指令而非threaded 代碼的真正的交叉編譯器。它是一個精巧的絕技:一個用本身語言寫的,生成在一個,在有4k字長用戶地址空間的18位機器上運行的36位大型機代碼,完全的B編譯器。這個項目能實現,僅僅是因為B的簡單性和它的運行時系統。
盡管我們抱有關於實現一個那時,像Fortran, PL/I或Algol 68的主要語言的偶然想法。這樣的項目對我們的顯得絕望的大:需要更簡單和小的工具。所有這些語言都影響我們的工作,但是憑我們自己之力來做這些事情則更有趣。
到1970年時,我們看起來能在Unix項目上,獲得一個新的DEC PDP-11。處理器是DEC遞交的第一批產品,三個月後,磁盤才到達。通過threaded技巧,使B程序在其上運行只需要為運算符重寫代碼段,和一個我用B寫的簡單的匯編器。很快,dc成了在其它操作系統之前,第一個在我們的PDP-11上被測試的有趣的程序。幾乎非常快,但仍需等待磁盤,Thompson用PDP-11匯編語言,重寫了Unix內核和一些基本命令。最早的PDP-11上的Unix把機器上24K內存中的12K給操作系統,一個很小的空間給用戶程序,其余的作為RAM磁盤。這一版本僅是用於測試,而不是實際的工作;這個機器通過枚舉關閉的,knight的不同尺寸象棋板的路程,來標記時間。在磁盤到達後,我們把匯編語言轉換為PDP-11上的方言,和移植一些B程序,很快移植到它上面去。
到1971年時,我們的微型計算機中心開始有了用戶。我們都希望更容易編寫有趣的軟件。使用匯編顯得沉悶,B不管它的性能問題,已經有了一個小的包含有用服務例程的庫,並且被用於越來越多的新程序。這段時期的最著名的成果,是Steve Johnson的yacc分析——生成器[Johnson 79a]的第一個版本。
B的問題
我們第一次使用BCPL然後是B的機器,是按字尋址的,這些語言的單一數據類型,“單元”,能恰當與硬件機器字互相換算。PDP-11的出現暴露了B的語義模型的一些不足。首先,它從BCPL繼承的幾乎未作改變的字符處理機制是笨拙的:使用庫方法把包裝的字符串展開到單個的單元,然後再次包裝,或者訪問或替換單個字符,在一個面向字節的機器上,開始變得笨拙,甚至愚蠢。
其次,盡管最初的PDP-11沒有提供浮點算術運算,制造商承諾將很快提供。浮點運算通過定義特別的運算符,被添加到我們的Multics和GCOS的B編譯器,但是這種機制僅在相應的機器上才可能,單個字長足夠包含一個浮點數;這在16位PDP-11上是不成立的。
最後,B和BCPL模型在處理指針時,暗中會做得更多:語言規則,通過定義一個指針作為字數組的索引,強迫指針被表示為字索引。每個指針引用生成一個運行時,從指針到硬件要求的字節地址的度量轉換。
因為這些理由,看起來需要一個類型模式來處理字符和字節尋址,以及為即將到來的浮點硬件作准備。其它問題,特別是類型安全性和接口檢查,看起來並沒有變得像以後那樣重要。
除了語言本身的問題,B編譯器的threaded代碼技術得到的程序,比他們對應的匯編語言版本慢很多,以至我們對用B紀錄操作系統或它的中心工具的可能性打折扣。
到1971年時,我開始通過添加一個字符類型,並重寫它的編譯器以生成PDP-11機器指令而非threaded代碼,來擴展B語言。因此從B到C的轉換,與創造一個同匯編語言競爭,能產生足夠快和小的程序的編譯器,是同時進行的。我稱這個輕微擴展的語言為NB,表示“新B”(new B)。
C萌芽
NB只存在了很短時間,以至沒有編寫一個它的完整描述。它提供類型int和char,它們的數組,指向它們的指針,用典型風格聲明如下
int i, j;
char c, d;
int iarray[10];
int ipoint[];
char carray[10];
char cpoint[];
數組的語義與在B和BCPL中保持一樣:iarray和carray的聲明產生的單元,被動態初始化為分別指向十個整數和字符序列中的第一個的值。ipointer和cpointer的聲明省略了尺寸,以表明沒有存儲被自動分配。在過程內部,語言對指針的解釋與數組變量是一樣的:一個指針聲明產生一個單元與數組聲明的區別僅在,程序員被期望給它賦值,而不是讓編譯器分配空間和初始化單元。
值存儲在數組的單元中,指針是按字節計算的,對應存儲區的機器地址。因此通過指針間接引用,不意味著比按比例縮放指針從字到字節的偏移,有更多運行時開銷。另一方面,對應數組取下標的機器代碼和指針算術依賴於數組和指針的類型:計算iarray[i]或ipointer+i表示按比例縮放加數i與所指向對象的尺寸。
這些語義表示一個來自B的容易轉換,我在它們上面實驗了幾個月。當我嘗試擴展類型符號,特別是添加結構化(紀錄)類型時,問題變得明顯。結構看起來,應該以一種直接的方式影射到機器的內存,但一個結構包含一個數組,沒有合適的地方隱藏包含數組基地址的指針,也沒有方便的方式安排被初始化的對象。例如,早期unix系統的目錄條目,在C可以被描述為
struct {
int inumber;
char name[14];
};
我希望結構不能僅僅是體現抽象對象的特征,也要描述可能從目錄讀到的位集合。編譯器能在哪裡隱藏指向語義要求的name的指針呢?即使結構被想象的更抽象,指針的空間也能以某種方式隱藏,我如何處理在分配一個,可能是一個結構包含數組再包含結構到任意深度的復雜對象時,完全初始化這些指針的技術問題?
這個解決方案形成了一個,在無類型BCPL和類型化C之間進化鏈中的重要飛躍。它移除了指針在內存的具體化。相反促成數組名出現在表達式中時生成指針。C語言的這個規則一直存在至今,就是數組類型的值當出現在表達式中時,被轉換成指向組成數組的對象中的第一個對象的指針。
這個發明使現存的B代碼能繼續工作,不管下層語言語義的改變。僅有幾個程序為了調整它的起點,把新值賦給數組名——在B和BCPL中是可能的,在C中無意義——都被很容易修改。更重要的是,新語言保持一致性和對數組有效的(如果並非常見)可解釋性,開辟了通往復雜類型結構的道路。
第二個創新,極力明顯地把C與它的前輩們區分開來,那就是更完整的類型結構,尤其是在聲明語法中的表達式,NB提供基本的類型int和char,它們的數組,指向它們的指針,但沒有更進一步的組合。通用化也被要求:給定一個任意類型對象,描述一個包含它們的新對象,從一個函數求得它,或一個指向它的指針,都是可能的。
對每一個此類復合類對象,已經有了一種討論下層對象的方式:索引數組,調用函數,間接引用指針。類比推理導致了一種名字鏡像聲明語法,名字特征出現的表達式語法,因此,
int i, *pi, **ppi;
聲明一個整數,一個指向整數的指針,一個指向指向整數的指針的指針。這些聲明的語法反映i,*pi和**pi用於表達式時,都得到一個整數類型。類似地,
int f(), *f(), (*f)();
聲明一個返回整型值的函數,一個返回整型指針的函數,一個指向返回整型函數的指針;
int *api[10], (*pai)[10];
聲明一個整型指針數組,一指向整型數組的指針。在所有這些情況中,一個變量的聲明類似它在表達式中的用法,它的類型是在聲明中,置於開頭的那個。
C語言采用類型組合模式歸功於Algol 68,盡管它或許沒有以Algol追隨者認可的模式出現。我從Algol獲取的主要概念,是一個基於原子類型的類型結構(包括結構),組合為數組,指針(引用),和函數(過程)。Algol 68關於union和轉換的概念的影響,在後來也表現出來。
創造類型系統之後,我認為這些相關的語法,新語言的編譯器需要一個新名字。NB看起來不夠有自己的特點。我決定延用單字母風格並取名為C,而並沒有肯定答復,關於名字是否表示字母表或是BCPL中的字母順序的問題。
C初生
在語言取名之後,其它改變很快在進行,例如引入||和&&操作符。在BCPL和B中,表達式求值依賴於上下文:if和其它條件語句內,把一個表達式的值與零比較,這些語言對與(&)和或(or)運算符會給與特別解釋。在普通上下文中,它們進行按位運算,但在這個B語句中
if (e1 & e2) ...
編譯器必須對e1求值並且如果它是非零值,對e2求值,並且如果它也是非零,則執行依賴if的語句。在e1和e2內的&和|運算符的求值要求,以此類推。此類真值上下文中的布爾運算符的短路(short-circuit)語義被期望,但是運算符的過度使用,難以解釋和運用。在Alan Snyder的建議下,我提出&&和||運算符,以使這種機制更直接。
它們姗姗來遲的出現,說明了C語言中不合適的優先級規則。一個人在B中這樣寫
if (a==b & c) ...
來檢測是否a和a相等並且c是否非零;在這樣的條件表達式中,&比==的優先級低就好得多。在從B轉變為C時,一個人想在這中表達式中,用&&代替&;為了使這種轉換不那麼痛苦,我們決定保持&運算符與==有相等的優先級,僅僅把&&的優先級與&的做了細微區分。今天,看起來變動&和==的相對優先級會更好,這樣就能簡化一個C通用的慣用法:為了測試一個掩碼值和另一個值,人們必須這樣寫
if ((a&mask) == b) ...
那個內層的圓括弧是需要的,但會被容易忘記。
許多其它改變發生在1972-3年,但是最重要的是引入了預處理器,部分是因為Alan Snyder[Snyder 74]的催促,但也是為了承認在BCPL和PL/I中已存在的文件包含機制。它的原始版本極之簡單,僅提供文件包含和簡單字符串替換:#include和參數化宏#define。之後很快對它進行了擴展,主要是Mike Lesk的工作,後來是John Reiser,合並了宏與參數還有條件編譯。預處理原本是做為語言本身的一個輔助手段。確實,這麼多年來,它甚至未被調用除非在源文件的開始處包含了一個特別信號。這種看法一直持續,解釋了在早期參考手冊中,預處理器語法與語言其它部分的不完整整合,和對它的不精確描述。
可移植性
在1973年早些時候,現代C的基礎部分已經完成。在那年夏天,語言和編譯器已足夠強壯,以允許我們在PDP-11上用C重寫Unix內核。(Thompson已用C的早期版本,作了一個生成系統代碼的簡略嘗試——在結構類型出現之前——1972年時,但是放棄了那次努力。) 也是在這段時期,編譯器被轉向了其它臨近的機器,特別是Honeywell 635和IBM 360/370;因為語言不能獨自存在,現代庫原型已被開發。特別是Lesk寫了一個後來被修改成為C的“標准I/O”例程的“可移植I/O包”[Lesk 72]。在1978年,Brian Kernighan和我出版了C程序設計語言[Kernighan 78]。盡管這本書沒有描述一些添加的,在後來變成通用的特性,它充當了語言標准,直到一個正式的標准在十多年後被采納。盡管我們在本書上關系密切,在工作中有著很明顯的區別:Kernighan編寫幾乎所有的解釋性的內容,我負責參考手冊中包含的附錄,和與Unix系統的接口的那一章。
在1973-1980年間,語言又有了一些發展:類型結構有了unsigned, long, union和枚舉類型,並且結構幾乎成為第一類對象(缺少一個字面值符號)。在它的環境和其它伴隨技術中,也產生了同等重要的發展。用C編寫Unix內核,讓我們對語言的有用性、效率有足夠的信心,我們開始重新編碼系統的應用程序和工具,並且隨後把其中最有趣的東西移到其它平台。像在[Johnson 78a]中描述的那樣,我們發現傳播Unix工具的最困難的問題,並不在C語言和新硬件的接口,而是在適應其它操作系統上的現有軟件。因此Steve Johnson開始了在pcc上的工作,一個可被容易移植到新機器上去的C編譯器[Johnson 78b],在他,Thompson和我開始把Unix系統移到Interdata 8/32計算機的時候。
語言在這時期的改變,特別是1977年左右,很大程度上集中在可移植性和類型安全的考慮,是為了努力處理我們預見和觀察到的,在相當多的代碼移到新的Interdate平台產生的問題。C在那時仍表現很強的無類型根源的跡象。例如,在早期語言手冊或存在的代碼中,指針很少被與整型內存索引區分開來;字符指針的算術特性和無符號整數的相似性,使抵制識別它們的嘗試很難。無符號類型被添加進來使無符號算術有效,不讓它與指針操作混淆在一起。類似地,早期語言容許了整數與指針間的賦值,但這個實踐並未開始得到鼓勵;一個類型轉換的符號(在Algol 68的例子中被稱作“casts”)被發明,以更明顯指示類型轉換。由於PL/I例子的誘惑,早期C沒有強烈綁定結構指針與它們所指向的結構,並且允許程序員用pointer->member而幾乎不用考慮指針的類型;這樣的表達式未受批判地,被當作到指針代表的內存區的引用,成員名字僅表示一個偏移量和一個類型。
盡管K&R第一版描述了,把C的類型結構帶到當前形式的大部分規則,許多用舊式、更松散風格寫的程序也被允許,所以編譯器也要忍受它們。為了鼓勵人們更多注意正式的語言規則,為了發現合法但不可信任的寫法,以及幫助發現分離編譯中,簡單機制沒有察覺的不匹配的接口,Steve Johnson改變他的pcc編譯器產生了lint[Johnson 79b],來掃描一批文件並標記可疑的寫法。
在使用中成長
我們在interdata 8/32的可移植性試驗的成功,很快導致了Tom London和John Reiser在DEC VAX 11/780上的另一次成功。這種機器比Interdata變得更流行,並且Unix和C語言在AT&T公司內部和外面都開始快速傳播。盡管在1970年代中期,Unix已經被用於貝爾系統和公司外的一小群以研究為目的的工業企業、學院和政府機構的各種項目,它的真正成長是在達到可移植性之後才開始。特別是AT&T的計算機系統部門基於其開發和研究小組的System III和System V版本系統,和加州大學伯克利分校繼承自Bell實驗室研究組的BSD系列的出現。
在1980年代,C語言的使用廣泛傳播,並且編譯器出現在幾乎每一種機器體系結構和操作系統;特別是它變成一種個人計算機上流行的編程工具,包括對這些機器的商業軟件制造商和對編程有興趣的終端用戶。在那十年開始時,幾乎每一種編譯器都是基於Johnson的pcc;到1985年,有了許多成型的獨立的編譯器產品。
標准化
到1982年時,形勢很明顯,C需要正式的標准化。K&R第一版最近似一個標准,卻不再反應真實使用中的語言;尤其是它都沒有提及void和enum類型。但是它預示了通往結構的更新的方法,僅在語言對他們的賦值,將他們傳遞給函數和從函數接受他們,及將成員名字與包含它們的結構或union嚴格關聯的支持被發表後。盡管AT&T發布的編譯器包含了這些修改,大部分編譯器供應商未基於pcc的編譯器也加入了他們,對語言仍沒有完整、權威性的描述。
K&R第一版在很多語言細節上也不夠精確,對於pcc這個“參照編譯器”來說,它日益顯得不切實際;K&R甚至沒有很好表達它索要描述的語言,把後續擴展仍到了一邊。最後,C在早期項目中的使用受商業和政府合同支配,它意味著一個認可的正式標准是重要的。因此(在M. D. McIlroy的催促下),ANSI於1983年夏天,在CBEMA的領導下建立了X3J11委員會,目的是產生一個C標准。X3J11在1989年末提出了一個他們的報告[ANSI 89],後來這個標准被ISO接受為ISO/IEC 9899-1990。
一開始,X3J11委員會在語言擴展上采取了謹慎、保守的態度。他們認真對待他們的目標:“完善一個清晰、一致和無二義性的C程序設計語言標准,它規范C通用、現行的定義,以及促進用戶程序在不同C語言環境的可移植性。”[ANSI 89] 委員會意識到,僅僅靠發布一個標准並不會改變這個世界。這超出了我的期望。
X3J11只向語言本身引入了一個真正重要的改變:它使用從C++[Stroustrup 86]借鑒的語法,把形式參數類型添加到函數類型簽名中。用以前的風格,外部函數是這樣聲明的:
double sin();
它僅提及sin是一個返回一個double類型(即是double精度的浮點數)值的函數。在新的風格中,這個更好的聲明
double sin(double);
使參數類型明顯化並鼓勵更好的類型檢查和適當的轉換。即使這個添加,盡管它產生一個明顯更好的語言,也引起了困難。委員會有理由認為,簡單的不合法的舊式風格函數定義和聲明不可行,然而仍然同意新式更好。這種必然的妥協像它本應該的那樣好,盡管允許兩種形式使語言復雜化,並且可移植軟件作者必須應付不符合標准的編譯器。
X3J11也引入了一大堆較小的附加和修改,例如,類型限定詞const和volatile,和稍微有些不同的類型提升規則。然而,標准化過程沒有改變語言的特征。特別是,C標准沒有嘗試在形式上指定語言語義,所以在一些細微的地方上還可以存在爭議;而且,它很好解釋了自最初描述以來,在使用中的改變,並且它對與一個它的基本實現是足夠精確的。
因此核心C語言經過標准化過程幾乎未受損害,並且標准作為一個更好、仔細的條文出現了,而不是一次新發明。更多重要的改變發生在語言的環境中:預處理器和庫。預處理器使用與其余部分語言截然不同的慣例執行宏替換。它和編譯器的交互從未被很好描述,並且X3J11企圖糾正這種情形。這種結果明顯好於K&R第一版中的解釋;除了變得更加易於理解,它提供像標記串聯的操作,以前只在偶爾的實現中可用。
X3J11正確理解了一個完整和仔細的標准C描述,和它在語言本身上的工作一樣重要。C語言本身沒有提供輸入——輸出或任何其它與外界的交互,所以依賴一套標准方法。在出版K&R時,C主要是被當作Unix的系統編程語言;盡管我們提供了可被其它操作系統容易轉換的庫例程例子,Unix的底層支持是被隱含默認的。因此,X3J11委員會花了大量時間來設計和歸檔一套,對所有符合標准的實現都可用的庫例程。
通過標准過程,X3J11委員會的當前活動被限制出版對現存標准進行的解釋。然而,由Rex Jaeschke召集的作為NCEG(C數值擴展小組)的一個非正式組織,被正式接受為附屬組X3J11.1,他們繼續考慮對C的擴展。像這個名字隱含的那樣,這些可能的擴展中的許多,是為了是語言在數值上的使用更合適:例如,邊界動態決定的多維數組,加入IEEE算術處理方式,及使語言在具有向量和其它高級結構特征的機器上更有效。並非所有這些可能的擴展都是數值相關的;他們添加了一個結構字面值符號。
後來者
C和B有一些直接的後代,盡管他們不能與Pascal在產生後代上競爭。很早有發展了一個分支。當Steve Johnson在1972年休假期間訪問滑鐵盧大學時,他帶來了B。它在那兒的Honeywell機器上變得流行。後來產生了Eh和Zed(加拿大人對“B之後是什麼?”的答案)。當Johnson在1973年返回貝爾實驗室時,讓他感到驚慌的是,那個他在加拿大播種的語言,在他回來後在家裡得到了發展;甚至他自己的yacc程序已經由Alan Snyder用C重寫了。
更多近代的C的後代可能包括並發C[Gehani 89]、對象C[Cox 86]、C*[Thinking 90]、尤其是C++[Stroustrup 86]。這個語言也被廣泛用於各種各樣編譯器的中間表示(基本上是當作一種可移植匯編語言),對直接後代C++,以及類似Modula 3[Nelson 91]和Eiffel[Meyer 88]的獨立語言。
批評
C在它那類語言中的兩個最具特征的思想是:數組和指針的關系,聲明語法模擬表達式語法。它們也列入它最為常受批評的特征中,並且也常成為初學者的絆腳石。歷史的偶然和錯誤,在這兩種情形中,更加劇了它的困難。這些其中最重要的是C編譯器對類型錯誤的容忍。上述歷史中應該清楚的是,C由無類型語言進化而來。它不是陡然以一個全新的語言,帶著它本身的規則,出現在它最早期的用戶和開發者的面前;相反我不得不在語言發展的同時,不斷地改變現有程序,並且容忍現有代碼。(後來,ANSI X3J11委員會標准化C面臨同樣的問題。)
在1977年或之後的編譯器,沒有對整數和指針間的賦值,或使用錯誤類型的對象來引用結構成員產生抱怨。盡管K&R第一版中的語言定義,在處理它的類型規則上是相當(盡管不完整)一致的,那本書承認已存在的編譯器不用堅持那些規則。而且,一些為了簡化早期過渡設計的規則,給以後帶來了混亂。例如,函數聲明中的空方括號
int f(a) int a[]; { ... }
是一個活化石,一個NB殘余的聲明指針的方式;在這個特殊的情況下,a在C中被解釋為一個指針。這種表示,部分是應為兼容性而存活下來,部分是它允許程序與於讀者進行交流的理由,向f傳遞一個數組生成的指針,而不是到一個整型的引用的企圖。不幸地是,它所起到的迷惑的作用和它帶來的提醒一樣多。
在K&RC中,為函數調用提供正確類型的參數,是程序員的責任,而現有的編譯器不檢查類型約定。原始語言沒有在函數類型簽名包括參數類型,是一個重大,和真正需要X3J11委員會做出大膽和最痛苦革新的缺陷。早期設計在我對技術問題的預防中被解釋了,尤其是分離編譯原文件交叉檢查,和我在對從無類型語言改進到類型語言的含義的不完整理解。在上面提及的lint程序,嘗試緩解這個問題:作為lint的功能之一,lint通過掃描一系列源文件,比較調用時的函數參數類型和在他們的中的定義,檢查整個程序的一致性。
對於已察覺到的語言的復雜性,產生了一些意外的語法。間接引用運算符,在C中被寫作*,在語法上是一個前綴運算符,正象在BCPL和B中一樣。這在簡單的表達式中很有效,但是在更復雜的情況,需要括號來指示分析。例如,為了區分對函數返回值的間接引用與通過指針調用函數,分別寫作*fp()和(*pf)()。表達式使用的風格貫徹到聲明,所以這些名字可以聲明為
int *fp();
int (*pf)();
在更過分但仍現實的例子中,事情變得更糟糕:
int *(*pfp)();
是一個到返回一個整型指針的函數的指針。出現了兩個結果。最重要的是,C有一個相當豐富的類型描述(比如說跟Pascal比較)集合。比如在C——Algol 68描述對象,語言中聲明與表達式一樣,很難理解,只是因為對象它們本身很復雜。第二個結果歸因於語法細節。聲明在C中,應該用一個從內到外的風格來閱讀,可能難以領會[Anderson 80]。Sethi[Sethi 81]發現,如果間接引用運算符被當作一個後綴而不是前綴運算符,許多嵌套的聲明和表達式會更簡單,但這時改變已經太晚了。
不管它的困難,我認為C聲明的方式是合理的,並且覺得它很合適;它是一個有用的一致性原則。
C的其它特征,它對數組的處理,在實際中更令人疑惑,盡管它也有實在的優點。盡管指針和數組間的關系並不通常,它還是能被學會的。而且,語言在描述重要概念方面,表現了相當強大的功能,例如,僅僅使用幾個基本規則和慣例,向量長度在運行時可變。特別是,字符串處理被采用與其它數組一樣的機制,附加上null字符終結一個串的慣例。把C的那個方法與兩個同時期的語言Algol 68和Pascal[Jensen 74]比較,是有趣的。數組在Algol 68中有固定邊界,或可變的:很多機制被要求,存在語言定義和編譯器中,為了提供靈活數組(並非所有編譯器都實現了它們)。原始Pascal只有固定尺寸數組和串,這已被證明是受限制的[Kernighan 81]。後來,它是部分固定,盡管最終的語言沒有廣泛運用。
C把串當作在管理上用標記終結的字符數組。除了用串字面值初始化的特殊規則,串的語義完全包含於更通常的控制數組的規則,結果是語言比一個把串當作獨立數據類型的語言,更易於描述和翻譯。它的方式產生了一些開銷:某些串操作比在其它設計裡需要更多開銷,因為應用代碼或庫例程有時必須查找串尾,因為幾乎沒有可用的內置運算,也因為串的存儲邊界管理極大轉向了用戶。而且,C的串處理方法很有效。
另一方面,C對數組的處理,通常(不僅指串)不幸在優化和以後的擴展有隱含意義。指針在C程序裡流行,不論是顯式聲明或由數組形成,意味優化器必須謹慎,並必須使用小心的數據流向技巧才能得到滿意的結果。復雜的編譯器能理解大多數指針可能改變,但一些重要對於分析仍然顯得困難。例如,帶有從數組繼承而來的指針參數的函數,在向量機器上很難編譯生成有效代碼,因為確定一個參數指針,沒有重迭另一個參數指向的數據幾乎不可能,或者外部可訪問。更重要的是,C的定義如此明確描述了數組的語義,以致改變或擴展數組為更基本對象,以及允許把它們當作整體操作,變得不能適用當前語言。甚至允許聲明和使用動態決定尺寸的多維數組的擴展,也不是完全直接[MacDonald 89] [Ritchie 90],盡管它們使用C中編寫數值庫更容易。因此,C通過一個統一和簡單的機制,包含了實踐中串和數組的最重要使用,但是把問題留給了高效率實現和擴展。
除了上面討論的,語言和其描述中存在許多更小的不適當地方。也有常見的批評可以提及,但不是逐條表明。其中首要的是語言和它的一般要求的環境,沒有為編寫很大的系統提供幫助。命名結構只提供了兩個主要的級別:“external”(到處可見)和“internal”(在單個過程內)。可見性的一個中間級別(在單個數據和過程文件內)與語言的關系很微弱。所以,沒有對模塊化的直接支持,項目設計師不得不使用自己的約定。
類似,C本身兩種存儲期:“automatic”對象當控制流程存在或低於過程時存在,“static”存在於程序的全部執行期。動態分配僅由一個庫例程提供,並且管理它們的負擔落在程序員一方。C反對自動垃圾回收。
因此成功?
C的成功遠超出了早期的期望。哪些品質促進它得到廣泛使用呢?
Unix本身的成功無疑是最重要的因素;它讓這個語言可以被幾十萬人使用。相反,C在Unix中的使用和隨之發生的到各種各樣機器的可移植性,自然對系統的成功非常重要。但是,語言進入其它環境,提供了更重要的價值。
盡管某些方面對初學者甚至偶爾對老手都是神秘的,C不失為一個簡單和小的語言,可被簡單和小的編譯器翻譯。它的類型和操作充分依據於真實機器,讓人們容易理解機器如何工作,並學會生成時間和空間效率程序的慣用法也不困難。同時,語言充分抽象於機器細節,程序可移植性也可以達到。
同樣重要的是,C和它的主要庫支持,總是保證能存在一個真實環境中。它不是被設計用來孤立驗證某一點,或作為一個例子,而是作為一個用來寫有用程序的工具;它總是意味著同一個大型操作系統交互,並用來創建更大工具。一個節儉、實際的方法影響了進入C中的事物:它覆蓋了多數程序員的基本需要,但不嘗試提供太多東西。
最後,不管自它第一次不正式、不完整描述發布以來經受的變化,真實的C語言,像幾百萬使用許多不同編譯器的用戶見到的一樣,與那些類似流行的語言,比如Pascal和Fortran比較,保持著顯著的穩定和一致性。存在許多不同的C的方言——最顯著的是那些由更古老K&R和更新的標准C的描述——但基本上,C比其它語言保持著更自由的屬性擴展。或許最重要的擴展,是用於處理某些Intel處理器的怪異之處的“far”和“near”指針限定符。盡管可移植性不是C的原始設計中的一個主要目標,它在從最小的個人計算機到最大的超級計算機的不同機器上,編寫程序、甚至操作系統方面取得了成功。
C詭異重重、充滿缺陷,卻取得了極大成功。盡管歷史的機緣的卻起了幫助,它顯然符合系統實現語言的需要,並足夠有效以取代匯編語言,仍然足夠抽象和在廣泛不同環境中流暢描述算法和交互。
致謝
值得簡要總結在今天的C的發展中,那些直接貢獻者們在語言發展史中的角色。Ken Thompson在1969-70年創造了B;它直接繼承自Martin Richards的BCPL。Dennis Ritchie在1971-73年把B轉化為C,保持B的大部分語法,但添加了類型和許多其它改變,並編寫了第一個編譯器。Ritchie, Alan Snyder, Steven C. Johnson, Michael Lesk和Thompson在1972-1977年間貢獻了語言設計思想,Johnson的可移植編譯器被廣泛使用。在這段時期內,庫例程集合得到相當發展,感謝這些人們和貝爾實驗室其它許多人。在1978年,Brian Kernighan和Ritchie寫作了多年被當作語言定義的那本書。在1983年初,ANSI X3J11委員會標准化了C語言。特別值得注意的是委員會官員Jim Brodie, Tom Plum和P. J. Plauger,和後續草案標准編輯Larry Rosler和Dave Prosser的努力。
我感謝Brian Kernighan, Doug McIlroy, Dave Prosser, Peter Nelson, Rob Pike, Ken Thompson和編程語言歷史會議負責人員對准備這篇文章的建議。
參考
[ANSI 89]
American National Standards Institute, American National Standard for Information Systems—Programming Language C, X3.159-1989.
[Anderson 80]
B. Anderson, `Type syntax in the language C: an object lesson in syntactic innovation,' SIGPLAN Notices 15 (3), March, 1980, pp. 21-27.
[Bell 72]
J. R. Bell, `Threaded Code,' C. ACM 16 (6), pp. 370-372.
[Canaday 69]
R. H. Canaday and D. M. Ritchie, `Bell Laboratories BCPL,' AT&T Bell Laboratories internal memorandum, May, 1969.
[Corbato 62]
F. J. Corbato, M. Merwin-Dagget, R. C. Daley, `An Experimental Time-sharing System,' AFIPS Conf. Proc. SJCC, 1962, pp. 335-344.
[Cox 86]
B. J. Cox and A. J. Novobilski, Object-Oriented Programming: An Evolutionary Approach, Addison-Wesley: Reading, Mass., 1986. Second edition, 1991.
[Gehani 89]
N. H. Gehani and W. D. Roome, Concurrent C, Silicon Press: Summit, NJ, 1989.
[Jensen 74]
K. Jensen and N. Wirth, Pascal User Manual and Report, Springer-Verlag: New York, Heidelberg, Berlin. Second Edition, 1974.
[Johnson 73]
S. C. Johnson and B. W. Kernighan, `The Programming Language B,' Comp. Sci. Tech. Report #8, AT&T Bell Laboratories (January 1973).
[Johnson 78a]
S. C. Johnson and D. M. Ritchie, `Portability of C Programs and the UNIX System,' Bell Sys. Tech. J. 57 (6) (part 2), July-Aug, 1978.
[Johnson 78b]
S. C. Johnson, `A Portable Compiler: Theory and Practice,' Proc. 5th ACM POPL Symposium (January 1978).
[Johnson 79a]
S. C. Johnson, `Yet another compiler-compiler,' in Unix Programmer's Manual, Seventh Edition, Vol. 2A, M. D. McIlroy and B. W. Kernighan, eds. AT&T Bell Laboratories: Murray Hill, NJ, 1979.
[Johnson 79b]
S. C. Johnson, `Lint, a Program Checker,' in Unix Programmer's Manual, Seventh Edition, Vol. 2B, M. D. McIlroy and B. W. Kernighan, eds. AT&T Bell Laboratories: Murray Hill, NJ, 1979.
[Kernighan 78]
B. W. Kernighan and D. M. Ritchie, The C Programming Language, Prentice-Hall: Englewood Cliffs, NJ, 1978. Second edition, 1988.
[Kernighan 81]
B. W. Kernighan, `Why Pascal is not my favorite programming language,' Comp. Sci. Tech. Rep. #100, AT&T Bell Laboratories, 1981.
[Lesk 73]
M. E. Lesk, `A Portable I/O Package,' AT&T Bell Laboratories internal memorandum ca. 1973.
[MacDonald 89]
T. MacDonald, `Arrays of variable length,' J. C Lang. Trans 1 (3), Dec. 1989, pp. 215-233.
[McClure 65]
R. M. McClure, `TMG—A Syntax Directed Compiler,' Proc. 20th ACM National Conf. (1965), pp. 262-274.
[McIlroy 60]
M. D. McIlroy, `Macro Instruction Extensions of Compiler Languages,' C. ACM 3 (4), pp. 214-220.
[McIlroy 79]
M. D. McIlroy and B. W. Kernighan, eds, Unix Programmer's Manual, Seventh Edition, Vol. I, AT&T Bell Laboratories: Murray Hill, NJ, 1979.
[Meyer 88]
B. Meyer, Object-oriented Software Construction, Prentice-Hall: Englewood Cliffs, NJ, 1988.
[Nelson 91]
G. Nelson, Systems Programming with Modula-3, Prentice-Hall: Englewood Cliffs, NJ, 1991.
[Organick 75]
E. I. Organick, The Multics System: An Examination of its Structure, MIT Press: Cambridge, Mass., 1975.
[Richards 67]
M. Richards, `The BCPL Reference Manual,' MIT Project MAC Memorandum M-352, July 1967.
[Richards 79]
M. Richards and C. Whitbey-Strevens, BCPL: The Language and its Compiler, Cambridge Univ. Press: Cambridge, 1979.
[Ritchie 78]
D. M. Ritchie, `UNIX: A Retrospective,' Bell Sys. Tech. J. 57 (6) (part 2), July-Aug, 1978.
[Ritchie 84]
D. M. Ritchie, `The Evolution of the UNIX Time-sharing System,' AT&T Bell Labs. Tech. J. 63 (8) (part 2), Oct. 1984.
[Ritchie 90]
D. M. Ritchie, `Variable-size arrays in C,' J. C Lang. Trans. 2 (2), Sept. 1990, pp. 81-86.
[Sethi 81]
R. Sethi, `Uniform syntax for type expressions and declarators,' Softw. Prac. and Exp. 11 (6), June 1981, pp. 623-628.
[Snyder 74]
A. Snyder, A Portable Compiler for the Language C, MIT: Cambridge, Mass., 1974.
[Stoy 72]
J. E. Stoy and C. Strachey, `OS6—An experimental operating system for a small computer. Part I: General principles and structure,' Comp J. 15, (Aug. 1972), pp. 117-124.
[Stroustrup 86]
B. Stroustrup, The C++ Programming Language, Addison-Wesley: Reading, Mass., 1986. Second edition, 1991.
[Thacker 79]
C. P. Thacker, E. M. McCreight, B. W. Lampson, R. F. Sproull, D. R. Boggs, `Alto: A Personal Computer,' in Computer Structures: Principles and Examples, D. Sieworek, C. G. Bell, A. Newell, McGraw-Hill: New York, 1982.
[Thinking 90]
C* Programming Guide, Thinking Machines Corp.: Cambridge Mass., 1990.
[Thompson 69]
K. Thompson, `Bon—an Interactive Language,' undated AT&T Bell Laboratories internal memorandum (ca. 1969).
[Wijngaarden 75]
A. van Wijngaarden, B. J. Mailloux, J. E. Peck, C. H. Koster, M. Sintzoff, C. Lindsey, L. G. Meertens, R. G. Fisker, `Revised report on the algorithmic language Algol 68,' Acta Informatica 5, pp. 1-236.
Copyright ? 2003 Lucent Technologies Inc. All rights reserved.
(This Chinese translation isn't confirmed by the author, and it isn't for profits.)