據預測,市場對語音控制應用設備的需求將急劇增長,其推動力來自電話機市場。電話機將更多地采用語音命令進行控制。其他應用領域包括玩具和手持設備如計算器、語音控制的安全系統、家用電器及車載設備(立體聲、視窗、環境控制、車燈和導航控制)。本文從可復用和優化芯片空間的角度出發介紹語音識別芯片結構設計的種種考慮,其思路有利於開發一系列其它語音識別芯片。
新加坡Columns公司在便攜式語音控制產品應用中起步較早,其中一個產品是執行歐元與其他歐洲貨幣之間進行兌換的“語音控制歐洲貨幣兌換器”。歐元兌換器的設計要求包括:1. 功率小,電池壽命至少為1年;2. 價格低廉,產品零售價不超過9美元;3.具有很強的靈活性,能用多種語言精確地識別並合成與說話人相關的語音;4. 整個語音控制核產品應具備可復用的特性。
本文介紹利用Frontier Design公司設計工具來開發歐元兌換器ASIC產品 的全過程。在ASIC中實現復雜DSP算法的要求通常極為苛刻,但采用Frontier的結構合成工具A|RT Designer工具能迅速優化RTL描述,該工具還允許自由選擇備用結構以優化應用設計。
通過應用基於C語言的設計流,能在結構設計階段對新特性進行設計和硬件優化,這能降低50%的硅片面積,通過加快 C語言原型硬件的設計,可以進一步擴展設計的性能以滿足用戶對產品規格的嚴格要求。
算法研究
歐元兌換器的效率在一定程度上取決於語音命令與存儲數據庫的比較以及執行命令的能力。開發出滿足最終產品要求的算法對設計的成功至關重要,因為沒有人希望看到語音控制設備不能始終如一地識別命令,人們需要算法自始至終達到98%以上的識別精度。因此,目前面臨的難題包括檢測並清除背景噪聲、區分真實的命令字和其他噪聲(呼吸聲、微小靜電干擾聲及麥克風聲響)、確定命令字的起始和終止以及將輸入與存儲的“聲紋譜”數據庫及隨後的命令字識別(圖1)進行比較。
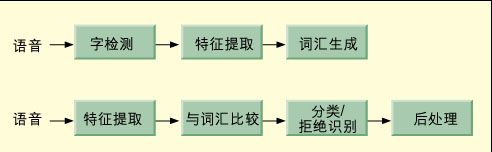
以下幾種先進的計算密集DSP算法適用於解決上述問題:1. Mel頻率聲譜(cepstral)系數(MFCC)算法,MFCC算法由快速傅立葉變換(FFT)功能譜、Mel定標和log ii構成;2. 反離散余弦變換(iDCT);3. 應用多重估計和選擇算法連續識別並估計背景聲音和語音噪聲的連續噪聲電平估計程序;4. 在命令字有效期間及其附近對聲音能級實施詳盡分析的不精確和精確命令字邊界檢測算法;5. 對一系列不等長度的向量進行比較並在這些向量間比較持續時間變化的動態時間扭曲算法(dynamic time warp)。
該算法用浮點C語言編程,為了調整並優化參數,浮點C代碼的編譯和仿真速度要足夠快以檢驗算法的性能。最後,C語言代碼必須能在傳統的PC機上運行,語音識別和合成算法的性能可在實際環境中進行測試。最終的語音識別算法在450MHz奔騰機上測試,當用該公司的內部語音記錄庫進行測試時,可得到99%的識別精度。
浮點算法向定點算法轉換
芯片實現需要將浮點算法轉換為定點算法,要保證動態范圍和精度並防止轉換後超越動態極限。常規定點操作數的非優化范圍可能導致操作數繞回(wrap around, 如(max+1)得到(min)),並引發嚴重的削波和誤碼。定點的精確度同等重要,特別是在重復的信號處理運算中。當精確度不夠時,重復的信號處理算法將導致故障傳播和錯誤累積,最終信號可能逐漸退化成白噪聲,這對於語音控制產品來說無疑是災難性的錯誤。
Frontier工具擁有一個稱為A|RT庫的C++類庫,它是分析C代碼定點性能的工具。該類庫支持多種定點數據類型,對多重溢出行為(如飽和和繞回)提供位真建模(bit-true modeling),並提供截斷和捨入零等多重量化模型。原始的32位浮點語音識別算法支持數據以8 KHz輸入,其典型信號帶寬為32位,內存容量要求為幾千字節,典型語音用戶接口的輸出以每秒幾字節的速率測量。
代碼合並實現最終產品
分析表明,全局數據類型(globaldata-type)和數組只需16位(1個符號位,10個動態位,5個精度位)就足以保持算法的精度,而不會產生噪聲。但是,高度重復性的FFT子程序需要8個動態位、7個精度位以及1個符號位。通常這種分析可用全局使用的19位字寬滿足任何操作的動態位和精度位的最大要求。由於A|RT庫允許字寬動態改變,而全局數據類型定義了1個符號位、10個動態位和5個精度位,FFT的MAC結果分配了1個符號位、8個動態位和5個精度位,因此設計的字寬(包括總線)保持為16位。這樣可大大節省硅片面積。
完成定點C算法轉換後,就可用常規C++編譯器編譯C代碼,並在PC機上運行(也可在HP或SUN機器上運行)。所有信號的位真定義(bit-truedefinition)保證了硬件映射的正確索引以及到其他數字部件如HDL編譯器和仿真器的直接接口。將定點識別代碼與歐元兌換器應用程序的C代碼合並,就可得到完整的可執行最終代碼。
系統設計的考慮
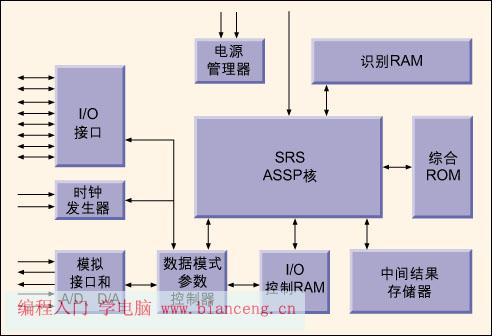
為了達到成本目標,單片SoC解決方案是唯一可行的方案。SoC必須將如下資源集成至不超過25,000門的芯片上:1.語音識別與合成(SRS)識別核;2.語音識別與合成(SRS)程序和歐元兌換器代碼(最大30KB);3.語音合成實例(最大30KB);4.用於存儲聲紋(voiceprint)並用作中間結果存儲器的RAM(最大30K字節);5.AD/DA轉換器;6.麥克風接口;7.揚聲器接口。
功耗也是要考慮的重要問題,電池壽命至少應為1年半。要滿足這些苛刻的功率要求,系統必須具備省電模式、在RAM中存儲聲紋、處理器具有較低的時鐘頻率以及高效率的音頻放大器。
SRS處理器結構
要給定所必需的處理和低功耗約束條件,選擇目標時鐘頻率是首要任務。根據對初始功耗和處理計算的估計,我們認為2到4MHz時鐘頻率足以滿足要求。選擇3.579MHz是因為該頻率是NTSC視頻系統的基礎,而石英成本低廉。
該算法需要檢測並去除背景噪聲。為了從奔騰機的450MHz時鐘得到3.5MHz時鐘,並保持芯片核門數小於25,000,SRS要采用專用結構。
設計專用處理器費時費力,要用HDL語言重寫算法以獲得最佳方案。A|RTDesigner工具綜合了基於控制器的結構,並直接以高效能的C語言算法為基礎。設計工程師通過分析和優化,然後轉化為Verilog或VHDL代碼。
設計工程師使用A|RTDesigner工具為語音識別算法合成適當的結構,之後進行RTL描述。該工具分配必需的數據通路資源(乘法器、加法器、ALU、I/O、RAM、ROM等),為這些資源分配算術運算,並對運算過程進行調度。同時將自動生成一個控制器、微代碼(用來控制資源分配和調度)及寄存器、多路轉換器和總線。
將SRS算法映射到硬件結構的關鍵參數是:以3.5MHz目標時鐘頻率運行完整的SRS代碼,且不超過最大25,000門的約束條件。使用A|RTDesigner的“負載視圖(loadview)”,設計工程師識別出代表性能瓶頸的幾個多周期運算(multiplecycleoperation)。視圖上出現瓶頸的位置將顯示相關C代碼,設計工程師因而能識別產生瓶頸的原因並試驗備選解決方案。
最明顯的瓶頸是MEL運算中的密集FFT計算,它占據了實時處理周期80%的時間。通過增加一個二級加法器和專用地址計算單元ACU(addresscalculationunit),FFT就能優化到只占原始運算周期的10%。這雖然增加了硬件設備,但付出的代價只是4,000個門,正好在硬件預算以內。即便如此改進,所用周期的總數目實在太高,難以達到3.5MHz的時鐘頻率。
進一步分析表明,可以改進對數函數的計算。當在RISC DSP (NSC CR16B)上運行C語言算法時,該運算占用大約1,000個周期,約為實時運算需求的15%。添加專用的特定應用單元ASU (application specific unit)進一步將這些功能的循環周期降至3個周期,而只增加200個門。上述結構上的改變使最小時鐘頻率為1.5MHz,少於目標頻率的一半。
對門電路數目和語音識別核功耗的優化可以降低寄存器觸發器的數目。觸發器的開銷很大(每個需要10個門電路),並消耗很大的功率。A|RT Designer的“壽命視圖(life-time view)”用來分析組成每個變量壽命的周期數目及變量被使用的頻率。通過在RAM中存儲不常使用但長期有效的變量,即可降低寄存器的總數,進一步減小所需的硅片面積和功率。該措施節約了50%的寄存器門電路,同時為運算周期預算留下充足的開銷空間。
RAM壓縮的實現
在設計初期,我們已經明確30KB的RAM空間太緊張。參考SRS C代碼的每個聲紋譜(約為1秒鐘的語音)字占用大約1-2KB,相當於30條命令,這樣幾乎沒給中間結果SRAM留下任何空間。由於30KB的RAM占用了硅片相當大的面積,因此在硅片預算中無法添加更多的RAM(圖2)。
整個芯片使用標准的0.35μm CMOS工藝制造,解決RAM空間問題的唯一解決方案是采用某些形式的語音壓縮。
聲紋數據可用兩種方法壓縮:無損壓縮或有損壓縮。目前存在幾種以現有的標准C代碼源程序為基礎,用C語言實現的無損壓縮方法。聲紋采樣數據可用作參考,最佳的無損算法可得到30%的壓縮率。采用有損壓縮,還能再壓縮20%,並且不明顯降低識別質量。有損壓縮完全可以縮放,從而獲得依賴於實際聲紋長度或詞匯表大小的可變壓縮率。由此得到的C代碼算法共500行,並對聲紋得到50%的壓縮率。下一步就可以集成語音壓縮和語音識別IP塊了。
然後只需將這500行代碼與10,000行SRS代碼合並,得到一個新功能子程序,在存儲聲紋或讀取RAM中的聲紋時調用。但程序的計算量相當大,初始計算後約需要150萬個時鐘周期,這與SRS處理所需的時間相當。幸運地是,有效時鐘頻率留出的近2.5 MHz能解決這個進程問題,而無需進一步優化。此壓縮方案將RAM需求降低到20-25KB,留出至少5KB用於處理器的中間結果存儲器之用。
揚聲器接口的實現
單電池電源管理偏置網絡、數模轉換器(DAC)和模擬放大器的要占用較大的芯片面積,而直接用C語言實現脈寬調制(PWM)揚聲器驅動程序可以解決這個問題。
揚聲器如何發音?C代碼可使用該公司的A|RT Builder “C-到-HDL”轉換工具直接轉換為VHDL。然後使用Exemplar的Leonardo Spectrum加以合成,並映射到Xilinx的Virtex FPGA,采用Xilinx FPGA主板,就能將揚聲器同2個數字輸出直接相連,啟動開關,即可測聽音效了。
RTL描述的生成
當工程人員對語音識別SoC的性能和結構感到滿意時,就可使用A|RT Designer工具自動生成用於最終硅片的RTL VHDL語言描述。該工具自動為控制器生成RTL代碼及微代碼、RAM、ROM和數據通路功能。另外A|RT Designer工具在設計流的每個階段自動生成測試基准,因此原始的浮點算法仿真可與浮點C和HDL方案中的仿真媲美。VHDL仿真與原始的浮點C代碼嚴格對應,這意味著SoC具有與浮點算法相同的精度。
最終結構
SRS ASIC所需的全部功能都集成在單芯片上(圖2)。另外所有為該SoC開發的IP都可復用。SRS算法目前應用於CR16B RISC核的DECT電話語音識別器上。數據壓縮功能也可復用,以進一步增強專用可變位率ADPCM音頻壓縮代碼(VADPCM)。VADPCM同樣可用於SRS核,在不利用模擬元件的條件下,PWM算法及方案仍然能實現高品質的音頻輸出。SRS實現方案本身在下一代產品中還可以修改。