最近項目中要處理文本,因此就用了gun的正則表達式,它是posix風格的..我們一般使用的都是perl風格的,所以一開始使用可能會有一些不習慣.詳細的區別可以在wiki上看到:
http://en.wikipedia.org/wiki/Regular_expression
頭文件是regex.h可以在裡面看到他所提供的接口.這裡主要是3個函數和一個結構體:
引用
int regcomp (regex_t *compiled, const char *pattern, int cflags)
int regexec (regex_t *compiled, char *string, size_t nmatch, regmatch_t matchptr [], int eflags)
void regfree (regex_t *compiled)
typedef struct {
regoff_t rm_so;
regoff_t rm_eo;
} regmatch_t;
regcomp會將參數pattern編譯為compiled,也就是講字符串編譯為正則表達式.
而參數cflags可以是下面1種或者幾種的組合:
REG_EXTENDED
使用 擴展的 posix Regular Expressions.
REG_ICASE
忽略大小寫
REG_NOSUB
不存儲匹配結果,只返回是否匹配成功.
REG_NEWLINE
可以匹配換行.
regexec執行匹配.compiled為剛才編譯好的正則表達式,string為將要匹配的字符串,nmatch為後面的結構體數組的長度 (regmatch_t).matchptr為regmatch_t的一個數組(也就是存儲著像perl裡面的$0,$1這些的位置,也就是).而 eflag參數則可以是下面中的1個或多個.
REG_NOTBOL
會講^作為一個一般字符來匹配,而不是一行的開始
REG_NOTEOL
會講$作為一個一般字符來匹配,而不是一行的結束
regfree每次用完之後需要釋放這個正則表達式.compiled為需要釋放的正則表達式.
regmatch_t 中的rm_so為匹配字符的開始位置,rm_eo為結束位置.
說了這麼多,其實使用很簡單的:
引用
POSIX Regexp Compilation: Using regcomp to prepare to match.
Flags for POSIX Regexps: Syntax variations for regcomp.
Matching POSIX Regexps: Using regexec to match the compiled pattern that you get from regcomp.
Regexp Subexpressions: Finding which parts of the string were matched.
Subexpression Complications: Find points of which parts were matched.
Regexp Cleanup: Freeing storage; reporting errors.
然後看個例子吧:
C代碼
#include <stdio.h>
#include <regex.h>
#include <string>
int main(int argc, char** argv)
{
char* pattern="abc([0-9]+)";
int z=0;
char *s_tmp="Abc1234";
regex_t reg;
regmatch_t pm[3];
z = regcomp( & reg, pattern, REG_EXTENDED|REG_ICASE);
z = regexec( & reg, s_tmp, 3, pm, 0);
if (z != 0) {
//也就是不匹配
return 2;
}
std::string s=s_tmp;
std::string result0=s.substr(pm[0].rm_so, pm[0].rm_eo-pm[0].rm_so);
std::string result1=s.substr(pm[1].rm_so, pm[1].rm_eo-pm[1].rm_so);
printf("[%s]\n", result0.c_str());
printf("[%s]\n", result1.c_str());
regfree( & reg);
return 0;
}
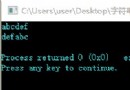
很簡單一個例子, 將會打印出Abc1234gh和1234.這裡因為有括號,因此pm[0]存儲著第0組的位置,pm[1]存儲第1組的位置.
也談談自己的體會吧,那就是真不好用,不管是提供的接口還是posix風格的正則.而且據說是效率比較低下.因此如果有機會下次准備試試boost得正則或者pcre了..