許多 C++ 愛好者已經對我最近的專欄中滲入了太多關於C#的內容表示關注。我承認這一點!我唯一的辯解是:由於 Microsoft® .NET Framework 已經獲得廣泛的認同,給我發送關於C#問題的讀者越來越多,同時因為C# 和 C++ 如此類似,所以我就回答了一部分他們的問題。這不是我有意疏遠 C++ 愛好者——上帝知道,我就是他們中的一員啊!不管怎樣,為了突出重點,從這個月開始的 C++ 專欄將更多地專注於 C++ 的內容,包括托管擴展以及 MFC 這樣的傳統內容。因此提出你的 C++ 問題吧!我特別鼓勵你提出關於托管 C++ 的問題。你使用它的時候有些什麼體會?
在你 2004 年 3 月 的專欄中,你通過重定義 WM_USER+1 實現 了 CMyOpenDlg 的初始化。我認為在通常意義上你誤用了 WM_USER 的范圍(它是保留給所有 RegisterClass 使用者的),此外還錯在 WM_USER+1 已經 是一個預定義的對話框消息 DM_SETDEFID。你不應該再對這個消息用不同的值了吧?
Jeff Partch
你說得完全正確!WM_USER 是為所有實現窗口類的人保留的——無論是你,還是友好的 Redmondtonians(譯注:Microsoft), 仰或是 Gleepoid 行星上的叛逆者。Figure 1 展示了正式的 Windows 消息值的細目分類,對此每個人都應該至少每十年復習一次。WM_USER 到 0x7FFF 是為私有窗口類保留的。你可以將這個范圍 認為是在特定的窗體類中有意義的專用消息。舉個例子,狀態欄控件的 SB_SETTEXTA 使用 WM_USER+1。同時正如你所指出的一樣, 對話框的 DM_GETDEFID 和 DM_SETDEFID 使用 WM_USER+0 和 WM_USER+1。我在 2004 年 3 月的專欄中使用 WM_USER+1 是與 DM_GETDEFID 相沖突的。
想要定義其自己消息的應用程序應該使用 WM_APP。WM_APP 是確保不會與系統(WM_CREATE 等等)或類/特定控件消息如 DM_GETDEFID 相沖突的。Windows 定義 的 WM_APP 如下:
#if (WINVER >= 0x0400)
#define WM_APP 0x8000
#endif
正如每個 Windows 極客(Geek)所知道的那樣,WINVER 0x0400 是指 Windows 95、Windows 98 和 Windows NT。所以 WM_APP 的使用還不到十年,這解釋了為什麼我沒注意到它——在 2005 年之前,我不應該對下一個十年的消息范圍妄加評論!
但是我真的要為 CMyOpenDlg 使用 WM_APP 嗎?CMyOpenDlg 介於 Windows 和應用程序之間。我把它寫成一個擴展 ,以便其他程序員可以在其應用程序中使用。如果某個程序員已經在使用 WM_APP,並且是用 CMyOpenDlg,那麼是否有沖突呢?在文件打開對話情況中這是不太可能的——但如果我正在寫一個自定義控件 ,比如工具欄或進度條並需要定義自己的消息時該怎麼辦呢?我可以讓他們基於 WM_APP 來避免和基本控件沖突(但是這時存在與應用程序沖突的風險)或者我可以選一個 消息號如:WM_USER+400,它遠遠超出 Windows 控件消息范圍。不幸的是,這裡沒有正確的答案。這是一個自 Windows 發布以來就一直 折磨著控件和類庫設計者的問題。簡直就沒有一個十全十美方法來劃分消息空間而保證絕不導致沖突。你每次都必須根據經驗來采取決定。對於 CMyOpenDialog,我 將選擇 WM_USER+10 這樣的消息,它不會與 DM_XXX 消息沖突。用注冊消息可能又太誇張了。
說到注冊消息,WM_APP 取值范圍和已注冊消息取值范圍(0xC000 - 0xFFFF)有什麼不同,什麼時候應該選用其中一個而不是另一個? 如果你只是在對自己說——就是,如果你打算僅僅將發送消息到自己應用程序的窗口中,你可以使用 WM_APP 取值范圍。注冊消 息則是全局消息,用於發送到別的程序員寫的其它應用程序。舉個例子,如果你正在寫一個協作-管理應用程序,它自己能通過發送一個特定的消息來 確定具有相似意向的程序,這時你應該使用注冊消息:
UINT WM_SAYHELLO = RegisterWindowMessage(_T("WmSayHello"));
這時其它協作應用程序可以用這個特定的名稱“WmSayHello”注冊並獲得相同的值,於是他們都可以互相通信。每個 Windows 會話實際的 WM_SAYHELLO 值 將會各不相同,但在某一個對話中,注冊它的所有應用程序將具有相同的值。當然,該值將總在 0xC000 - 0xFFFF 范圍之內。糟了——MSDN® 雜志有最精明的讀者!
我正用托管 C++ 寫一個應用程序並且碰到一個關於字符串 文字量的問題。我知道我能用_T("sample string") 或 S"Sample String" 創建一個字符串。我也知道 S 字符串文字量更有效率,但好象很少有人知道它為什麼有效以及效率高在哪。兩種類型的字符串 有何差別?托管字符串文字量確切含義是什麼,以及為什麼它更好?
Randy Goodwin
理解托管字符串文字量和普通C/C++ 字符串文字量之間差別的最好方法是用它們寫相同的代碼並考察其編譯結果。我寫了一個簡單的托管 C++ 程序,StrLit.cpp,這個程序用C++和.NET風格創建了一些 String 文字量,代碼如 Figure 2 所示。Figure 3 和 Figure 4 展示了用 ILDASM 反匯編的 Microsoft 中間語言(MSIL)代碼。正如你可能知道的許多事情一樣,其首要差別就是當你使用 C++ 文字量時,編譯器產生一個對相應 String 構造函數的調用:// String* c2 = new String(_T("This is a TCHAR string"));
ldsflda valuetype $ArrayType$0x11197cc2
modopt([Microsoft.VisualC]Microsoft.VisualC.IsConstModifier)
''?A0x1f1e2151.unnamed-global-0''
newobj instance void [mscorlib]System.String::.ctor(int8*)
我會馬上解釋這段冗長而令人費解的文字,但其基本思路是編譯器加載了 C++ 字符串文字量的地址,然後產生一個 newobj 指令,該指令將文字量地址到 String 的構造函數。另外,編譯器為非托管字符串文字量創建了一個專門的 Array 類型——這就是前面代碼段中樣子奇怪的 $ArrayType$0x11197cc2,還有一個 被命名為?A0x1f1e2151.unnamed-global-0 的靜態實例,如圖 Figure 3 所示:
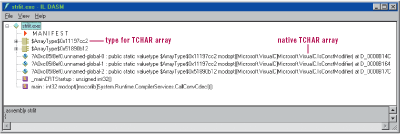
Figure 3 Disassembler 中的 StrLit
如果你花點時間看看 MSIL,你將發現 modopts 無處不在。一個 modopt 的完全描述已超出了本欄目范圍,但是其基本思路是編譯器 能用 modopt 提供有關公共語言運行時無法理解的類型的附加信息,但是該程序集的其它使用者可能理解——在這種情況下,該信息就是全局常量。CLR本身沒有常量的概念,但是 程序集的其它使用者可能知道。如果該程序集被引入 C++,則 C++ 編譯器會知道該變量是個常量;但是如果該程序集被 C# 使用,C# 編譯器將會忽略 modopt 常量,因為 C# 沒有常量的概念,正如你所能看到的,當你在托管代碼中使用原生類型時有許多奇怪或迷惑發生。
當你用 S 語法使用托管文字量時,不管怎樣,一切都很簡單:
// String* s1 = new String(S"This is a String literal");
ldstr "This is a String literal"
這裡沒有函數調用,僅有一個 ldstr 指令。這個指令將引用某個字符串文字量的新對象壓入,儲存在程序的元數據中。無論是用文字量創建 String 對象還是直接將它傳遞給需要字符串的 某些函數,都是如此:
// Console::WriteLine(S"World");
ldstr "World"
call void [mscorlib]System.Console::WriteLine(string)
了解所發生的事情的另外一種方法是用/FAs編譯程序來生成一個程序集列表。(是的,它也可以用於 MSIL)Figure 5 展示了用/FAs編譯 StrLit 後經過編輯的結果,。這裡有趣的是你可以看到編譯器為 TCHAR字符串 "This is a TCHAR string" 生成了兩個字符串($SG1883 and $SG2266),即使它們有相同的內容。然而,此處針對 S"This is a String literal" 僅有一個托管字符串 文字量 ($StringLiteralTok$70000001$),它被使用了兩次。大多數程序員調用 "uniquification” 進程,但是 出於某種原因微軟的家伙們(Redmondtonians)稱之為“字符串暫留”(string interning)”。正如說明文檔所描述的:“公共語言基礎架構(CLI)確保涉及具有相同字符序列的兩個元數據符號的兩個 ldstr 指令的結果精確地返回相同字符串對象。”
所有這些要點是托管文字量更快。為了弄清楚它到底有多快,我寫了另一個托管 C++ 程序,StrTime,它分配了一大批字符串並報告花了多長時間。我 使用了我在 2004年6月專欄中的 ShowTime 類:
_stprintf(msg, _T("Test 1: Allocate %d strings using LPCTSTR"),num);
ShowTime st(msg);
for (int i=0; i<num; i++) {
String* s = new String(_T("This is a TCHAR string"));
}
StrTime 則使用托管 S 文字量做同一件事。下面是結果:
C:\>StrTime 50000000
Test 1: Allocate 50000000 strings using LPCTSTR: 32797 msec
Test 2: Allocate 50000000 strings using .NET S literal: 100 msec
Wow!正如你所看到的,S 字符串快得多。但是,嗨——等一下,這裡到底發生了什麼?ldstr 真的快327倍嗎?這個測試值得可疑有兩個原因。首先,函數調用不應該如此 昂貴;其次,我的機器只有 785MB,我真的分配了5000萬個字符串嗎?當然不是!因為變量s在循環內部存活,每次反復它都超出范圍——這使得它滿足垃圾收集 器的條件。事實上,你可以寫如下的程序並且它永遠循環而不會耗盡內存:
while (1) {
String* s = new String(L"foo");
}
在這個測試中,S 文字量表現得如此之快的主要原因是 C++ 文字量調用 newobj 來創建新的對象,盡管 S 文字量生成 ldstr,它只簡單地將相同 的對象引用一次又一次地壓入棧中,5000萬次(記住“字符串暫留”)為了證明這一點,我修改了 StrTime (StrTime2)以顯示托管 String 的實際地址。為此,你需要使用 GCHandle:
String* s = new String(S"foo");
GCHandle h = GCHandle::Alloc(s, GCHandleType::Pinned);
IntPtr ptr = h.AddrOfPinnedObject();
_tprintf(_T(" string at %p\n"), ptr.ToInt32());
h.Free();
這創建了固定句柄,於是可以調用 GCHandle::AddrOfPinnedObject 獲得固定對象的地址。下面是運行新程序的測試結果:
C:\>StrTime2 5
Test 1: Allocate 5 strings using LPCTSTR
string at 04AC21E0
string at 04AC22D8
string at 04AC2318
string at 04AC2358
string at 04AC2398
Test 2: Allocate 5 strings using .NET S literal
string at 04AC218C
string at 04AC218C
string at 04AC218C
string at 04AC218C
string at 04AC218C
無需分配5000萬個字符串;5個就足以搞定了。正如你所看到的,每次調用新的 String(_T("foo")) 5次或無 窮次來生成一個新的對象,而調用新的 String(S"foo") 加載相同的對象。因此用 C++ 文字量進行5000萬字符串測試花費如此之長時間的真正原因是運行時不得不分配大量的內存並執行垃圾收集。
所有這些可能已經比你期望知道的更多了,但是這是為了好玩我還寫做另一個修改,StrTime3,它在分配字符串之前強制進行垃圾收集,這時則顯示“認為被分配的”內存數量 (正如 GC::GetTotalMemory 文檔裡所描述的那樣):
GC::Collect();
GC::WaitForPendingFinalizers();
// allocate strings
printf("TotalMemory = %d\n", GC::GetTotalMemory(false));
而這裡是結果:
C:\>StrTime3 50000000
Test 1: Allocate 50000000 strings using LPCTSTR
TotalMemory = 190952, time: 33147 msec
Test 2: Allocate 50000000 strings using .NET S literal
TotalMemory = 43484, time: 110 msec
正如你所看到的,5000萬個托管 String 只占有了非常少的空間——特別是當真正只有一個時!盡管用TCHARs,垃圾收集器僅用了 190,952 字節。高等數學推理會得出5000萬字符串 無法裝入 191 KB,因此可以肯定地說:Framework 在垃圾收集裝置裡安裝了一些機關。
最後我擔心我的所有測試程序都沒有回答你的問題——使用托管 String 文字量到底有多快?沒有微妙或納秒粒度的計時器就不可能說清楚這個問題。但是至少我的研究可以幫助你理解表象下面 所發生的一切,從而你可以明白為什麼 ldstr 比 newobj 有更加顯著的效率。
因此,你要使用哪種類型的文字量呢?事實是:用戶可能絕不會注意到其中的差別。但是無論何處你調用一個使用 String 的函數最好是用 S 類型文字量。注意在 MFC 中,因為可以交替使用 LPCTSTR 和 CString,你不能將傳遞 String 給需要 TCHARs 的C/C++函數。那是因為托管字符串總是 Unicode (寬字符),並且從 String 到 wchar_t 沒有自動轉換機制。因此,你需要在 vcclr.h 中提供的 PtrToStringChars函數。下一個問題示范了一個這方面的例子。
關於托管的和原生的字符串文字量最後要注意的一個小問題是:如果你檢查在 Figure 3 和 Figure 4 中的ILDASM 代碼,你會看到雖然文本 "This is a String literal" 在反匯編代碼中清晰可見,而表示 C++ 文字量 "This is a TCHAR string" 的文本卻無處可尋。它被隱藏在一個神秘變量中了 A0x1f1e2151.unnamed-global-0。這是否意味著 C++ 文字量提供了更大迷惑性——就是說,讓你可以在眾目睽睽之下隱藏你的字符串?實際並不如此,Figure 3 中的 MSIL 代碼報告了神秘的 "unnamed-global-0" 是 在 "D_0000B14C."。出於好奇,我在一個十六進制查看程序中查看了 StrLit.exe,果真有這個串,確切位置在 0xB14C。Figure 6 展示了十六進制程序顯示多所有東西:
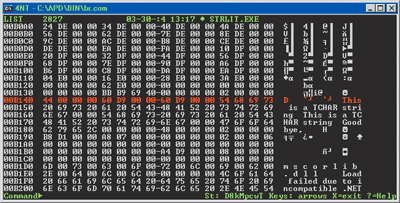
Figure 6 十六進制程序顯示的信息
我遇到了一個在即將出品的 C# 應用軟件中保護我們的知識產權的問題。我知道所有的代碼都可以被 ILDASM 反匯編,這將使得別人可以很 輕松地獲得我們的數學公式。為了解決這個問題,我可以寫一個 C++ DLL並使用 DllImport 在 C# 中導入函數,我更喜歡使用托管 C++ 寫一個托管 __gc 類,這樣我便能同時暴露屬性和方法。當我 這樣做並編譯 DLL 時,我仍然可以使用 ILDASM 對之進行反匯編,這樣並沒有實現我試圖做的事情。我認為 C++ 編譯器會生成原生機器代碼,而不是 MSIL。是 不是這樣呢?
Matt Hess
當你用/clr編譯 C++ 程序時,編譯器將所有函數視作托管的,並默認將它們編譯成 MSIL(少數情況除外,這我會在稍後討論)。結構和類可以是托管的,也可以是非托管的,這取決於你的是否使用 __gc。如果你想將一個特殊函數編譯成為原生代碼(可能為了隱藏它的實現,或出於性能的原因),你可以使用 #pragma unmanaged:
#pragma unmanaged
// this fn and all subsequent ones are compiled
// to native code
void func(/* args */)
{
...
}
#pragma managed
#pragma managed 指示開關返回到托管模式。Figure 7 展示了我寫的一個簡單的 C++程序,它有兩個函數,PrintFive1 和 PrintFive2,每個 函數打印字符串 5 次。第一個函數是原生的,第二個是托管的。如果你用/FAs編譯並查看所生成的 .asm 文件,你將看到在 PrintFive1 中的 for 循環編譯成如下的東東:
; for (int i=0; i<5; i++) {而 PrintFive2 中相同的 for 循環編譯卻是下面這樣的:
mov DWORD PTR _i$1662[ebp], 0
jmp SHORT $L1663
...
; etc... (more native assembly)
; for (int i=0; i<5; i++) {
ldc.i.0 0 ; i32 0x0
stloc.0 ; _i$1669
...
; etc... (more MSIL)
我說過當你使用/clr時,所有函數默認是托管的,但是這並不完全正確。雖然 MSIL 通常足以用來表示大多數 C/C++ 構造,但它不能表示全部 的東西。少數情況下,它強制某個函數被編譯成原生代碼,即便沒有 #pragma unmanaged 也一樣。這種情況很容易看出來:比如,如果你的函數有__asm 塊,setjmp/longjmp 指令,或一個可變參數列表(varargs)。 因為 MSIL 無法處理這些結構,編譯器便自動將這些函數編譯為原生代碼。
你可以只用 #pragma unmanaged 來編譯純 C++ 函數——也就是說,你不使用托管類型。你不能用 #pragma unmanaged 來編譯托管 __gc 類的方法(那樣做沒有意義)。因此,如果你想用 C++ 來隱藏你的算法,你必須用原生的 C++ 類型將他們實現成純粹的 C++ 函數。你的 __gc 類方法可以調用這些函數,在調用你的實現之前,你必須將任何托管參數轉換成非托管類型:
__gc class Widget {
public:
MyMethod(String *s)
{
// convert managed types to C++ types
const WCHAR __pin* pstr = PtrToStringChars(s);
// call unmanaged C++ function (in #pragma unmanaged block)
DoSecretAlgorithm(pstr);
}
};
托管 C++ 是微軟唯一允許你在相文件中組合使用原生代碼和 MSIL 代碼的語言,這就是它如此強大的原因之一!另一種使用托管 C++ 混合代碼的方法是通過鏈接。比如,無論何時你調用如 printf 或 memset 這樣的 C 庫函數,它們從相應的庫中獲得靜態鏈接。當你使用/clr,它自動 暗示使用/MT來確保你的程序與 C 運行時庫的多線程版本進行鏈接。CLR 需要它們,因為垃圾收集器在一個獨立的線程裡運行終結例程(finalizers)。
本文配套源碼