雖然 Microsoft® .NET Framework 確實能提高開發人員的工作效率,但許多人對托管代碼的性能還是有些擔憂。新版本的 Visual C++® 將會讓您消除這些擔憂。對於 Visual Studio® 2005,C++ 語法本身得到了很大的改進,從而使它編寫更加迅速。另外,還提供了一個靈活的語言框架來與公共語言運行庫 (CLR) 相交互以便於編寫高性能的程序。
許多編程人員認為 C++ 之所以能帶來高性能,是因為它生成本機代碼,但即使您的代碼完全托管,仍然可以獲得出眾的性能。通過靈活的編程模型,C++ 不會讓您束縛在面向過程編程、面向對象編程、可再生編程或者元編程。
另一個常見的誤解是:不管使用什麼語言,在 .NET Framework 中都能獲得同樣好的性能 — 通過各種編譯器生成的 Microsoft 中間語言 (MSIL) 本質上是等同的。即使在 Visual Studio .NET 2003 中也無法這樣,但在 Visual Studio 2005 中,C++ 編譯器團隊致力於確保優化本機代碼多年所獲得的所有經驗都能夠應用到托管代碼優化上。C++ 為您提供充分的靈活性來進行更好的優化,比如進行高性能封送處理,這在其他語言中是無法做到的。此外,Visual C++ 編譯器還生成任何 .NET 語言中最優化的 MSIL。結果是 .NET 中最優化的代碼來自 Visual C++ 編譯器。
優化的MSIL
在 .NET 環境中,編譯分為兩個不同的部分。第一部分為編程人員通過語言編譯器(C#、Visual Basic? 或 Visual C++)進行編譯和優化,以生成 MSIL。第二部分包括將 MSIL 送到實時 (JIT) 編譯器或 NGEN,由它讀取 MSIL 並隨後生成優化的本機代碼。顯然,語言編譯器和 JIT 是不可分離的組件,這意味著要生成好的代碼,二者必須協同工作。
Visual C++ 始終提供任何編譯器的最高級優化設置。這在托管代碼中也沒有改變。甚至在 Visual C++ .NET 2003 中這一點也很明顯,它只是通過用於生成 MSIL 代碼的本機編譯器開始啟用優化。
在 Visual C++ 2005 中,編譯器可以對 MSIL 代碼執行標准本機代碼優化很大的子集。從基於數據流的優化到表達式優化,再到循環展開,這一切都包含在內。平台中的其他任何語言都無法做到這一級別的優化。在 Visual C++ .NET 2003 中,全程序優化 (Whole Program Optimization, WPO) 不支持使用 /clr 開關構建,但 Visual C++ 2005 為托管代碼添加了這個功能。這個功能啟用了跨模塊優化,本文後面將會對其進行討論。
在 Visual C++ 2005 中,托管代碼唯一不可用的一種優化是 Profile Guided Optimizations,雖然在以後的版本中可能可用。有關更多信息,請參閱 Write Faster Code with the Modern Language Features of Visual C++ 2005。
JIT 和編譯器優化交互
Visual C++ 生成的優化代碼提供給 JIT 或 NGEN 以生成本機代碼。不管 Visual C++ 編譯器生成的代碼是 MSIL 還是非托管代碼,生成代碼的優化器還是十幾年前就已開發並已進行調整的優化器。
對 MSIL 代碼的優化是對非托管代碼進行優化的一個大子集。需要指出的是,允許的優化類隨編譯器生成的是可驗證代碼 (/clr:safe) 或非可驗證代碼 (/clr or /clr:pure) 的不同而不同。在少量的幾種情況下,編譯器會因為元數據或可驗證性限制而無法完成操作,包括縮減運算量(將相乘轉換成指針相加),以及將對一個類的私有成員的訪問內聯到另一個類的方法體中。
Visual C++ 編譯器生成 MSIL 代碼之後,就可以交給 JIT 進行處理。JIT 讀取 MSIL 並開始執行優化,這些優化對 MSIL 中的變化很敏感。一個 MSIL 指令序列也許能夠很好地進行優化,但另一個(語義上等同的)序列卻可能抑制優化。例如,寄存器分配是一個優化,在這個優化中,JIT 優化器試圖將變量映射到寄存器中;寄存器是作為執行算術和邏輯運算的操作數使用的實際硬件。有時,語義上等同但采用兩種不同方式編寫的代碼可能會使優化器在執行良好的寄存器分配上所花費的時間相差巨大。循環展開是一個可能導致 JIT 分配寄存器出現問題的轉換的例子。
C++ 編譯器完成的循環展開可以公開更多的指令級並行,但也創建了更多活變量 (live variable),編譯器需要使用它們來跟蹤寄存器分配。CLR JIT 只能跟蹤固定數目的寄存器分配變量;一旦需要跟蹤的數目超出這個數目,它就開始將寄存器的內容移到內存中。
因此,必須先後對 Visual C++ 編譯器和 JIT 進行微調以生成最佳代碼。Visual C++ 編譯器負責進行的優化是那些對 JIT 來說太耗時的優化,以及那些在從 C++ 源代碼編譯為 MSIL 的編譯過程中會造成太多信息丟失的優化。
讓我們看一下 Visual C++ 對托管代碼的一些優化。
公共子表達式消除和代數簡化
公共子表達式消除(Common subexpression elimination,CSE)和代數簡化 (algebraic simplification) 是兩個強大的優化,它們允許編譯器在表達式級別執行一些基本優化,以便開發人員可以專注研究算法和體系結構。
下面顯示的代碼片段分別作為 C# 和 C++ 編譯;二者都是在 Release 配置下編譯的。變量 a、b 和 c 從一個作為參數傳遞的數組復制到包含這段代碼的函數中:
以下是引用片段:
int d = a + b * c;
int e = (c * b) * 12 + a + (a + b * c);
圖 1 顯示了 C# 編譯器和 C++ 編譯器通過這段代碼生成的 MSIL,它們都啟用了優化。C# 需要 19 條指令,而 C++ 只需 13 條。另外,您可以看到 C++ 代碼可以對 b*c 表達式進行 CSE。該編譯器可以對 a+a 進行代數簡化,即改為生成 2*a,也可以對 (c*b)*12 + c*b 進行代數簡化,即改為生成 (c*b)*13。我發現增加的這個 CSE 特別有用,因為我見過編程人員在實際的代碼中沒有進行這種代數簡化。請參閱補充內容“C# 編譯器優化”。
全程序優化
Visual C++ .NET 對非托管代碼添加了 WPO。而在 Visual C++ 2005 中,這個功能擴展到了托管代碼。它不是一次編譯和優化一個源文件,而是一次跨所有源文件和頭文件進行編譯和優化。
現在編譯器可以跨多個源文件執行分析和優化。例如,如果沒有 WPO,編譯器只能在單個編譯域中內聯函數。有了 WPO,編譯器就可以從程序中的所有源文件內聯函數。
在以下的示例中,編譯器可以做的事情包括跨編譯器內聯和常量傳遞,以及其他類型的過程間優化:
以下是引用片段:
// Main.cpp
...
MSDNClass ^MSDNObj = gcnew MSDNClass;
int x = MSDNObj->Square(42);
return x;
...
// MSDNClass.cpp
int MSDNClass::Square(int x)
{
return x*x;
}
在這個示例中,Main.cpp 調用 Square 方法,而這個方法是另一個源文件中的 MSDNClass 的一部分。當編譯時進行 /O2 優化,而不進行全程序優化時,Main.cpp 中產生的 MSIL 如下所示:
ldc.i4.s 42
call instance int32 MSDNClass::Square(int32)
您可以看到,它首先將值 42 加載到堆棧中,然後調用 Square 函數。作為對照,對於相同的程序,當編譯時打開全程序優化時,則生成的 MSIL 如下所示:
ldc.i4 0x6e4
它沒有加載 42,也沒有調用 Square 函數。相反,在全程序優化下,編譯器可以內聯來自 MSDNClass.cpp 的函數並進行常量傳遞。最終的結果只是一條簡單的指令 — 加載 42*42 的結果,十六進制表示為 0x6e4。
雖然 Visual C++ 編譯器執行的一些分析和優化在理論上 JIT 編譯器也可以執行,但對 JIT 編譯器的時間限制使得這裡提到的許多優化當前還無法實現。一般情況下,NGEN 會比 JIT 編譯器更早實現這些類型的優化,因為 NGEN 沒有 JIT 編譯器必須面對的這類響應時間限制。
64 位 NGEN 優化
出於本文需要,我將 JIT 和 NGEN 統稱為 JIT。對於 32 位版本的 CLR,JIT 編譯器和 NGEN 執行的優化相同。但 64 位版本的卻不是這樣,在 64 位版本中,NGEN 比 JIT 所進行的優化明顯更多。
64 位的 NGEN 利用了這樣的事實:它可以比 JIT 花費更多的時間進行編譯,因為 JIT 的吞吐量直接影響應用程序的響應時間。我在本文特別提到了 64 位的 NGEN,因為它針對 C++ 風格的代碼進行相對地微調,它進行的一些優化(例如雙 Thunk 消除優化)對 C++ 起到很大的幫助,這些優化是其他 JIT 和 NEGN 所不具備的。32 位 JIT 和 64 位 JIT 分別是 Microsoft 中兩個不同團隊使用兩種不同的代碼基實現的。32 位 JIT 是由 CLR 團隊開發的,而 64 位 JIT 是由 Visual C++ 團隊開發的,而且基於 Visual C++ 代碼基。因為 64 位 JIT 是由 C++ 團隊開發的,所以它更加注重與 C++ 相關的問題。
雙 Thunk 消除
64 位 NGEN 執行的最重要的優化之一就是所謂的雙 thunk 消除。這個優化在帶 /clr 開關編譯的 C++ 代碼中通過函數指針或虛擬調用解決了一個轉換,這個轉換發生在通過托管代碼調用托管入口點的時候。(在 /clr:pure 或 /clr:safe 編譯代碼中不會發生這種轉換。)發生這個轉換是因為在 callsite 上函數指針和虛擬調用都沒有足夠的信息可以確定它們調用的是托管入口點 (MEP) 還是非托管入口點 (UEP)。
為了向後兼容,始終選擇 UEP。但如果托管 callsite 實際調用的是托管方法呢?在這種情況下,除了初始 thunk 從托管 callsite 進入 UEP 外,還會有一個 thunk 從 UEP 進入目標托管方法。這個托管-托管 thunk 過程通常稱為雙 thunk。
64 位 NGEN 實現了對“從非托管到托管”的調用(即為反過來對托管代碼 thunk 的調用),從而實現了優化。可以進行一個檢查來確定是否是這種情況;如果是,它就會跳過這兩個 thunk,並直接跳到托管代碼,如圖 2 所示。這樣可以節省許多指令,在實際的代碼建模基准中,我發現有 5-10% 的提高(在人為測試中,可以看到超過 100% 的性能提高)。
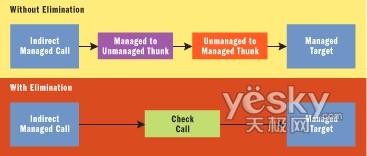
圖 2 雙 Thunk 消除
不過有一點需要注意,那就是這個優化只有在位於默認應用程序域時才生效。有一個很好的小規則,那就是記住,默認 AppDomain 通常會獲得更好的性能。
C++ Interop
C++ interop 是用於本機托管 interop 的一種技術,它允許標准 C++ 代碼帶 /clr 開關編譯,以便直接調用本機函數,而不用編程人員添加其他任何代碼。當使用 /clr 開關時生成的代碼是 MSIL(除了少數特例),並且數據可以是托管或非托管的(由用戶指定數據的存放位置)。我傾向認為 C++ interop 是沒有人知道的最重要的 .NET 功能。它是真正具有突破性的改革,但要真正了解 C++ interop 的強大之處還需要一定的時間。
在其他與 .NET 兼容的語言中,要與本機代碼進行 interop 需要您將本機代碼放在一個 DLL 中,並使用 dllimport 調用帶有顯式 P/Invoke 的函數(或者其他一些與此類似的做法,取決於您使用的語言)。否則就必須使用笨重的 COM interop 訪問本機代碼。這明顯不方便,而且經常會遇到性能比 C++ 差很多的情況。
一般不認為 C++ interop 是 C++ 語言的性能特征,但正如您將看到的,C++ interop 所提供的靈活性和便利性卻可以讓您借助 CLR 獲得更好的性能。
單映像中的本機代碼和托管代碼
Visual C++ 可以使編程人員(按逐函數方式)有選擇地選擇哪些函數是托管的,哪些是本機的。 這是通過 #pragma managed 和 #pragma unmanaged 實現的,圖 3 顯示了其中一個例子。在許多計算量大的任務中,讓核心函數進行本機編譯而其他代碼進行托管編譯可以帶來很大好處。在單個映像中,C++ 可以將托管代碼和本機代碼混合一起,通過本機函數調用托管函數(反之亦然)不需要特殊的語法。在這種粒度下,C++ 可以很輕松地控制從托管代碼向本機代碼的轉換,反之亦然。
當從托管代碼向本機代碼轉換(或反向)時,執行的過程要經過由編譯器/鏈接器生成的 thunk。這個 thunk 需要一定代價,編程人員都竭力避免付出這樣的代價。有大量工作是在 CLR 中完成的,並且編譯器會使轉換的成本降到最低,但開發人員也可以通過降低這種轉換的頻率來幫助降低成本。
圖 4 的 A 部分中是一個 C++ 應用程序,它的部分代碼 (Z.cpp) 經編譯生成 MSIL (/clr),而其他部分(X.cpp 和 Y.cpp)經編譯生成本機代碼。在這個程序中,Y.cpp 和 Z.cpp 中有些函數經過來回多次調用。這會導致大量托管/本機轉換,從而降低程序的執行速度。
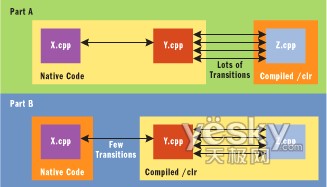
圖 4 更改托管界限
圖 4 中的 B 部分顯示了如何優化該程序來使托管/本機轉換降至最少。其思想是確定常用接口,將它們都移到托管/本機界限的一側,從而消除所有跨常用接口的轉換。使用 Visual C++ 為 interop 提供的工具可以很輕松地完成這項工作。
例如,要從圖 4 中的 A 轉到 B,只需要用 /clr 開關重新編譯 Y.cpp。現在 Y.cpp 被編譯為托管代碼,從 Z.cpp 調用就不需要有從托管到本機的轉換成本。當然,您也需要考慮從 Y.cpp 生成 MSIL 的相關性能代價,並確保這種折衷對應用程序有利。
高性能封送處理
封送處理是托管/本機 interop 中成本最高的方面之一。在 C# 和 Visual Basic .NET 等語言中,封送處理是在調用 P/Invoke 時 CLR 隱式完成的(使用默認封送拆收器或者在實現 IcustomMarshaler 時用自定義封送處理代碼完成)。而在 C++ interop 中,編程人員可以在代碼中認為合適的地方顯式封送處理數據。這樣做的好處是編程人員可以一次性將數據封送到本機數據,然後通過多次調用重用數據的封送處理結果,從而均攤封送處理成本。
圖 5 顯示了帶 /clr 開關編譯的代碼片段。在這段代碼中有一個 for 循環,在這個循環中調用本機函數 (GetChar)。在圖 6 中,采用 C# 實現相同的代碼,並且通過調用 GetChar 來使 CsharpType 類封送處理到 NativeType,如下所示:
以下是引用片段:
class NATIVECODE_API NativeType {
public:
NativeType();
int pos;
int length;
char *theString;
};
在 C++ 中,用戶顯式使用本機類型,因此不需要隱式封送。這種類型的優化所節省的成本相當大。在這個示例中,C++ 實現比 C# 實現快 18 倍。
具有 .NET 類型的模板和 STL
Visual C++ 2005 中一些比較有趣的新性能特征是具有托管類型(包括 STL/CLI)的模板、與托管代碼的全程序優化、延遲加載和確定性終止。Visual C++ .NET 2003 可以在本機類型上為模板生成 MSIL,但不能在該模板中將托管類型作為參數化類型使用。在 Visual C++ 2005 中,這個問題已經得到糾正,模板現在可以將托管類型或非托管類型作為參數。現在,模板的強大功能可以用於在 .NET 中編寫的代碼了(您還應該看一下 Blitz++ 和 Boost 庫所做的工作)。
C++ 標准模板庫 (STL) 是庫設計中一個重大革新。它可以讓您很好地利用容器和算法而不會犧牲性能,這一點已獲證實。在 Visual C++ .NET 2003 中,在模板中對托管類型的限制意味著沒有托管類型的配套 STL。Visual C++ 2005 中除了具有這種限制外,還引入了 STL/CLI — 一種已證實可處理托管類型的 STL 版本。.NET 中的基類庫 (BCL) 最初在 .NET 中引入了容器,但 Visual C++ 小組中的計劃是 STL/CLI 的性能會更加優越。如果您想對 STL/CLI 有更多了解,Visual C++ 開發人員中心中有一篇 Stan Lippman 所撰寫的優秀文章 STL.NET Primer。
有了 STL/CLI 後,您可以通過 STL 實現您喜歡的所有內容,包括矢量、列表、雙端隊列、映射、集合以及哈希映射和集合。您還可以獲得排序、搜索、集合運算、內積和卷積等算法。STL/CLI 算法的一個驚人之處是可對本機和 STL/CLI 版本使用相同的實現。STL 的良好設計將通過可移植的強大的代碼來讓每個 C++ 編程人員受益。
確定性幫助性能
由於您可以使用強大的模式和術語庫,編寫有效的 C++ 變得輕松許多。其中許多模式和術語(包括 Resource Acquisition Is Initialization (RAII))使用 C++ 語言中一個稱為確定性終止的功能。它的原則是當一個對象被 delete 操作符刪除(對於堆棧分配對象)或處於作用域外(對於堆棧分配對象)時,就會調用該對象的析構函數。確定性終止可以挽救性能,因為一個對象占有資源的時間越長(比它真正需要的長),性能下降越多,因為其他對象試圖獲取相同的資源。
使用 CLR 終止程序會導致終止程序代碼在對象處於作用域外(假設釋放鎖的代碼是該終止程序)但還沒在對象的終止程序上調用終止線程時在某一個位置執行。顯然,這樣做並不理想,因為當編程人員期望執行終止線程時,它可能不執行。另外,與對象相關的內存直到終止程序執行後才會回收,這樣會使程序對內存的要求增加。
在基於 .NET 的代碼中,一個有助於避免這種問題的常見術語是 Dispose 模式。要使用它,開發人員需要為他們的類實現一個 Dispose 方法,然後在不再需要對象時調用該方法。當 C++ 編程人員要對對象調用 delete 時,就可以同時在代碼中調用這個方法,但即使在 C++ 中,這樣也很容易出錯且過於繁雜。諸如 C# 等語言添加了“using”構造,它有助於解決後面兩個問題,但對於特殊情況,它也會很復雜且容易出錯。
相反,RAII 這個 C++ 術語自動獲得和釋放資源,而且不容易出錯,因為編程人員不需要編寫額外代碼。Visual C++ .NET 2003 不支持堆棧分配 .NET 對象的確定性終止,但在 Visual C++ 2005 中支持這個功能。
在圖 7 的上半部分,可以注意到類型為 Socket_t 的對象使用了基於堆棧的語法,並將具有基於堆棧的清除語義。這樣,當在第三行產生一個異常時,會出現什麼情況呢?對於基於堆棧的語義,會確定性地為 mainSock 運行析構函數,但由於還沒在堆棧中創建 backupSock,所以沒有對象可以析構。
要編寫語義上等同於 C# 的代碼有些困難且容易出錯;請參見圖 7的下半部分。當然,這個例子很小,但隨著這種任務復雜度的增加,出現錯誤的可能性就會越大。
延遲加載
雖然 .NET Framework 為提高性能而進行了微調,但在啟動時加載 CLR 還稍微有些延遲。在許多應用程序中,可能有一些代碼路徑和方案沒有托管代碼,特別是當通過 .NET 功能對現有的舊式程序進行改造時。在這些情況下,您的應用程序就應該不會有這種相關的啟動延遲。您可以使用 Visual C++ 中現有的功能 — DLL 的延遲加載來解決這個問題。
其思想是只在實際需要使用 DLL 中的某些內容時才加載該 DLL。這種思想也可應用於加載內容為 .NET 程序集的 DLL。通過使用鏈接器選項 /DELAYLOAD:dll(通過它指定想要延遲加載的 .NET 程序集),除了可以延遲加載列出的 .NET 程序集外,還可以延遲加載 CLR(如果所有 .NET 程序集都延遲加載)。結果是,應用程序的啟動速度可以完全像本機啟動那麼快,從而消除了托管應用程序最常見的弊端之一。
為什麼 dllexport 不能始終適用
使用 __declspec(dllexport) 有它自己的缺陷。當您有兩個映射(DLL 或 exe)都為托管映射,但通過 dllexport 而不是通過 #using 公開功能時,dllexport 的問題就會暴露。因為 dllexport 是一個本機構造,所以每次使用 __declspec(dllexport) 跨 DLL 邊界調用時,都會先引發從托管到本機的轉換,再引發從本機到托管的轉換。這樣就難以獲得很好的性能。
解決這種性能問題的選擇很有限。沒有簡單的“開關”可以立刻讓 __declspec(dllexport) 成為對托管代碼沒有相關 thunk 的構造。推薦的修復辦法是將導出的功能包裝在一個托管類型(引用或值類/結構)中,導入程序再通過導出 DLL 上的“#using”訪問該類型,從而直接訪問導出 DLL 中的功能。通過這種更改,當從托管客戶端調用這段托管代碼時就不需要進行轉換。圖 8 中對此做了說明,其中 A 部分顯示了與使用 __declspec(dllexport) 相關的成本,B 部分顯示了使用 #using 和將函數包裝在 .NET 類型中所帶來的優化。這種方法的一個潛在問題是導出 DLL 的非托管導入程序不能對 DLL 的功能進行 __declspec(dllimport)。這在進行更改之前應該加以考慮。
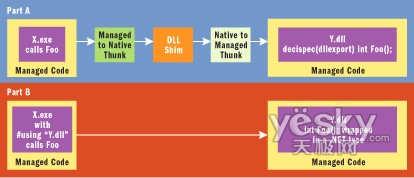
圖 8 降低 Thunk 成本
圖 8 的 A 部分顯示了使用 __declspec(dllexport) 將托管函數公開給托管代碼的轉換路徑。在 B 部分中,該函數被包裝成托管類型,並使用 #using 來訪問該函數。與 A 部分中的過程相比,其結果是省去了成本很高的 thunk。
小結
Visual Studio .NET 2002 引入了帶有 Visual C++ 的 .NET Framework 已有很長的時間。C++ 使得編程人員編寫高性能托管代碼具有很大的靈活性,而且都是按 C++ 編程人員很自然的方式工作的。有許多語言可用於進行 .NET 編程;如果您想獲得最大的性能,則 Visual C++ 是顯而易見的選擇。
Kang Su Gatlin 是 Microsoft Visual C++ 團隊的程序經理,他的大部分工作時間都在嘗試尋找可讓程序運行更快的系統方式。在到 Microsoft 工作之前,他從事高性能和網格計算。