探索C#之微型MapReduce,
MapReduce近幾年比較熱的分布式計算編程模型,以C#為例簡單介紹下MapReduce分布式計算。
閱讀目錄
背景
某平行世界程序猿小張接到Boss一項任務,統計用戶反饋內容中的單詞出現次數,以便分析用戶主要習慣。文本如下:

![]()
const string hamlet = @"Though yet of Hamlet our dear brother's death
The memory be green, and that it us befitted
To bear our hearts in grief and our whole kingdom
To be contracted in one brow of woe,
Yet so far hath discretion fought with nature
That we with wisest sorrow think on him,
Together with remembrance of ourselves.
Therefore our sometime sister, now our queen,
The imperial jointress to this warlike state,
Have we, as 'twere with a defeated joy,--
With an auspicious and a dropping eye,
With mirth in funeral and with dirge in marriage,
In equal scale weighing delight and dole,--
Taken to wife: nor have we herein barr'd
Your better wisdoms, which have freely gone
With this affair along. For all, our thanks.
Now follows, that you know, young Fortinbras,
Holding a weak supposal of our worth,
Or thinking by our late dear brother's death
Our state to be disjoint and out of frame,
Colleagued with the dream of his advantage,
He hath not fail'd to pester us with message,
Importing the surrender of those lands
Lost by his father, with all bonds of law,
To our most valiant brother. So much for him.
Now for ourself and for this time of meeting:
Thus much the business is: we have here writ
To Norway, uncle of young Fortinbras,--
Who, impotent and bed-rid, scarcely hears
Of this his nephew's purpose,--to suppress
His further gait herein; in that the levies,
The lists and full proportions, are all made
Out of his subject: and we here dispatch
You, good Cornelius, and you, Voltimand,
For bearers of this greeting to old Norway;
Giving to you no further personal power
To business with the king, more than the scope
Of these delated articles allow.
Farewell, and let your haste commend your duty.";
View Code
小張作為藍翔高材生,很快就實現了:
var content = hamlet.Split(new[] { " ", Environment.NewLine }, StringSplitOptions.RemoveEmptyEntries);
var wordcount=new Dictionary<string,int>();
foreach (var item in content)
{
if (wordcount.ContainsKey(item))
wordcount[item] += 1;
else
wordcount.Add(item, 1);
}
作為有上進心的青年,小張決心對算法進行抽象封裝,並支持多節點計算。小張把這個統計次數程序分成兩個大步驟:分解和計算。
第一步:先把文本以某維度分解映射成最小獨立單元。 (段落、單詞、字母維度)。
第二部:把最小單元重復的做合並計算。
小張參考MapReduce論文設計Map、Reduce如下:
Map實現
Mapping
Mapping函數把文本分解映射key,value形式的最小單元,即<單詞,出現次數(1)>、<word,1>。
public IEnumerable<Tuple<T, int>> Mapping(IEnumerable<T> list)
{
foreach (T sourceVal in list)
yield return Tuple.Create(sourceVal, 1);
}
使用,輸出為(brow, 1), (brow, 1), (sorrow, 1), (sorrow, 1):
var spit = hamlet.Split(new[] { " ", Environment.NewLine }, StringSplitOptions.RemoveEmptyEntries);
var mp = new MicroMapReduce<string>(new Master<string>());
var result= mp.Mapping(spit);
Combine
為了減少數據通信開銷,mapping出的鍵值對數據在進入真正的reduce前,進行重復鍵合並。也相對於提前進行預計算一部分,加快總體計算速度。 輸出格式為(brow, 2), (sorrow, 2):
![]()
public Dictionary<T, int> Combine(IEnumerable<Tuple<T, int>> list)
{
Dictionary<T, int> dt = new Dictionary<T, int>();
foreach (var val in list)
{
if (dt.ContainsKey(val.Item1))
dt[val.Item1] += val.Item2;
else
dt.Add(val.Item1, val.Item2);
}
return dt;
}
View Code
Partitioner
Partitioner主要用來分組劃分,把不同節點的統計數據按照key進行分組。
其輸出格式為: (brow, {(brow,2)},(brow,3)), (sorrow, {(sorrow,10)},(brow,11)):
![]()
public IEnumerable<Group<T, int>> Partitioner(Dictionary<T, int> list)
{
var dict = new Dictionary<T, Group<T, int>>();
foreach (var val in list)
{
if (!dict.ContainsKey(val.Key))
dict[val.Key] = new Group<T, int>(val.Key);
dict[val.Key].Values.Add(val.Value);
}
return dict.Values;
}
View Code
Group定義:
![]()
public class Group<TKey, TValue> : Tuple<TKey, List<TValue>>
{
public Group(TKey key)
: base(key, new List<TValue>())
{
}
public TKey Key
{
get
{
return base.Item1;
}
}
public List<TValue> Values
{
get
{
return base.Item2;
}
}
}
View Code
Reduce實現
Reducing函數接收,分組後的數據進行最後的統計計算。
![]()
public Dictionary<T, int> Reducing(IEnumerable<Group<T, int>> groups)
{
Dictionary<T, int> result=new Dictionary<T, int>();
foreach (var sourceVal in groups)
{
result.Add(sourceVal.Key, sourceVal.Values.Sum());
}
return result;
}
View Code
封裝調用如下:
![]()
public IEnumerable<Group<T, int>> Map(IEnumerable<T> list)
{
var step1 = Mapping(list);
var step2 = Combine(step1);
var step3 = Partitioner(step2);
return step3;
}
public Dictionary<T, int> Reduce(IEnumerable<Group<T, int>> groups)
{
var step1 = Reducing(groups);
return step1;
}
View Code
public Dictionary<T, int> MapReduce(IEnumerable<T> list)
{
var map = Map(list);
var reduce = Reduce(map);
return reduce;
}
整體計算步驟圖如下:
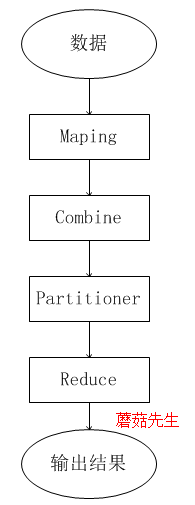
支持分布式
小張抽象封裝後,雖然復雜度上去了。但暴露給使用者是非常清晰的接口,滿足MapReduce的數據格式要求,即可使用。
var spit = hamlet.Split(new[] { " ", Environment.NewLine }, StringSplitOptions.RemoveEmptyEntries);
var mp = new MicroMapReduce<string>(new Master<string>());
var result1= mp.MapReduce(spit);
小張完成後腦洞大開,考慮到以後文本數據量超大。 所以fork了個分支,准備支持分布式計算,以後可以在多個服務器節點跑。
數據分片
數據分片就是把大量數據拆成一塊一塊的,分散到各個節點上,方便我們的mapReduce程序去計算。 分片主流的有mod、consistent hashing、vitual Buckets、Range Partition等方式。 關於consistent hashing上篇有介紹(探索c#之一致性Hash詳解)。在Hadoop中Hdfs和mapreduce是相互關聯配合的,一個存儲和一個計算。如果自行實現的話還需要個統一的存儲。所以這裡的數據源可以是數據庫也可以是文件。小張只是滿足boss需求,通用計算框架的話可以直接用現成的。
模擬分片
![]()
public List<IEnumerable<T>> Partition(IEnumerable<T> list)
{
var temp =new List<IEnumerable<T>>();
temp.Add(list);
temp.Add(list);
return temp;
}
View Code
Worker節點
小張定義了Master,worker角色。 master負責匯集輸出,即我們的主程序。 每一個worker我們用一個線程來模擬,最後輸出到master匯總,master最後可以寫到數據庫或其他。
public void WorkerNode(IEnumerable<T> list)
{
new Thread(() =>
{
var map = Map(list);
var reduce = Reduce(map);
master.Merge(reduce);
}).Start();
}
![]()
public class Master<T>
{
public Dictionary<T, int> Result = new Dictionary<T, int>();
public void Merge(Dictionary<T, int> list)
{
foreach (var item in list)
{
lock (this)
{
if (Result.ContainsKey(item.Key))
Result[item.Key] += item.Value;
else
Result.Add(item.Key, item.Value);
}
}
}
}
View Code
分布式計算步驟圖:
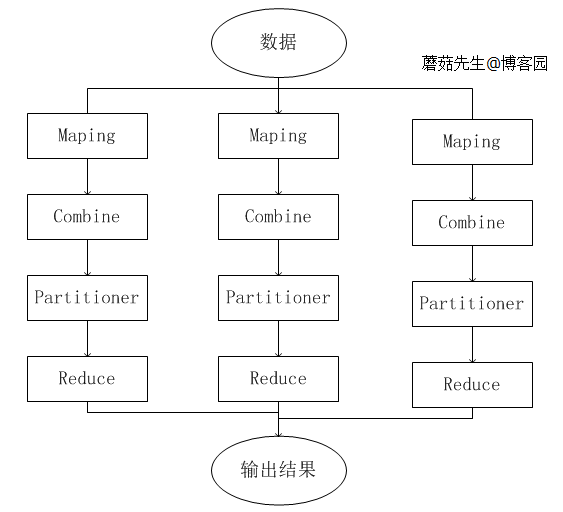
總結
MapReduce模型從性能速度來說並不是非常好的,它優勢在於隱藏了分布式計算的細節、容災錯誤、負載均衡及良好的編程API,包含HDFS、Hive等在內一整套大數據處理的生態框架體系。在數據量級不是很大的話,企業自行實現一套輕量級分布式計算會有很多優點,比如性能更好、可定制化、數據庫也不需要導入導出。從成本上也節省不少,因為hadoop開發、運維、服務器都需要不少人力物力。