C#中幾種序列化的比較,此次比較只是比較了 序列化的耗時和序列後文件的大小。
幾種序列化分別是:
1. XmlSerializer
2. BinaryFormatter
3. DataContractSerializer
4. DataContractJsonSerializer
5. protobuf-net
前四種為.Net 自帶的類庫,最後一種為 Google Protocol Buffers
首先,選做一個實體類,做為序列化的對象,加入了一個可序列化的字典,讓實體類 稍稍的復雜一點。
Code:
[Serializable]
[ProtoContract]
public class User
{
[ProtoMember(1)]
public int ID { get; set; }
[ProtoMember(2)]
public string Name { get; set; }
[ProtoMember(3)]
public int Age { get; set; }
[ProtoMember(4)]
public SerializableDictionary<Guid, Guid> Dictionary { get; set; }
}
[Serializable]
public class SerializableDictionary<TKey, TValue> : Dictionary<TKey, TValue>, IXmlSerializable
{
public void WriteXml(XmlWriter write) // Serializer
{
var keySerializer = new XmlSerializer(typeof(TKey));
var valueSerializer = new XmlSerializer(typeof(TValue));
foreach (KeyValuePair<TKey, TValue> kv in this)
{
write.WriteStartElement("SerializableDictionary");
write.WriteStartElement("key");
keySerializer.Serialize(write, kv.Key);
write.WriteEndElement();
write.WriteStartElement("value");
valueSerializer.Serialize(write, kv.Value);
write.WriteEndElement();
write.WriteEndElement();
}
}
public void ReadXml(XmlReader reader) // Deserializer
{
reader.Read();
var keySerializer = new XmlSerializer(typeof(TKey));
var valueSerializer = new XmlSerializer(typeof(TValue));
while (reader.NodeType != XmlNodeType.EndElement)
{
reader.ReadStartElement("SerializableDictionary");
reader.ReadStartElement("key");
TKey tk = (TKey)keySerializer.Deserialize(reader);
reader.ReadEndElement();
reader.ReadStartElement("value");
TValue vl = (TValue)valueSerializer.Deserialize(reader);
reader.ReadEndElement();
reader.ReadEndElement();
this.Add(tk, vl);
reader.MoveToContent();
}
reader.ReadEndElement();
}
public XmlSchema GetSchema()
{
return null;
}
}
然後,初始化一個集合,有1000個User對象,每個User對象中的字典,有500對Guid
var list = new List<User>();
var random = new Random();
for (int i = 0; i < 1000; i++)
{
var id = random.Next(0, 10000);
var user = new User
{
ID = id,
Name = "Name" + id,
Age = random.Next(1, 100)
};
var dic = new SerializableDictionary<Guid, Guid>();
for (int j = 0; j < 500; j++)
{
dic.Add(Guid.NewGuid(), Guid.NewGuid());
}
user.Dictionary = dic;
list.Add(user);
}
最後,開始序列化,計時用 Stopwatch
1. Xml序列化

2. 二進制序列化
3. DataContractSerializer
4. DataContractJsonSerializer
5. protobuf-net
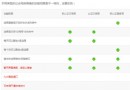
我連續,測了N次,只貼上3次的結果吧:
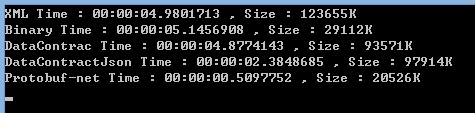
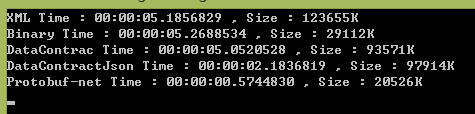
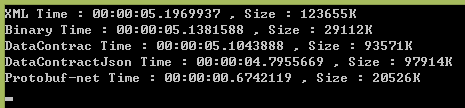
看這個結果,Protobuf-net 無論序列化速度,還是序列化的體積都完勝其他幾種。
此測試只是個人無聊而為,如果有不合理的地方,請大家指出來。
main()
{
int i,j,temp;
int a[10];
for(i=0;i<10;i++)
scanf ("%d,",&a[i]);
for(j=0;j<=9;j++)
{ for (i=0;i<10-j;i++)
if (a[i]>a[i+1])
{ temp=a[i];
a[i]=a[i+1];
a[i+1]=temp;}
}
for(i=1;i<11;i++)
printf("%5d,",a[i] );
printf("\n");
}
--------------
冒泡算法
冒泡排序的算法分析與改進
交換排序的基本思想是:兩兩比較待排序記錄的關鍵字,發現兩個記錄的次序相反時即進行交換,直到沒有反序的記錄為止。
應用交換排序基本思想的主要排序方法有:冒泡排序和快速排序。
冒泡排序
1、排序方法
將被排序的記錄數組R[1..n]垂直排列,每個記錄R看作是重量為R.key的氣泡。根據輕氣泡不能在重氣泡之下的原則,從下往上掃描數組R:凡掃描到違反本原則的輕氣泡,就使其向上"飄浮"。如此反復進行,直到最後任何兩個氣泡都是輕者在上,重者在下為止。
(1)初始
R[1..n]為無序區。
(2)第一趟掃描
從無序區底部向上依次比較相鄰的兩個氣泡的重量,若發現輕者在下、重者在上,則交換二者的位置。即依次比較(R[n],R[n-1]),(R[n-1],R[n-2]),…,(R[2],R[1]);對於每對氣泡(R[j+1],R[j]),若R[j+1].key<R[j].key,則交換R[j+1]和R[j]的內容。
第一趟掃描完畢時,"最輕"的氣泡就飄浮到該區間的頂部,即關鍵字最小的記錄被放在最高位置R[1]上。
(3)第二趟掃描
掃描R[2..n]。掃描完畢時,"次輕"的氣泡飄浮到R[2]的位置上……
最後,經過n-1 趟掃描可得到有序區R[1..n]
注意:
第i趟掃描時,R[1..i-1]和R[i..n]分別為當前的有序區和無序區。掃描仍是從無序區底部向上直至該區頂部。掃描完畢時,該區中最輕氣泡飄浮到頂部位置R上,結果是R[1..i]變為新的有序區。
2、冒泡排序過程示例
對關鍵字序列為49 38 65 97 76 13 27 49的文件進行冒泡排序的過程
3、排序算法
(1)分析
因為每一趟排序都使有序區增加了一個氣泡,在經過n-1趟排序之後,有序區中就有n-1個氣泡,而無序區中氣泡的重量總是大於等於有序區中氣泡的重量,所以整個冒泡排序過程至多需要進行n-1趟排序。
若在某一趟排序中未發現氣泡位置的交換,則說明待排序的無序區中所有氣泡均滿足輕者在上,重者在下的原則,因此,冒泡排序過程可在此趟排序後終止。為此,在下面給出的算法中,引入一個布爾量exchange,在每趟排序開始前,先將其置為FALSE。若排序過程中發生了交換,則將其置為TRUE。各趟排序結束時檢查exchange,若未曾發生過交換則終止算法,不再進行下一趟排序。
(2)具體算法
void BubbleSort(SeqList R)
{ //R(l..n)是待排序的文件,采用自下向上掃描,對R做冒泡排序
int i,j;
Boolean exchange; //交換標志
for(i=1;i&......余下全文>>
main()
{
int i,j,temp;
int a[10];
for(i=0;i<10;i++)
scanf ("%d,",&a[i]);
for(j=0;j<=9;j++)
{ for (i=0;i<10-j;i++)
if (a[i]>a[i+1])
{ temp=a[i];
a[i]=a[i+1];
a[i+1]=temp;}
}
for(i=1;i<11;i++)
printf("%5d,",a[i] );
printf("\n");
}
--------------
冒泡算法
冒泡排序的算法分析與改進
交換排序的基本思想是:兩兩比較待排序記錄的關鍵字,發現兩個記錄的次序相反時即進行交換,直到沒有反序的記錄為止。
應用交換排序基本思想的主要排序方法有:冒泡排序和快速排序。
冒泡排序
1、排序方法
將被排序的記錄數組R[1..n]垂直排列,每個記錄R看作是重量為R.key的氣泡。根據輕氣泡不能在重氣泡之下的原則,從下往上掃描數組R:凡掃描到違反本原則的輕氣泡,就使其向上"飄浮"。如此反復進行,直到最後任何兩個氣泡都是輕者在上,重者在下為止。
(1)初始
R[1..n]為無序區。
(2)第一趟掃描
從無序區底部向上依次比較相鄰的兩個氣泡的重量,若發現輕者在下、重者在上,則交換二者的位置。即依次比較(R[n],R[n-1]),(R[n-1],R[n-2]),…,(R[2],R[1]);對於每對氣泡(R[j+1],R[j]),若R[j+1].key<R[j].key,則交換R[j+1]和R[j]的內容。
第一趟掃描完畢時,"最輕"的氣泡就飄浮到該區間的頂部,即關鍵字最小的記錄被放在最高位置R[1]上。
(3)第二趟掃描
掃描R[2..n]。掃描完畢時,"次輕"的氣泡飄浮到R[2]的位置上……
最後,經過n-1 趟掃描可得到有序區R[1..n]
注意:
第i趟掃描時,R[1..i-1]和R[i..n]分別為當前的有序區和無序區。掃描仍是從無序區底部向上直至該區頂部。掃描完畢時,該區中最輕氣泡飄浮到頂部位置R上,結果是R[1..i]變為新的有序區。
2、冒泡排序過程示例
對關鍵字序列為49 38 65 97 76 13 27 49的文件進行冒泡排序的過程
3、排序算法
(1)分析
因為每一趟排序都使有序區增加了一個氣泡,在經過n-1趟排序之後,有序區中就有n-1個氣泡,而無序區中氣泡的重量總是大於等於有序區中氣泡的重量,所以整個冒泡排序過程至多需要進行n-1趟排序。
若在某一趟排序中未發現氣泡位置的交換,則說明待排序的無序區中所有氣泡均滿足輕者在上,重者在下的原則,因此,冒泡排序過程可在此趟排序後終止。為此,在下面給出的算法中,引入一個布爾量exchange,在每趟排序開始前,先將其置為FALSE。若排序過程中發生了交換,則將其置為TRUE。各趟排序結束時檢查exchange,若未曾發生過交換則終止算法,不再進行下一趟排序。
(2)具體算法
void BubbleSort(SeqList R)
{ //R(l..n)是待排序的文件,采用自下向上掃描,對R做冒泡排序
int i,j;
Boolean exchange; //交換標志
for(i=1;i&......余下全文>>