接上篇繼續,本文的完整源代碼也在上篇文章中。
枚舉數組和普通枚舉性能差異
有些人可能知道,.net在處理枚舉時,對於數組有特別的優化,所以,當枚舉的集合是一個數組時,性能會好些。例如下面的測試代碼:
1 class C1 {
2
3 public void Do1() {
4 int[] array = { 1, 2, 3, 4 };
5 for (int i = 0; i < int.MaxValue/100; i++) {
6 DoIt1(array);
7 }
8 }
9
10 private void DoIt1<T>(IEnumerable<T> array) {
11 foreach (var item in array) {
12
13 }
14 }
15
16 public void Do2() {
17 int[] array = { 1, 2, 3, 4 };
18 for (int i = 0; i < int.MaxValue/100; i++) {
19 DoIt2(array);
20 }
21 }
22
23 private void DoIt2(int[] array) {
24 foreach (var item in array) {
25
26 }
27 }
28 }
第23行的方法中,編譯器提前已知是一個數組的枚舉,所以會優化指令。那麼,到底這種優化差距有多大呢?我需要試驗一下。

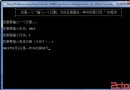
第一個是Do1的結果,第二個是Do2的結果,顯而易見,差距還是相當大的,為什麼呢?從反編譯的IL代碼來看,第一個方法使用標准的GetEnumerator機制,需要創建實例,而且要調用Current和MoveNext兩個方法,更何況,Array的GetValue實現實在不夠快。而第二個方法使用了for的機制,無需創建實例,不斷累加和一個判斷語句即可,性能當然高了。
在Linq to Object中,其實是有這樣考慮的代碼的。例如:
public static IEnumerable<TResult> Select<TSource, TResult>(this IEnumerable<TSource> source, Func<TSource, TResult> selector)
{
if (source == null)
{
throw Error.ArgumentNull("source");
}
if (selector == null)
{
throw Error.ArgumentNull("selector");
}
if (source is Enumerable.Iterator<TSource>)
{
return ((Enumerable.Iterator<TSource>)source).Select<TResult>(selector);
}
if (source is TSource[])
{
return new Enumerable.WhereSelectArrayIterator<TSource, TResult>((TSource[])source, null, selector);
}
if (source is List<TSource>)
{
return new Enumerable.WhereSelectListIterator<TSource, TResult>((List<TSource>)source, null, selector);
}
return new Enumerable.WhereSelectEnumerableIterator<TSource, TResult>(source, null, selector);
}
創建類和結構的性能差異以及屬性和字段的性能差異 www.2cto.com
下面我還要試驗創建類實例和結構類型,其性能差異到底有多大?會不會.net的垃圾回收超級厲害,基本上差異不大呢?當然,我也順手測試了訪問屬性和訪問字段的差別。
1 class C1 {
2 public void Do1() {
3 for (int i = 0; i < int.MaxValue/10; i++) {
4 var p = new PointClass() { X = 1, Y = 2 };
5 }
6 }
7 public void Do2() {
8 for (int i = 0; i < int.MaxValue/10 ; i++) {
9 var p = new PointClass2() { X = 1, Y = 2 };
10 }
11 }
12 public void Do3() {
13 for (int i = 0; i < int.MaxValue/10; i++) {
14 var p = new Point() { X = 1, Y = 2 };
15 }
16 }
17 public void Do4() {
18 for (int i = 0; i < int.MaxValue / 10; i++) {
19 var p = new Point() { XP = 1, YP = 2 };
20 }
21 }
22 }
23
24
25 class PointClass {
26 public int X { get; set; }
27 public int Y { get; set; }
28 }
29
30 class PointClass2 {
31 public int X;
32 public int Y;
33 }
34
35 struct Point {
36 public int X;
37 public int Y;
38
39 public int XP { get { return X; } set { X = value; } }
40 public int YP { get { return Y; } set { Y = value; } }
41 }
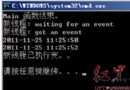
測試結果如下:
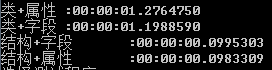
實驗結果表明:在計算密集型的程序中,結構的創建仍然比類要高效的多,另外,屬性和字段的訪問其性能基本相當。
摘自 編寫人生