本節主要介紹,在GIX4系統中,如何應用上篇講的方案來改善性能,如果與現有的系統環境集成在一起。大致包含以下內容:
SQL的生成
映射-數據讀取方案
工廠方法-接口的命名約定
實例代碼
SQL生成
GIX4系統中的所有領域模型及分布式訪問機制,使用CSLA作為底層框架。而ORM機制,使用了一個非常輕量級的開源代碼LiteORM實現。 模型類的定義,采用以下的格式:
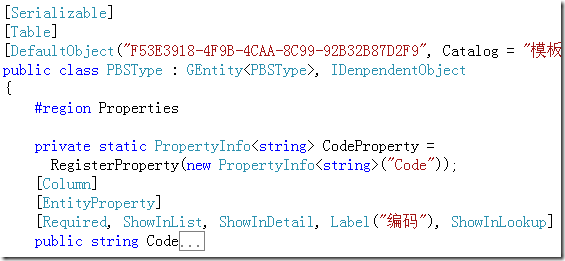
可以看到,在類的元數據定義中(這裡目前使用的是Attribute的形式),已經包含了對應數據表和列的信息。所以為SQL的自動化自成 提供了一定的支持。
其實,由於目前對性能要求比較高的模塊少,所以用於優化查詢的SQL主要還是依靠人工手寫。但是由於LiteORM框架的功能比較有限, 所以這裡查詢出來的表格數據需要由我們自己來進行讀取並封裝對象。考慮到:1. 多表連接時,列名可能會重復;2. 添加/刪除列時,不 要更改手寫的SQL。所以至少列名應該自動生成,並不重復。我們把生成列名SQL的API都放在了所有模型的基類GEntity<T>中,如下 :
[Serializable]
public abstract class GEntity<T> : Entity<T>
where T : GEntity<T>
{
#region 直接與數據行進行交互
/// <summary>
/// 直接從數據集中取數據。
///
/// 注意:
/// 數據集中的列字段約定為:“表名_列名”,如“PBS_Name”。
/// 默認使用反射創建對象並讀取數據!同“LiteORM”。
///
/// 意義:
/// 由於各個類的列名不再相同,所以這個方法的意義在於可以使用一句復雜的組合SQL加載一個聚合對象!
/// </summary>
/// <param name="rowData">
/// 這個數據集中的列字段約定為:“表名_列名”,如“PBS_Name”。
/// </param>
/// <returns>
/// 如果id值為null,則返回null。
/// </returns>
public static T ReadDataDirectly(DataRow rowData)
/// <summary>
/// 獲取可用於ReadDirectly方法讀取的列名表示法。如:
/// PBS.Id as PBS_Id, PBS.Name as PBS_Name, ........
/// </summary>
/// <returns></returns>
public static string GetReadableColumnsSql()
/// <summary>
/// 獲取可用於ReadDirectly方法讀取的列名表示法。如:
/// p.Id as PBS_Id, p.Name as PBS_Name, ........
/// </summary>
/// <param name="tableAlias">表í的?別e名?</param>
/// <returns></returns>
public static string GetReadableColumnsSql(string tableAlias)
/// <summary>
/// 獲取columnName在DataRow中使用時約定的列名。
/// </summary>
/// <param name="columnName"></param>
/// <returns></returns>
public static string GetReadableColumnSql(string columnName)
public static ITable GetTableInfo()
{
//這裡加載表信息時,可能需要和服務器交互。
if (Helper.IsOnServer())
{
return GetTableInfo_OnServer();
}
else
{
return GetTableInfo_OnClient();
}
}
#endregion
例如,一個比較簡單的聚合SQL如下:
private static readonly string SQL_GET_PBS_BY_PBSTYPE_WITH_PROPERTIES = string.Format(@"
select
{0},
{1},
{2}
from PBS pbs
left outer join PBSProperty p on pbs.Id = p.PBSId
left outer join PBSPropertyOptionalValue v on p.Id = v.PBSPropertyId
where pbs.PBSTypeId = '{{0}}'
order by pbs.Id, p.Id"
, PBS.GetReadableColumnsSql()
, PBSProperty.GetReadableColumnsSql("p")
, PBSPropertyOptionalValue.GetReadableColumnsSql("v"));
這個SQL格式生成的結果存儲在靜態字段中,不需要每次都生成。最後生成的SQL語句如下:
select
pbs.pid as pbs_pid, pbs.pbstypeid as pbs_pbstypeid, pbs.code as pbs_code, pbs.name as pbs_name, pbs.description as pbs_description, pbs.orderno as pbs_orderno, pbs.id as pbs_id,
p.pbsid as pbsproperty_pbsid, p.code as pbsproperty_code, p.orderno as pbsproperty_orderno, p.pid as pbsproperty_pid, p.name as pbsproperty_name, p.unit as pbsproperty_unit, p.valuetype as pbsproperty_valuetype, p.editortype as pbsproperty_editortype, p.calcitemtype as pbsproperty_calcitemtype, p.isusedtoquery as pbsproperty_isusedtoquery, p.isrequired as pbsproperty_isrequired, p.isusedtosummarize as pbsproperty_isusedtosummarize, p.id as pbsproperty_id,
v.pbspropertyid as pbspropertyoptionalvalue_pbspropertyid, v.value as pbspropertyoptionalvalue_value, v.description as pbspropertyoptionalvalue_description, v.id as pbspropertyoptionalvalue_id
from PBS pbs
left outer join PBSProperty p on pbs.Id = p.PBSId
left outer join PBSPropertyOptionalValue v on p.Id = v.PBSPropertyId
where pbs.PBSTypeId = '{0}'
order by pbs.Id, p.Id
映射-數據讀取方案
SQL已經生成了,接下來就是把整個一張大表讀取為對應的聚合對象。按照以上SQL讀取出來的數據表的格式,類似於以下形式:
TableA TableB TableC TableD...
a1 b1 c1 d1
a1 b1 c2 NULL
a1 b2 c3 NULL
a1 b3 NULL NULL
a2 b4 c5 NULL
a2 b5 NULL NULL
a3 NULL NULL NULL
它是TableA的查詢結果。對應每一個TableA的行,都有一個更小的表與之對應。如下圖:
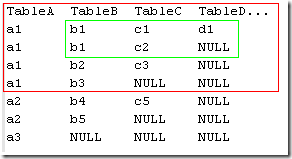
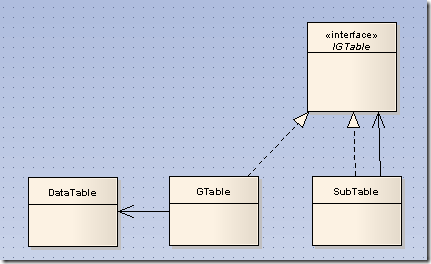
a1在整個大表中,對應紅線框住的表。b1,b2,b3是它的關系對象,而對應b1的子表是綠線框住的更小的表,c1,c2是b1的關系對象。所 以在讀取這樣的數據時,使用裝飾模式定義了一個虛擬的IGTable:
/// <summary>
/// 一個存儲表格數據的對象
///
/// 注意:
/// 以此為參數的方法只能在服務端執行
/// </summary>
public interface IGTable
{
/// <summary>
/// 行數
/// </summary>
int Count { get; }
/// <summary>
/// 獲取指定的行。
/// </summary>
/// <param name="rowIndex"></param>
/// <returns></returns>
DataRow this[int rowIndex] { get; }
}
GTable是從DataTable適配到IGTable的“適配器”。SubTable表示某一個IGTable的子表。定義如下:
/// <summary>
/// 封裝了DataRowCollection的一般Table
/// </summary>
public class GTable : IGTable
{
private DataRowCollection _table;
public GTable(DataTable table){…}
}
/// <summary>
/// 這是個子表格。
///
/// 它表示的是某一表格中的一些指定的行。
/// </summary>
public class SubTable : IGTable
{
private IGTable _table;
private int _startRow;
private int _endRow;
/// <summary>
/// 構造一個指定table的子表。
/// </summary>
/// <param name="table"></param>
/// <param name="startRow">這個表在table中的開始行。</param>
/// <param name="endRow">這個表在table中的結束行。</param>
public SubTable(IGTable table, int startRow, int endRow){…}
}
定義好被讀取的數據的結構後,按照剛才劃分子表的邏輯,並調用T GEntity<T>.ReadDataDirectly(DataRow)方法生成所 有對象即可:
public static class EntityListHelper
{
/// <summary>
/// 這個方法把table中的數據全部讀取並轉換為對象存入對象列表中。
///
/// 算法簡介:
/// 由於子對象的數據都是存儲在這個IGTable中,所以每一個TEntity可能對應多個行,
/// 每一行數據其實就是一個子對象的數據,而TEntity的屬性值是重復的。
/// 所以這裡找到每個TEntity對應的第一行和最後一行,把它封裝為一個子表格,傳給子對象集合進行加載。
/// 這樣的設計是為了實現重用這個方法:集合加載IGTable中的數據。
/// </summary>
/// <typeparam name="TCollection"></typeparam>
/// <typeparam name="TEntity"></typeparam>
/// <param name="list">轉換的對象存入這個列表中</param>
/// <param name="table">
/// 表格數據,數據類型於以下形式:
/// TableA TableB TableC TableD...
/// a1 b1 c1
/// a1 b1 c2
/// a2 b2 c3
/// a2 b3 NULL
/// a3 NULL NULL
/// ...
/// </param>
/// <param name="relationLoader">
/// 為每個TEntity調用此方法,從IGTable中加載它對應的孩子對象。
/// 加載完成後的對象會被加入到list中,所以此方法有可能返回一個全新的TEntity。
/// </param>
public static void ReadFromTable<TCollection, TEntity>(TCollection list, IGTable table, Func<TEntity, IGTable, TEntity> relationLoader)
where TCollection : GBusinessListBase<TCollection, TEntity>
where TEntity : GEntity<TEntity>
{
list.RaiseListChangedEvents = false;
Guid? lastId = null;
//每個TEntity對象對應的第一行數據
int startRow = 0;
for (int i = 0, c = table.Count; i < c; i++)
{
var row = table[i];
string idName = GEntity<TEntity>.GetReadableColumnSql("Id");
var objId = row[idName];
Guid? id = objId != DBNull.Value ? (Guid)objId : (Guid?)null;
//如果 id 改變,表示已經進入到下一個 TEntity 對象的開始行了。
if (id != lastId)
{
//不是第一次
if (lastId.HasValue)
{
//前一行就是最後一行。
int endRow = i - 1;
TEntity item = CreateEntity<TEntity>(table, startRow, endRow, relationLoader);
list.Add(item);
//重置 startRow 為下一個 TEntity
startRow = i;
}
}
lastId = id;
}
//加入最後一個 Entity
if (lastId.HasValue)
{
TEntity lastEntity = CreateEntity<TEntity>(table, startRow, table.Count - 1, relationLoader);
list.Add(lastEntity);
}
//完畢,退出
list.RaiseListChangedEvents = true;
}
/// <summary>
/// 把 table 從 startRow 到 endRow 之間的數據,都轉換為一個 TEntity 並返回。
/// </summary>
private static TEntity CreateEntity<TEntity>(IGTable table, int startRow, int endRow, Func<TEntity, IGTable, TEntity> relationLoader) where TEntity : GEntity<TEntity>
{
//新的TEntity
TEntity item = GEntity<TEntity>.ReadDataDirectly(table[startRow]);
Debug.Assert(item != null, "id不為空,對象也不應該為空。");
var childTable = new SubTable(table, startRow, endRow);
item = relationLoader(item, childTable);
return item;
}
}
這段代碼中最關鍵的地方是relationLoader的定義,這個方法傳入一個Entity和其對應的所有行,由它自己再來調用關系對象類的方法 讀取行並生成最後的Entity返回。在後面,我會給出一個較完事的例子。
工廠方法-命名約定:
其實,Linq To Sql 已經提供了API支持此類操作:LoadWith,AssociateWith。在使用它作為數據層的應用中,可以輕松的實現聚合加 載。但是當你處在多層應用中時,為了不破壞數據訪問層的封裝性,該層接口的設計是不會讓上層知道目前在使用何種ORM框架進行查詢。 可是,數據層到底要加載哪些關系數據,又必須由上層的客戶程序在接口中以某種形式進行標注。為了讓數據層的接口設計保持語意的明 朗,我們可以考慮使用和LinqToSql相同的方案,使用表達式作為接口的參數。這樣,在使用的時候,可以這樣寫:
Expression<Func<Article,Object>> loadOptions = a => a.User;
ArticlesRepository.Get(new PagerInfo(), loadOptions)
但是,LinqToSql、EF等框架雖然能提高開發效率,但是性能卻不好,特別是Web項目,更是要謹慎用之。我推薦在項目上線的前期使用 它們,因為這時候性能要求不高,而人力資源又比較緊張;而當性能要求較高時,再優化庫,換為高效率的SQL實現查詢。
按照上面的設計,當後期項目不再使用ORM框架,而使用SQL/存儲過程實現接口時,要實現如 ArticlesRepository.Get (Expression<Func<Article,Object>> loadOptions)一樣靈活的接口,是件非常困難的事!而且其實上次使用的場景比較少 ,不會使用如此“寬廣”的接口。所以我們在這裡對接口的功能進行了限制,不需要為有限的查詢設計無限的接口。在我們的項目中,使 用如下的命名約定來定義方法:
GetArticles_With_User
GetPBSTypes_With_PBSTree
同時,在注釋上寫明此方法查詢出的對象所附帶的關系對象。
例子
我現在給出一個較完整的加載過程的代碼,這個代碼是GIX4項目中的實例:
數據訪問層:
//此方法在客戶端執行。
public static PBSs GetListByPBSTypeId_With_Properties(Guid pbsTypeId)
{
//開始調用遠程對象的DataPortal_Fetch方法
return DataPortal.Fetch<PBSs>(new GetListCriteria_With_Properties(pbsTypeId));
}
//以下所有方法在服務端執行
private void DataPortal_Fetch(GetListCriteria_With_Properties criteria)
{
var pbsTypeId = criteria.PBSTypeId;
var sql = string.Format(SQL_GET_PBS_BY_PBSTYPE_WITH_PROPERTIES, pbsTypeId);
using (var db = Helper.CreateDb())
{
IGTable table = db.QueryTable(sql);
this.ReadFromTable(table, PBS.GetChild_With_Properties);
}
}
注意到傳入的委托是PBS.GetChild_With_Properties,正是上文提到的relationLoader,接著看:
public class PBS : GTreeEntity<PBS>, IDisplayModeL
{
public static PBS GetChild_With_Properties(PBS pbs, IGTable subTable)
{
pbs = GetChild(pbs);//獲取一個新的對象,並從參數中拷貝數據。
//同時,加載PBS的Properties屬性。
var properties = PBSPropertys.GetChild_WithValues(pbs, subTable);
pbs.LoadProperty(PBSPropertysProperty, properties);
return pbs;
}
}
public class PBSPropertys : GEntityTreeList<PBSPropertys, PBSProperty>
{
public static PBSPropertys GetChild_WithValues(PBS pbs, IGTable table)
{
var properties = GetChild();
properties.ReadFromTable(table, PBSProperty.GetChild_With_Values);
foreach (var property in properties)
{
property.PBS = pbs;
}
//排序
var result = GetChild();
result.AddRange(properties.OrderBy(p => p.OrderNo));
return result;
}
}
public class PBSProperty : GEntity<PBSProperty>, ITreeNode, IOrderedObject
{
public static PBSProperty GetChild_With_Values(PBSProperty property, IGTable table)
{
var model = GetChild(property);
var values = PBSPropertyOptionalValues.GetChild(model, table);
model.LoadProperty(PBSPropertyOptionalValuesProperty, values);
return model;
}
}
public partial class PBSPropertyOptionalValues : GEntityList<PBSPropertyOptionalValues, PBSPropertyOptionalValue>
{
internal static PBSPropertyOptionalValues GetChild(PBSProperty parent, IGTable table)
{
var values = GetChild();
values.ReadFromTable(table);
foreach (var value in values)
{
value.PBSProperty = parent;
}
return values;
}
}
調用關系如下:
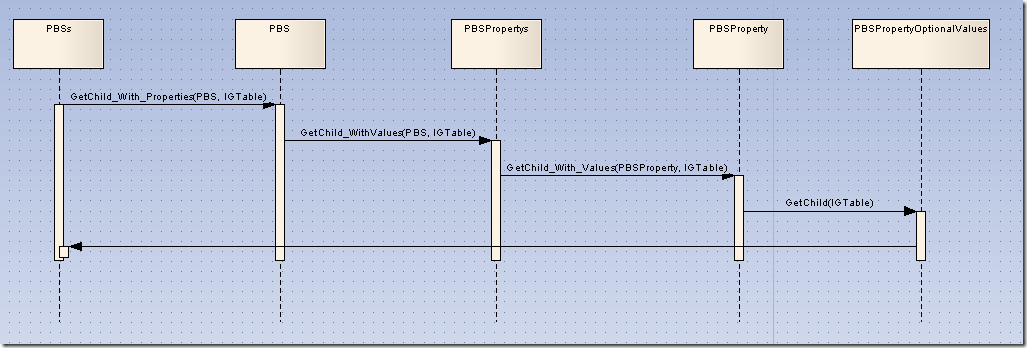
客戶程序調用方法如下:
var pbsList = PBSs.GetListByPBSTypeId_With_Properties(id);
foreach (var pbs in pbsList)
{
foreach (var property in pbs.PBSPropertys)
{
foreach (var optionalValue in property.PBSPropertyOptionalValues)
{
//......
}
}
}
這裡雖然客戶程序使用了多次循環,但是由於在獲取數據時我們已經指定了,在加載PBS的時候,把每個PBS的PBS屬性和屬性值都帶上 ,所以這裡也只有一次數據/遠程訪問。
使用場景
聚合SQL優化查詢次數的模式,已經被我在多個項目中使用過。它一般被使用在對項目進行重構/優化的場景中。原因是:在一開始編寫 數據層代碼時,其中我們不知道上層在使用時會需要它的哪些關系對象。只有當某個業務邏輯的流程寫完了,然後再對它進行分析時,才 會發現它在一次執行過程中,到底需要哪些數據。這時,如果需要對它進行優化,我們就可以有的放矢地寫出聚合SQL,並映射為帶有關系 的對象了。
小結
本節主要講了GIX4中的聚合SQL的應用。
下一節開始講在本次優化過程中,使用的另一個技術:預加載。主要說下我們的預加載需求及對應的API設計,可能會附帶說下.NET4.0 並行庫在系統中的應用。