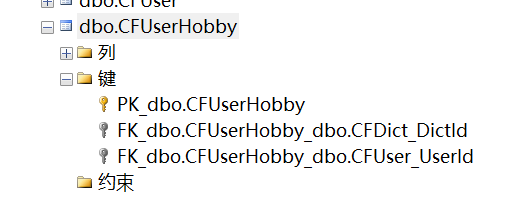
自 CLR 2.0 後,最新版本 (CLR 4.0) 中的 CLR ThreadPool 已經過多次重大 更改。 最近的技術趨勢轉變(例如廣泛應用多核體系結構以及由此產生的並行化 現有應用程序或編寫新並行代碼的需求)已成為 CLR ThreadPool 改進中最重要 的決定性因素之一。
在 MSDN 雜志 2008 年 12 月刊的 CLR 全面透析專欄“CLR 中的線程管理” (msdn.microsoft.com/magazine/dd252943) 中,我介紹了一些動機和相關問題, 例如並發控制和干擾信息。
現在,我將介紹 CLR 4.0 ThreadPool 中解決這些問題的方式、相關的實現選 項以及這些選項對其行為的影響。
同時,我還將重點介紹當前 CLR 4.0 ThreadPool(為了方便起見,下文簡稱 ThreadPool)中實現自動化並發控制的方法。
我還將簡要地概述 ThreadPool 體系結構。
本文中介紹的實現細節在未來版本中有可能發生變更。
不過,對於設計和編寫新並發應用程序的讀者而言,如果他們正在致力於利用 並發技術改進舊應用程序,或者使用 ASP.NET 或並行擴展技術(所有這些都在 CLR 4.0 上下文中實現),他們會發現本文對於理解和利用當前 ThreadPool 行 為非常有用。
ThreadPool 概述 線程池用來提供重要服務,例如線程管理、不同類型的並發 的抽象性以及並發操作的限制。
通過提供這些服務,線程池可以減輕用戶的負擔,使他們無需手動執行這些操 作。
對於無經驗的用戶而言,線程池是非常方便的,他們不需要學習和掌握多線程 環境的細節。
對於經驗豐富的用戶而言,擁有可靠的線程系統就意味著用戶可以將精力集中 在改進應用程序的各種功能上。
ThreadPool 為托管應用程序提供這些服務,並且提供跨平台可移植性支持( 例如,在 Mac OS 上運行特定 Microsoft .NET Framework 應用程序的平台)。
有各種不同類型的並發可以與系統的不同部分相關。 最相關的部分包括:CPU 並行性、I/O 並行性、計時器和同步、負載平衡和資源利用率。
我們可以針對並發的不同方面,簡要地概述 ThreadPool 的體系結構。有關 ThreadPool 體系結構和相關 API 使用的詳細信息,請參閱“CLR 的線程池” (msdn.microsoft.com/magazine/cc164139)。
尤其值得一提的是,有兩種獨立的 ThreadPool 實現:一種用來處理 CPU 並 行性,稱為工作線程 ThreadPool;另一種用來處理 I/O 並行性,稱為 I/O ThreadPool。
下一部分將重點介紹 CPU 並行性和 ThreadPool 中的相關實現工作,特別是 關於並發限制的策略。
工作線程 ThreadPool:旨在提供 CPU 並行性級別的服務,它利用多核體系結 構。
CPU 並行性有兩個主要的考慮因素:以優化的方式快速調度工作;以及限制並 行度。 對於前者,ThreadPool 實現利用無鎖定隊列這樣的策略來避免爭用和工 作竊取,以便實現負載平衡,這些領域超出了本文的討論范圍(要進一步了解這 些主題,請參閱 msdn.microsoft.com/magazine/cc163340)。
後者(即並行度限制)使並行度控制可以防止由於資源爭用而導致總體吞吐量 下降。 CPU 並行性處理起來非常棘手,因為它涉及到許多參數,例如確定在任意 給定時間有多少工作項可以同時運行。
另外一些問題是內核數以及如何針對不同類型的工作負載進行優化。
例如,理論上每個 CPU 一個線程是最優的,但如果工作負載經常發生阻塞, 就會浪費 CPU 時間,因為其他線程可以使用這些資源來執行更多工作。
工作負載的大小和類型實際上是另一個參數。
例如,如果發生工作負載阻塞的情況,要確定使總體吞吐量達到最優的線程數 是非常困難的,因為很難確定一個請求的完成時間(甚至可能很難確定請求到達 的頻率,這與 I/O 阻塞是密切相關的)。
與此 ThreadPool 相關的 API 是 QueueUserWorkItem,它使方法(工作項) 排隊等待執行(請參閱 msdn.microsoft.com/library/system.threading.threadpool.queueuserworkite m)。 建議將可能以這種方式工作的應用程序並行運行(與其他項一起)。
具體工作由 ThreadPool 處理,它將自動“計算”運行時間。 這一功能減輕 了編程人員的負擔,使他們無需擔心創建線程的方式和時間;不過,它並不是適 用於所有場景的最有效的解決方案。
I/O ThreadPool:這部分的 ThreadPool 實現與 I/O 並行性有關,它負責處 理阻塞的工作負載(即,服務時間相對較長的 I/O 請求)或異步 I/O。
在異步調用中,線程不會發生阻塞,並且在處理請求期間可以繼續執行其他工 作。
此 ThreadPool 負責在請求和線程之間進行協調。
I/O ThreadPool 與工作線程 ThreadPool 類似,使用並發限制算法;它根據 異步操作完成率控制線程數。
不過,此算法與工作線程 ThreadPool 中的算法完全不同,相關內容不在本文 檔討論范圍內。
ThreadPool 中的並發 處理並發是一項困難但又必不可少的任務,它直接影響 系統的整體性能。
系統限制並發的方式會直接影響到其他任務,例如同步、資源利用和負載平衡 ,反之亦然。 “並發控制”(更准確地說,應該是“並發限制”)的概念是指在 特定時間,允許在 ThreadPool 中執行工作的線程數;這是一種決定同時運行多 少線程而不會損害性能的策略。
我們只討論與工作線程 ThreadPool 有關的並發控制。
並發控制並不是直觀的,它與限制 和減少 可並行運行的工作項數量有關,這 樣做的目的是為了改進工作線程 ThreadPool 吞吐量(即,控制並發度是為了阻 止工作項運行)。 ThreadPool 中的並發控制算法會自動選擇並發級別;它為用 戶決定需要運行多少線程來保持性能在整體上達到最優。
此算法的實現是 ThreadPool 中最復雜、也最吸引人的部分之一。
有多種方法可以在並發級別上下文中優化 ThreadPool 的性能(也就是說,確 定“正確的”同時運行的線程數)。
在下一部分中,我將介紹其中一些方法,這些方法曾考慮在 CLR 中使用或者 已在使用。
ThreadPool 中的並發控制的發展 最先采用的方法之一是根據觀察到的 CPU 利用率進行優化,然後增加 線程以最大程度地提高 CPU 利用率,即運行盡可能 多的工作,使 CPU 處於繁忙狀態。
在處理長時間運行的工作負載或不確定的工作負載時,將 CPU 利用率作為一 項度量是非常有用的。
不過,由於評估度量的標准可能會產生誤導,因此這種方法不太合適。 例如 ,請考慮一下發生大量內存分頁的應用程序。
觀察到的 CPU 利用率會非常低,而在這種情況下增加更多線程會導致使用更 多內存,這樣又會導致 CPU 利用率變得更低。
此方法的另一個問題是,在存在許多爭用的情況下,CPU 時間實際上用在同步 上,而不是執行實際工作上,因此增加線程只會使情況更糟。
另外一種觀點是讓操作系統負責並發級別。
實際上,這是 I/O ThreadPool 的工作,但工作線程 ThreadPool 要求更高級 別的抽象性,以便提供更好的可移植性並且對資源進行更有效的管理。
這種方法可能在某些場景中適用,但編程人員仍然需要了解如何進行限制,以 避免資源過飽和。例如,如果創建了數以千計的線程,資源爭用會成為一個大問 題,而增加線程實際上會使情況變得更糟。
此外,這意味著編程人員仍然必須考慮並發問題,而這違背了使用線程池的初 衷。
最近提出的方法是引入吞吐量概念,測量每個時間單位內完成的工作項,然後 將它作為一項優化性能的度量。
在這種方法中,當 CPU 利用率非常低時 ,增加線程來查看是否能夠改善吞吐量。
如果可以,則增加更多線程;如 果不能,則刪除線程。
這種方法比前面的方法更加合理,因為它考慮了完 成的工作量,而不僅僅是資源的使用方式。
不幸地是,吞吐量受到許多因 素的影響,而不只是活動線程數(例如,工作項大小),這使得優化吞吐量變得 非常困難。
為了克服以前實現中的某些局限,CLR 4.0 中引入了一些新概 念。
考慮的第一種方法來自控制理論領域,即爬山 (HC) 算法。
此技術是一種根據輸入/輸出反饋循環自動進行優化的方法。
在一個較小 的時間間隔內監視和測量系統輸出,查看哪些因素影響到受控制的輸入,然後將 該信息反饋給算法,以便進一步優化輸入。
使用輸入和輸出作為變量,以 函數的方式對系統進行建模。
目標是優化測量的輸出。
在工作線 程 ThreadPool 系統的上下文中,輸入是同時執行工作的線程數(即並發級別) ,而輸出是吞吐量(請參閱圖 1)。
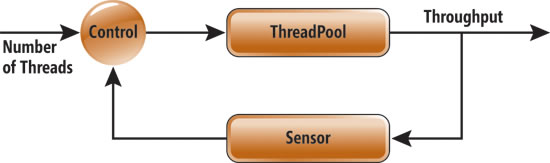
圖 1 ThreadPool 反饋循環 我們觀察並測量一段時間內增加或刪除線 程導致的吞吐量變化,然後根據觀察到的吞吐量下降或提高,確定是增加還是刪 除線程。
圖 2 說明了這一概念。
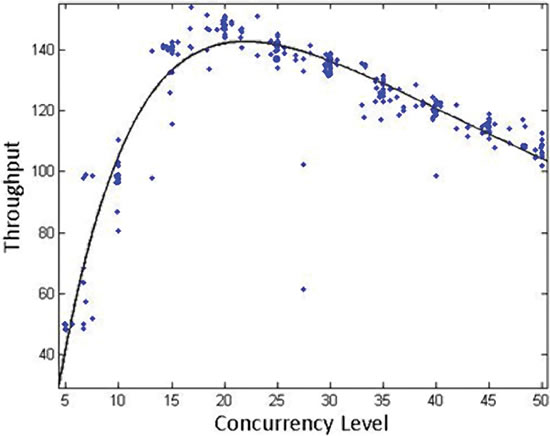
圖 2
以並發級別函數的形式建模的吞吐量 將吞吐量作為並發級別的(多項式 )函數後,該算法會增加線程,直至達到函數的最大值(在本示例中大約為 20) 。 此時,吞吐量將會下降,而算法將會刪除線程。 在每個時間間隔中 ![]() 對吞吐量度量進行采樣並“計算平均值”。然後,使用該值來針對下 一個時間間隔做出決定
對吞吐量度量進行采樣並“計算平均值”。然後,使用該值來針對下 一個時間間隔做出決定 ![]() . 度量的雜亂無章是可理解的,除非在相當長的時間間隔中進行采樣 ,否則統計信息並不能代表實際情況。
. 度量的雜亂無章是可理解的,除非在相當長的時間間隔中進行采樣 ,否則統計信息並不能代表實際情況。
很難確定改進是並發級別更改的結果還是由於其他因素(例如工作負載浮動) 造成的。 實際系統中的自適應方法是非常復雜的。在我們的示例中,使用這種方 法尤其存在問題,因為在很短時間內從雜亂無章的環境中檢測微小的變化或提取 更改是非常困難的。
通過這種方法觀察到的第一個問題是,建模的函數(請參閱圖 2 中的黑色曲 線)在真實情況下(請參閱相同圖形中的藍色點)不是靜態目標,因此很難測量 微小更改。
第二個問題可能更值得關注,就是干擾信息(系統環境導致的度量差異,例如 特定操作系統活動、垃圾收集等等),這個問題使得確定輸入和輸出之間是否存 在必然聯系變得更加困難,即無法確定吞吐量是否不單純是線程數的函數。
事實上,在 ThreadPool 中,吞吐量只是實際觀察到的輸出中的一小部分,觀 察到的大部分是干擾信息。
例如,考慮一個其工作負載使用許多線程的應用程序。
只增加少許線程並不會導致輸出發生變化;在某個時間間隔內觀察到的改進甚 至可能與並發級別更改無關(圖 3 有助於說明這一問題)。
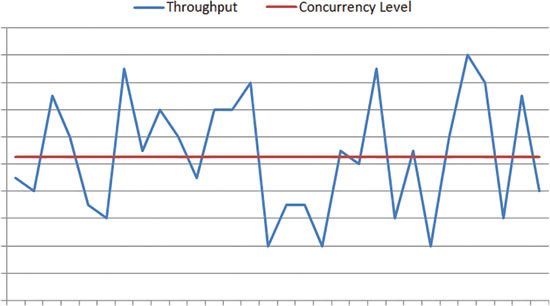
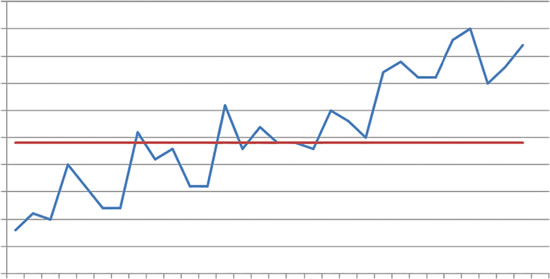
圖 3 ThreadPool 中的干擾信息示例
在圖 3 中,X 軸代表時間;Y 軸則指示吞吐量和並發級別度量已超過限制。
上方的圖形說明了在某些工作負載下,即使線程數(紅色)保持不變,也會觀 察到吞吐量發生變化(藍色)。
在本示例中,這些浮動就是干擾信息。
下方的圖形是另一個示例,說明即使存在干擾信息,在一段時間內仍會觀察到 整體吞吐量有所提高。
不過,線程數保持不變,因此吞吐量的改進是系統中其他參數的結果。
在下一部分中,我將介紹處理干擾信息的方法。
引入信號處理
信號處理在許多工程領域中用來減少信號中的干擾信息,相應概念就是在輸出 信號中查找輸入信號的模式。
如果我們將並發控制算法的輸入(並發級別)和輸出(吞吐量)視為信號,則 此理論就可以在 ThreadPool 的上下文中運用。
如果我們將故意修改的並發級別作為帶有已知周期和波幅的“波形”輸入,然 後在輸出中查找原始波形模式,則可以針對吞吐量判斷哪些是干擾信息,哪些是 實際輸入效果。
圖 4 對此概念做出了說明。
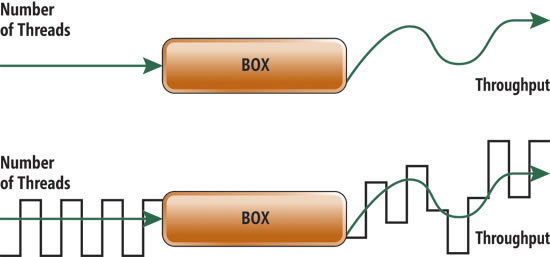
圖 4 確定 ThreadPool 輸出中的因素
仔細考慮一下,用黑色方框表示的系統在給定輸入的情況下如何生成輸出。
圖 4 說明了一個簡單的 HC 輸入和輸出(綠色)示例;下面是一個使用濾波 技術(黑色)後輸入和輸出作為波形的顯示形式示例。
我們不再提供平直的、固定不變的輸入,而是引入了一個信號,然後嘗試在雜 亂無章的輸出中發現這一輸入。
這種效果可以通過帶通濾波器 或匹配濾波器 這樣的技術實現;這些技術通常 用於從其他波形中提取所需波形或者在輸出中找出非常有針對性的信號。
這也表示在引入輸入更改時,算法可以根據最後一小段輸入數據,在每個時間 點做出決定。
ThreadPool 運用的特定算法中使用離散傅裡葉變換,這是一種提供波形的波 幅和相位等信息的方法。
然後,此信息可用於確定輸入是否影響到輸出以及產生的影響。
圖 5 中的圖形顯示對運行 600 秒以上的工作負載使用此方法的 ThreadPool 行為的示例。
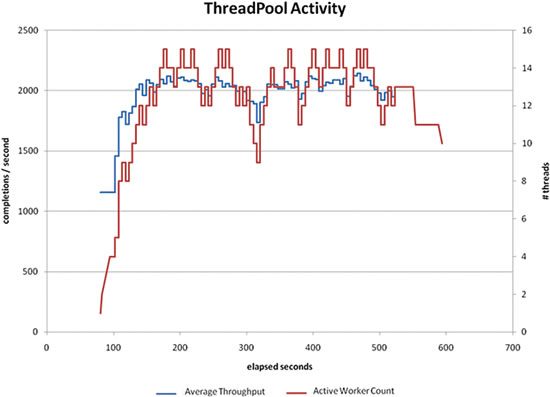
圖 5 測量輸入對輸出的影響
在圖 5 的示例中,可以在輸出中追蹤輸入波形的已知模式(相位、頻率和波 幅)。
該圖說明了對工作負載樣本使用濾波後並發算法的行為。
紅色的波形對應於輸入,而藍色波形對應於輸出。
線程數會在一段時間內向上和向下浮動,但這並不表示我們正在創建或銷毀線 程;我們保持線程數不變。
雖然線程數的變化幅度與吞吐量的變化幅度不同,但我們可以了解它是如何指 示輸入對輸出的影響的。
線程數持續在某個時間段內遞增或遞減至少一個,但這並不表示正在創建或銷 毀線程。
相反,線程在線程池中保持“活動”狀態,但當前並未執行工作。
在最初使用 HC 的方法中,目標是建立吞吐量曲線模式,並根據計算結果做出 決策。與之相比,這種改進的方法只確定輸入更改是否有助於改進輸出。
我們在直觀上就非常肯定,人為引入的更改對輸出產生了觀察到的效果(到目 前為止,在信號中引入的、觀察到的最大線程數是 20,這是相當合理的,尤其是 對於有許多線程的場景)。
使用信號處理的方法的缺點之一是由於人為引入波形模式,最優並發級別始終 需要在至少一個線程後才發揮作用。
同時,對並發級別的調整相對較慢(更快的算法建立在 CPU 利用率度量的基 礎上),因為收集足夠的數據來保持模型穩定是非常必要的。
並且,速度將取決於工作項的長度。
這種方法並不是完美的,而且具體的表現隨工作負載而所有不同;不過,它相 比前面的方法來說有相當大的進步。
我們的算法表現最好的工作負載類型是那些具有相對較短的單獨工作項的工作 負載,因為工作項越短,算法自適應的速度也就越快。
例如,它對於持續時間低於 250 毫秒的工作項表現非常好,不過在持續時間 低於 10 毫秒的環境中使用時更為出色。
並發管理 - 無需勞您大駕
總而言之,ThreadPool 提供了一些服務,使編程人員能夠將精力集中在並發 管理以外的其他功能上。
為了實現這種功能,ThreadPool 實現中集成了能夠自動為用戶作出許多決策 的高端工程算法。
一個示例是並發控制算法,該算法隨技術進步和不同場景中的需求(例如需要 測量有用的工作執行進度)而不斷發展。
CLR 4.0 中並發控制算法的目的是自動確定多少工作項可以同時有效地運行, 從而優化 ThreadPool 的吞吐量。
由於干擾信息和工作負載類型之類的參數的原因,這種算法難以優化;它還建 立在每個工作項都是有用工作段的假設的基礎上。
當前的設計和行為深受 ASP.NET 和並行框架方案的影響,在這些方案中,此 算法的表現堪稱完美。
通常情況下,ThreadPool 能夠非常有效地執行工作。
不過,用戶應當意識到,對於某些工作負載可能會出現一些意外行為,或者, 假如同時有多個 ThreadPool 正在運行時也可能會出現意外行為。