四、對指令的認識
指令就是「指揮」、「命令」,用以控制電腦,一步一步地實現程式的計劃。
組合語言的格式為:
( 下行中凡標“[ ] ”者,表有些指令可省略 )
[前置元] 指令 [目的操作元,源始操作元]
1,「前置元」:以下諸例即為前置元的用法。
11段名:表後面的操作元應屬於此臨時前置段。如:
MOV AX,CS:BUF1
12定義:表示其後緩沖器的臨時定義。BYTE PTR表示以一個字元定義的資料; WORD PTR表雙字元資料。
不論緩沖器的原定義為何,凡有前置元者,皆以臨 時定義為准,如:
ADD BYTE PTR BUF1,CL
前置元除了定義緩沖器長度外,亦可表示距離,
JMP SHORT ABCD
2,指令:
11使用方法:
1-1 暫存器到暫存器,但限長度相同者。
MOV AH,BL ; 為字元
XCHG AX,BX ; 為二字元
1-2 暫存器到緩沖器,或緩沖器到暫存器。
OR BUF1,AX ; BUF1為緩沖器,WORD
ADD CL,BYTE PTR BUF1
1-3 數值與暫存器或緩沖器之間。
TEST DI,8000H
AND SI,0FFH
SUB BYTE PTR BUF1,3
★數值絕不可作為「目的」操作元
1-4 將記憶區的地址放在暫存器中,以傳送該地址的內容,或傳送變數以便間接調用資料。本法限用於源存器(SI)、終存器(DI)、棧用器(BP)及兼用器(BX)。如:
MOV AL,BYTE PTR [DI]
XOR [BP],DL
MOV AX,[DI][SI]
MOV AX,BUF1[DI]
JMP LAB1[BX]
1-5 執行指令本身,不需源始或目的操作元。
PUSH CS
POP DS
CALL ABCD
JMP ABCD
CLI
STD
LAHF
RET
1-6 執行計數者。
LOOP ABCD
REP MOVSB
SAL DL,CL
ROR AX,1
DEC BX
1-7 暫存器專用指令。
OUT DX,AL
MUL BUF1
DIV CX
STOSB
LODSW
1-8 條件執行者。
JNZ ABCD
JA ABCD
JCXZ ABCD
INT 10H
IRET
12應用功能可分為下列八項:
2-1 資料轉移:1-1,1-2,1-3,1-4皆有可能。
2-2 旗號控制:1-5 涉及旗號者。
2-3 段址處理:1-1,1-2 項可能。
2-4 數學計算:視指令而定,上述各項皆可。
2-5 字串處理:1-6,1-7 項功能。
2-6 控制轉換:1-5。
2-7 條件執行:1-8。
2-8 中斷處理:1-8。
3,操作元:可分成暫存器、緩沖器及數值(Immediate Data)。其書寫方式與習慣的由前到後正好相反,使用時要小心,其余細節請參看有關組合語言手冊。
第二節 工作環境
一、系統空間
IBM PC的記憶區定址,是采用倒裝方式 (Big Endian) ,即定址值系由大到小,不同於一般由小而大(Little Endian) 的定址常識。
不論當初如此設計的目的何在,這種與人的習慣相反的觀念,給寫作組合語言者帶來極大的困擾。不僅初學者常莫明其妙,連我個人多年來一直與圖形處理為伍,都感到汗顏。每次在處理圖形時,一定要將原圖畫在紙上,對照參詳,才能瞭解是怎麼回事。
舉例說,有個圖形值在AX中,要寫進 DI 所指記憶區位置中,寫完以後,AX要向右移一位再繼續寫,直到CX=0。
這是一個非常簡單,而且經常用到的動作,可是在使用「倒裝定址」時,麻煩就來了。
假設AX值為4567H ,DI指向記憶區2000H ,倒裝的放法,是先將AL的值放進2000H 的記憶單位中,再將AH放進2001H 的記憶單位裡。如果從由小到大的定址觀點來看,這就等於是在2000H 中放了一個十六位元的值6745H 。
這倒不打緊,因為再從記憶位址2000H 中放回 AX 時,仍然成為4567H 。問題是在作圖時,一旦4567H 變成了6745H ,圖形就左右顛倒了。補救的方法,是在放進記憶區之前,先將AH及AL交換,放完以後,再重新交換回來。說來不算大事,可是白白浪費了兩個指令的時間及空間。對速度極關緊要的畫圖顯示而言,要畫幾萬個點,所累積的時間就不可小觀了。
除此之外,在寫程式時,對圖形的效應要能掌握,才會有良好的成果,像這樣每次轉來轉去,頭都昏了,自然而然就失去了耐性。
現在,80386 CPU 問世了,且不談效果,讀者可以試想,把32位元的 12345678H轉換成 78563412H要多少道手續?
這種痛苦的手續,也是美國人不願意用組合語言的理由之一。在高階語言中,有編譯器代勞,問題好像不大。但對效率的要求而言,就得不償失了。圖形功能是當今及未來電腦的主流之一,由於當初設計者沒有遠見,導致無窮的後患。
問題尚不止於此,IBM PC/AT 的系統空間,在定址的理論上,可以有 1MB(暫時不必考慮記憶擴充及EMS 等問題),然而真正能提供作為程式執行的空間,卻不足 600KB。
我們且看其系統空間的安排:
0000H 段 0000H-007FH 計 128字元,為32個基本中斷。
0008H 段 0000H-0380H 計 896字元,供系統管理中斷。
0040H 段 0000H-00FFH 計 256字元,為基本程式資料。
0054H 段 0000H-9C00H 約 34K字元,DOS 程式占用。
唯有在 00E1H段-09000H段的前半是使用者可以控制的空間,其後,又被系統占用:
09000H段由0A000H附近直到0FFFFH,為DOS 所用。
0A000H段,為 VGA圖形顯示區。
0A800H段,為 EGA圖形顯示區。
0B000H段,為文字態緩沖區,螢幕處理器6845自動管理。
0B800H段,為圖形態顯示區,螢幕處理器6845自動管理。
0C000H段,至0D000H段,各機種不定,供 EMS擴展記憶。
由上可知,整個系統的規劃不盡理想,尤其受限於8088的CPU 原先錯誤的設計理念(段暫存器現為定址的16倍,即每進一,相當於地址增加16。在最初,如果不考慮與8080兼容,原可輕易地定為 256或更高倍。)所以,當要擴充記憶容量時,便產生了 EMS這種無可奈何的高科技畸形兒。
二、周邊設備
所謂周邊設備,率指須透過系統的輸出/入匯流埠(I/O Port),及其管理程式所控制的外部各種設置。
在此定義下,鍵盤就是一種周邊設備,除此之外,螢幕顯示器、印表機、磁盤機等,均屬周邊設備。顯然,程式師必須瞭解每一種周邊設備的性質,否則無法下手。
由於周邊設備種類繁多,且各有其使用規格,可以說毫無技巧可言,故本書不擬一一介紹。要之,把各種設備所定義的規格條件,抄錄在記事簿中,以便隨時查閱。
此外,為求程式能有效地應用於各種不同規格的周邊設備上,千萬不可在應用程式中統一處理,最好定妥各種介面,作為附屬程式,由使用者自行設定。
這樣規劃的第一個原因,是無人能預知到底未來需要多少種不同的設備,掛一漏萬,以後程式增改不易,可能導致功能不足,或程式松散的後果。
第二個原因在,使用者經常使用的設備是固定不變的,將一些永遠用不到的程式放在一起,是無謂地浪費空間。
第三個原因為技術雖在進步,程式應用觀念則難以改變,主導程式與周邊設備之介面程式不應糾結在一起。一個沒有渣滓、精心雕琢的程式才有永恆的價值。終有一天,當電腦技術成熟時,原應用程式無需改動,僅將處理周邊設備的附屬程式換成新的即可。
這就是生命,就是新陳代謝,有了這些認識,才能理解組合語言的精義。
三、系統程式
在 ibm pc/at系統中,只有兩種系統程式,一是磁盤作業系統程式 (ms-dos 或 pc-dos ),負責系統啟動、記憶區管理以及部份輸出/入處理等工作。此系統程式原貯存在系統磁盤中,開機時才調入系統中,所以容易修改。由最初推出的版本1.0 ,到現在已是4.01,其功能還在不斷地改進中。
另一種為基本中斷服務程式(BIOS),貯存在唯讀記憶體中,除非機種易動,否則永遠不會改變。基本中斷程式的主要功能為便利程式師,把所有的周邊設備所需要的參數,統一由暫存器代為傳輸。程式師可按照規定,把正確的值,放到規定的暫存器中,基本中斷便會優先執行。
這兩種系統程式,程式師必須熟悉,至少,應知道何種功能要用哪一個中斷。
這兩種系統程式,都因瞻前顧後,速度不夠理想。因之有些程式師,根本不用這些中斷,自行控制輸出/入埠。這種做法確實能提高速度,自由控制。而相對的,程式的通用性也減低了。是否值得,設計前應先考慮清楚。
此外,這兩種中斷程式有些相互重復之處,如鍵盤輸入及螢幕輸出等,經常令人不知如何選用。有人建議用磁盤作業的中斷,我則認為該用基本中斷。
因為系統容許程式改變基本中斷的入口值,所有利用基本中斷的程式,都可修改入口,以增加其應用功能。磁盤作業系統則不然,雖然該程式在磁盤上,且在不斷地改進中,但在改進之時,又必須兼顧過去的客戶。時間一久,問題就發生了。且改進越大,越顯得過去的作業方式落伍,兼容就是保留過去渣滓的代名詞。兼容性越高,包袱就越重,空間浪費越大。
建築在這種基礎上的程式,必須冒種風險:是否有一天,磁盤作業系統會面臨運轉困難或遭解體的厄運?O/S2的問世已經表明了,此系統的大限業已到來。
基本中斷可以改變,意思是說,除了一部份BIOS空間的浪費無可避免外,在PC系列中,系統中斷的觀念不會再改變。只要程式師能把握基本中斷程式的技巧,則不論未來的系統變化到任何地步,一個具有實用價值的程式,理論上其生命期應該是很長的。
四、配備程式
配備程式指的是一些非必要的基本程式,只因為特殊需要而調用。通常,它是由某些系統提供,配備給某些程式的。
配備程式包括各種計算的函數及繪圖公式,特殊處理用的lib.等,在某些情況下,也可以將之視為環境,例如視窗管理ms-dos window,記憶擴充裝置 ems等。
配備程式的產生,證明了電腦軟體發展的迂回歷程,同時也表示出軟體的靈活性。在我個人的觀念中,配備程式如果能有一定的設計方式,有統一的規格,很可能在大量的、不斷發展下,成為一個個「公用模組」,並可專門提供模組,以供用戶應用,使得軟件的制作變得輕而易舉。
寫作或應用這些程式,別無其他法門,唯有熟記於胸,才能得心應手。
五、公用模組
模組應是未來電腦軟件發展的主流,每一類模組的功能,代表了各行各業的經驗及訣竅。使用者無需瞭解模組的制作技巧,只要知道如何調用,就可以完成工作。
目前尚無廠商提供「公用模組」,但是隨著觀念的拓廣,一旦有了理論,有人先行一步,這種潮流即將形成。我們即將推出的“聚珍整合模組”,第一階段尚限於程式師使用,再下一步,當客戶直接調用的介面完成後,程式的發展方向又將改弦易轍了。
第三節 處理對象
一、數據資料
數據資料率指可以輸入、處理及計算的二進位資料,在工作過程中,安全性為第一考慮因素,同時要兼顧精確以及完整性。此類資料一般說來數量都相當大,要妥善規劃資料長度,否則存貯空間會成為執行程式時的主要課題。
寫作此類程式時,各種進位制的轉換,顯示區的定位,計算公式的處理等都應該作為子程式,以便任意調用。
而真正關鍵問題卻在於:數據的極限是否能夠明確得知,在有限的范圍中,絕對可以設計一種「結構化」的規格,符合效率的需求。否則也應根據其規則性,配合程式的特性,有效地加以處理。
二、文字資料
文字資料多為字符態,拼音文字所應該注意的是,字與字間的空間調整,齊頭、齊尾、齊中等變化,行末斷字的規定,以及字體、字形、字號等。
中文尚有輸入碼、內碼等處理問題。原則上,如果要考慮中、英文兼容,則應注意螢幕上的字形顯示與字碼記憶區的位置,應占相同的比例。
目前,由於英文字、碼不分,皆占一字元,螢幕上標准格式為25行80字,即采用所謂「文字狀態」。而中文字形至少要有16x 16點陣,且需用圖形方式(也有采用文字態,再加特殊硬體者,但成本偏高,有礙中文電腦未來發展)。因此,當采用640x 400或近似規格時,中文字形與英文之比,約為2:1。
1,查本字之部首序值。
2,查對照字之部首序值。
3,比較兩者之大小,決定是否需要再比。
4,再比時,查本字筆畫數。
5,查對照字之筆畫數。
6,比較兩者之大小,以決定序位。
把這些步驟寫成程式,以中文兩個字元的內碼計,(意思是說中文收字在兩萬以下)如果用對照表的方式,空間當在64KB以上,速度則較英文慢約50倍。再若采用公式計算,空間或能節省,但速度將慢上千、百倍之多。
這還是指兩萬字以下的情況,若采用漢字全字集,後果將不堪設想。所以「專家」們一致認為,為了效率,字收得越少越好!
怎樣才能算是真正的「中文電腦」?我十多年前所面對的「敵人」,是主張將中文字埋葬掉。這種人不難對付,因為到底他們還是中國人,在民族大義的旗幟下,多多少少心中也存著樂見中文電腦成功的意願。所不同的,只是他們不相信有此可能罷。
現今的「敵人」則頑強得多,他們同樣喊著民族大義的口號,又是公認的中文電腦「專家」。更可怕的,目前使用中文電腦的人,不見得對中國文化有什麼明確的認識,有個工具列印一些文件,就相當知足了。於是,這些客戶也在其主觀的立場,認定目前這種「市場占有率高」的半調子,就是「中文電腦」的標准!
是嗎?如果中文字有六、七萬字,而目前只能用幾千、甚至一萬多字,那麼其他的字呢?算不算是中文,如果算,為什麼「中文電腦」中沒有?這種電腦能說是「中文電腦」嗎?
有人又說了,沒有關系,以後再說。怎麼說呢?有一種方法,是將文字「分集」,分成:常用字、次常用字、次次常用字、罕用字、罕罕用字等等。且不管是哪位學者有這麼大的學問去「分集」,我所知道的只是用這種方法,人無從記憶,中文排序的難度又一倍一倍地加了上去。也難怪當初有人認為中文不科學,這不是明證嗎?
三、圖形資料
在電腦圖形資料的處理方面,目前只有點陣及向量兩種形式,前者即二進位資料 (Digital Data) ,後者則是繪圖用的公式值。實際上,還有所謂「概念資料」的形式,將視覺效應經過分析後,整理成為人能夠理解的「概念」。這種概念資料非常精簡,便於貯存,取出後,再通過「概念作圖」的過程,還原成為圖形。
一個優秀的畫家,必然有這種概念作圖的能力,只要把畫家的經驗寫成程式,將其記憶的特征設計為資料,電腦必將忠實地執行,而且每次都畫得一模一樣。
如果是處理二進位點陣資料,不外乎是壓縮、還原、截取及綜合等幾種簡單功能。繪圖向量值則比較復雜,涉及計算、調整、變數、層次等多種技巧。
簡單地說,繪圖資料所考慮的,比文字資料難度高,要想得到理想的效率,最重要的應是資料結構的定義,其次是層次的安排,以及特征性質的描述等。此外,輸入變數處理涉及人的應用方式,除了專業人員外,多數人尚未能適應這種新的繪圖觀念,經驗的不足,以致迄今尚未制作出理想的程式來。
概念繪圖必將成為未來的主流,它不僅符合人類的認知習慣,且易於應用。只要概念資料建得周全、完整,略為改變其中一些概念元素,就能得到各種結果。
四、概念資料
人類系以概念進行思考,並透過概念來認識外界。所以,對人而言,最有效的應用方式,就是人已經熟知的概念。
概念並不是語言,而是組成語言的最基本因素。每一個人對外在世界的認知,都是獨一無二的,由於人類生存在群體空間裡,需要經常彼此交換經驗,於是利用聽覺效應表達概念,便產生了語言;利用視覺符號,則產生了文字。
前述的圖象概念資料屬於「具象」資料,除了具象以外,還有抽象的,包括主觀的感受、認知、欲望等等,因與主題無關,這裡不加討論。總之,這些概念資料的結構,在電腦中必然是二進制的形式,只是因每一個設計者觀點的不同,性能有所區別罷了。
直到如今,尚未見到實際應用概念資料的程式,但是它將成為電腦的基本結構,卻是指日可待的。
作為程式師,天天與電腦為伍,不能不知道電腦未來的趨勢,更不能不多加努力,掌握技術發展的機先。正因為概念資料尚未定形,人人都有相同的機會,做一個開創時代的先河。否則,等到大局底定時,只有在後面苦苦追趕,由不得己了。
五、綜合資料
功能較強的程式,很少僅具有單一的資料。尤其是「整合軟件」越來越受到重視,各種資料最終都將綜合在一起。
綜合資料有兩種意義,一是人所認識的輸入資料,一是電腦貯存的處理資料。
輸入資料又可分指令及字符兩種,在傳統的觀念裡,不將指令視為資料,因為指令一旦執行以後,即不再發生作用。可是,在桌上型排版軟件廣泛流行以後,為了控制版面,必須將相關指令隨資料同時貯存起來。而排版已經成為電腦重要的功能之一,所以在未來的發展上,輸入資料必須考慮到指令。
在整合觀念中,輸入資料應有統一的規定,亦即不論是何種性質的軟件,其鍵盤的應用、字符的定義等,都應該有全面的考慮。
關於資料內容,也有 ASCII字符及「世界字符」之爭,對早期的英文系統而言,其他文字無關緊要,所以沒有適當的「世界字碼」可供應用。然而,資訊時代究竟不是英文使用國家的專利,在各國覺醒之際,都憬悟到字碼的重要。不論 ISO國際組織如何面對問題,我個人不相信世界文字在其保留的、極為有限的「編碼平面」上,能夠發揮多大的效益。充其量,可供一段時間內、某些商業上的應用而已。
我認為真正的資訊標准,將是以各國文字為根本的自然語言,而目前最理想的方式,則為多字元的字碼方案。拼音文字系統以二字元為宜,除了可以同時應用世界各國文字以外,並且符合當前微電腦的發展趨勢。
在中文系統上,我們采用四字元的「自然碼」,即將倉颉輸入碼壓縮的方案。如此,我們可以使用上千萬個中文字,有人會說沒有人需要那麼多字,但事實上有誰能預料呢?當初倉颉造字時,相信不會超過一千,如果他武斷地訂定「標准」限制後人用字,很難想像我們的民族還會有什麼文化?
台灣曾有專家對我這種意見,表示是「不合乎潮流,注定要失敗」,然而到底是誰不合潮流呢?四字元的微電腦已經到來了,而且被公認為今後的主流。在四字元的硬體結構上,自以一次讀取四字元、其次為二字元最為有效。所以這些觀念已經落伍的專家,還是去撈些鈔票,把研究發展的工作,交給夠資格的人去做吧!
第四節 指令應用
組合語言可以說是未經整理的、原始的電腦語言,讀者們大可下一番功夫,找出其應用的規則,以發揮最高的效率。在下面,我僅就個人的經驗,提供一些淺見,以供切磋研討。
要寫好程式,首先應熟記8088指令的時鐘脈沖(Clock )及指令長度,一般組合語言手冊中,都詳列了與各指令相關的資料。「工欲善其事,必先利其器」,此之謂也。
本節所討論的,是一般程式師容易忽略的細節,所有的例子都是從我所看過的一些程式中摘錄下來的。看來沒什麼大了不起,可是程式的效率,受到這些小地方的影響很大。更重要的是,任何一個人,只要有「小事不做,小善不為」的習慣,我敢斷言,這個人不會有什麼大成就!
我最近才查到 Effective Address (EA) 的時鐘值,我覺得沒有必要死記。原則上,以暫存器為變數,做間接定址時為5個時鐘,用直接定址則為6個;若用了兩組變數,則為7至9個,三組則為11或12個。
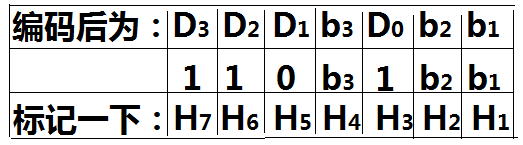
為了便於敘述,下面以“T”表「時鐘脈沖」; “B”表字元。其中
一、避免浪費速度及空間
組合語言的效率建立在指令的運用上,如果不用心體會下列指令的有效用法,組合語言的優點就難以發揮。
1, CALL ABCD
RET
這種寫法,是沒有用心的結果,共用了 4B,23T+20T,完全相同的功能,如:
JMP ABCD 或
JMP SHORT ABCD
卻只要 2-3B,15T。
此外,上述的CALL XXXX 是調用子程式的格式,在直覺認知上,與JMP XXXX完全不同。對整體設計而言,是不可原諒的錯誤,偵錯的時候,也很難掌握全盤的理念。
尤其是在精簡程式的時候,很可能會遇到 ABCD 這個子程式完全獨立,是則把這段程式直接移到 ABCD 前,不僅能節省空間,而且使程式具有連貫性,易讀易用。
2, MOV AX,0
同樣,這條指令要 3B,4T,如果用:
SUB AX,AX 或
XOR AX,AX
只要 2B,3T, 唯一要注意的是,後者會影響旗號,所以不要用在有旗號判斷的指令前面。
在程式寫作中,經常需要將暫存器或緩沖器清為0,有效的方法,是使某暫存器保持為0,以便隨時應用。
因為,MOV [暫存器],[暫存器] 只要 2B,2T, 即使是清緩沖器,也比直接填0為佳。
只是,如何令暫存器保持0,則要下一番功夫了。
還有一種情況,就是在一回路中,每次都需要將 AH 清0,此時對速度要求很嚴,有一個指令 CBW 原為將一 個字元轉換為雙字元,只需 1B,2T 最有效率。可是應該注意,此時 AL 必須小於 80H,否則 AH 將成為負數。
3, ADD AX,AX
需要 2B,3T不如用:
SHL AX,1
只要2B,2T。
4, MOV AX,4
除非這時 AH 必為0,否則,應該用:
MOV AL,4
這樣會少一個字元。
5, MOV AL,46H
MOV AH,0FFH
為什麼不寫成:
MOV AX,0FF46H
不僅省了一個字元,四個時鐘,而且少打幾個字母!
6, CMP CX,0
需要 4B,4T, 但若用:
OR CX,CX
完全相同的功能,但只要 2B,3T。再若用:
JCXZ XXXX
則一條指令可以替代兩條,時空都省。不幸這條指令限用於CX ,對其他暫器無效。
7, SUB BX,1
這更不能原諒,4B,4T無端浪費。
DEC BX
現成的指令,1B,2T為何不用?
如果是
SUB BL,1
也應該考慮此時 BH 的情況,若可以用
DEC BX
取代,且不影響後果,亦不妨用之。
8, MOV AX,[SI]
INC SI
INC SI
這該挨罵了,一定是沒有記熟指令,全部共4B,21T。
LODSW
正是為這個目的設計,卻只要 1B,16T。
9, MOV CX,8
MUL CX
寫這段程式之時應先養成習慣,每遇到乘、除法,就該打一下算盤。因為它們太浪費時間。8位元的要七十多個時鐘,16位元則要一百多。所以若有可能,盡量設法用簡單的指令取代。
SHL AX,1
SHL AX,1
SHL AX,1
原來要 5B,137T,現在只要 6B,6T。如果CX能夠動用的話,則寫成:
MOV CL,3
SHL AX,CL
這樣更佳,而且CL之值越大越有利。用CL作為計數專 用暫存器,不僅節省空間,且因指令系在 CPU中執行,速 度也快。
可是究竟快了多少? 我們做了些測試,以 SHL為例,在10MHZ 頻率的機器上,作了3072 ×14270次,所測得時間為:
指 令 :SHL AX,CL SHL AX,n
CL = 0 , 23 秒 n = 0 , 無效
CL = 1 , 27 秒 n = 1 , 14 秒
CL = 2 , 32 秒 n = 2 , 28 秒
CL = 3 , 36 秒 n = 3 , 42 秒
CL = 4 , 40 秒 n = 4 , 56 秒
CL = 5 , 44 秒 n = 5 , 71 秒
CL = 6 , 49 秒 n = 6 , 85 秒
CL = 7 , 54 秒 n = 7 , 99 秒
由此可知,用CL在大於2時即較分別執行有效。
此外,亦可利用回路做加減法,但要算算值不值得,且應注意是否有調整余數的需要。
10, MOV WORD PTR BUF1,0
MOV WORD PTR BUF2,0
MOV WORD PTR BUF3,0
MOV BYTE PTR BUF4,0
..
我見過太多這種程式,一見就無名火起! 在程式中,最好經常保留一個暫存器為0,以便應付這種情況。即使沒有,也要設法使一暫存器為0,以節省時、空。
SUB AX,AX
MOV BUF1,AX
MOV BUF2,AX
MOV BUF3,AX
MOV BUF4,AL
14B,59T取代了 24B,76T,當然值得。只是,還是不 如事先有組織,考慮清楚各個緩沖器間的應用關系。以前面舉的例來說,假定各緩沖器內數字,即為其實際位置關系,則可以寫成:
MOV CX,3
如已知 CH 為0,則用:
MOV CL,3
SUB AX,AX
MOV DI,OFFSET BUF1
REP STOSW
STOSB
這段程式越長越占便宜,現在用10B,37T,一樣劃算。
11,子程式之連續調用:
CALL ABCD
CALL EFGH
如果 ABCD,EFGH 都是子程式,且調用的次數甚多,則上述調用的方式就有待商榷了。因為連續兩次調用,不僅時間上不劃算,空間也浪費。
12,常有些程式,當從緩沖器中取資料時,必須將暫存器高位置為0。如:
SUB AH,AH
MOV AL,BUFFER
這時應該將 BUFFER 先設為:
BUFFER DB ?,0
然後用:
MOV AX,WORD PTR BUFFER
如此,不但速度快了,空間也省了。
13,有時看來多了一個指令,但因為指令的特性,反而更為精簡。如:
OR ES:[DI],BH
OR ES:[DI+1],BL
這樣需要8B,32T,如果改用下面的指令:
XCHG BL,BH
OR ES:[DI],BX
XCHG BH,BL
則需7B,28T。
14,PUSH 及 POP 是保存暫存器原值的指令,都只需一個字元,但卻很費時間。
PUSH 占 15T,POP 占12T,除非不得已,不可隨便使用。有時由於子程式說明不清楚,程式師為了安全,又懶得檢查,便把暫存器統統堆在堆棧上。尤其是在系統程式或子程式中,經常有到堆棧上堆、取的動作。實際上,花點功夫,把暫存器應用查清楚,就可以增進不少效率。
要知道,系統程式及某些子程式常常應用,有關速度的效率甚大,如果掉以輕心,就是不負責任!
保存原值的方法很多,其中較有效率的是放到一些不用的暫存器裡。以我的經驗,堆棧器用途最少,正好用作臨時倉庫。但最好的辦法,還是把程式中暫存器的應用安排得合情合理,不要浪費,以免堆得太多。
還有一種方法,是在該子程式中,不用堆棧的手續,但另設一個入口,先將暫存器堆起,再來調用不用堆棧的子程式。這兩個不同的入口,可以分別提供給希望快速處理,或需要保留暫存器原值者調用。
當然,更簡單有效的方法,則是說明本段程式中某些暫存器將被破壞,而由調用者自行保存之。