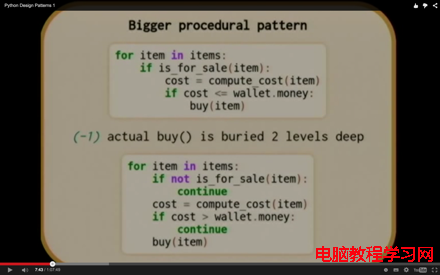
字符串在Python內部的表示是unicode 編碼,因此,在做編碼轉換時,通常需要以unicode作為中間編碼,即先將其他編碼的字符串解碼(decode)成unicode,再從unicode編碼(encode)成另一種編碼。
decode的作用是將其他編碼的字符串轉換成unicode編碼,如str1.decode('gb2312'),表示將gb2312編碼的字符串str1轉換成unicode編碼。
encode的作用是將unicode編碼轉換成其他編碼的字符串,如str2.encode('gb2312'),表示將unicode編碼的字符串str2轉換成gb2312編碼。
因此,轉碼的時候一定要先搞明白,字符串str是什麼編碼,然後decode成unicode,然後再encode成其他編碼。
代碼中字符串的默認編碼與代碼文件本身的編碼一致 。
如:s='中文'
如果是在utf8的文件中,該字符串就是utf8編碼,如果是在gb2312的文件中,則其編碼為gb2312。這種情況下,要進行編碼轉換,都需 要先用decode方法將其轉換成unicode編碼,再使用encode方法將其轉換成其他編碼。通常,在沒有指定特定的編碼方式時,都是使用的系統默 認編碼創建的代碼文件。
如果字符串是這樣定義:s=u'中文'
則該字符串的編碼就被指定為unicode了,即python的內部編碼,而與代碼文件本身的編碼無關。因此,對於這種情況做編碼轉換,只需要直接使用encode方法將其轉換成指定編碼即可。
如果一個字符串已經是unicode了,再進行解碼則將出錯,因此通常要對其編碼方式是否為unicode進行判斷:
isinstance(s, unicode) #用來判斷是否為unicode
用非unicode編碼形式的str來encode會報錯
如何獲得系統的默認編碼 ?
#!/usr/bin/env python
#coding=utf-8
import sys
print sys.getdefaultencoding()
該段程序在英文WindowsXP 上輸出為:ascii
設置文檔內字符串默認編碼
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
設置python全局默認編碼只需在python的安裝目錄/Lib/site-packages文件夾下新建一個sitecustomize.py
加入如下代碼:
# encoding=utf8
import sys
reload(sys)
sys.setdefaultencoding('utf8')
注意sitecustomize.py名字是不能修改的。
解碼過程中使用unicode(str,'gb2312')與str.decode('gb2312')效果是一樣的,都是將gb2312編碼的str轉為unicode編碼
使用str.__class__可以查看str的編碼形式
>>> import sys
>>> sys.getdefaultencoding()
'ascii'
>>> s = "中文"
>>> s.__class__
<type 'str'>
>>> isinstance(s,unicode) # 是否為unicode代碼
False
>>> s
'\xd6\xd0\xce\xc4'
>>> print s
中文
>>> s.decode("gb2312") # 解碼成unicode
u'\u4e2d\u6587'
>>>
>>> s2 = u"中文"
>>> s2.__class__
<type 'unicode'>
>>> isinstance(s2, unicode)
True
>>> s2
u'\u4e2d\u6587'
>>> print s2
中文
>>> s2.encode("gb2312") # 編碼為gb2312
'\xd6\xd0\xce\xc4'
>>>
下面這個例子是以gb2312格式輸出內容,在IDLE中運行是沒有效果的
#!/usr/bin/env python
#coding=utf-8
import sys
reload(sys)
sys.setdefaultencoding('utf8')
s="中文"
if isinstance(s, unicode):
print s.encode('gb2312')
else:
print s.decode('utf-8').encode('gb2312')
raw_input("press enter")
另外django庫裡面有一個轉換工具非常好用,可以轉換任意編碼
from django.utils.encoding import smart_str, smart_unicode
s = "中文"
s= smart_str(s, encoding="utf-8") # 默認轉換為utf-8編碼
如果想轉換unicode可以使用
s= smart_unicode(s, encoding="utf-8") # 默認轉換為utf-8編碼
python 還提供codecs編碼轉換庫
>>> import codecs
>>> f = codecs.open("/data/testdata/test.txt", "r", "utf-8") # 以utf-8形式打開文件
>>> for line in f:
if line[:3] == codecs.BOM_UTF8:
line = line[3:]
print line