pdfplumber操作pdf文件
python開源庫pdfplumber,can be obtained more easilypdf的各種信息,包含pdf的基本信息(作者、創建時間、修改時間…)及表格、文本、圖片等信息,Basically, it can meet the relatively simple format conversion function.
一、pdfplumber安裝及導入
Just like any other package,支持使用pip安裝,安裝命令:
pip install pdfplumber
安裝成功後,可直接用import導入,導入命令:
import pdfplumber
二、pdfplumber基礎使用
1、基礎知識
(1)pdfplumber有2個基礎類
PDF和Page,PDFUsed to process the entire document,PageUsed to process the entire page.
(2)pdfplumber讀取pdf文件方式
pdfplumber.open(‘文件路徑’),返回pdfplumber.PDF類的實例.
如果pdf有密碼,加入password參數:
pdfplumber.open(‘文件路徑’,password=‘密碼’)
2、獲取pdf基礎信息
讀取pdf文件,並輸出pdf文件的基礎信息
import pdfplumber
# 打開pdf文件,Join with a passwordpassword參數
pdf_info =pdfplumber.open(r'test.pdf')
meta_data = pdf_info.metadata # pdf的基礎信息
page_con = len(pdf_info.pages) # 獲取pdf的總頁數
print('pdf文件的基礎信息:\n', meta_data)
print('pdf共%s頁' % page_con)

3、pdfplumber提取表格數據
It is mainly used to extract table dataextract_tables()和extract_table()兩種方法,The two extraction methods are different.
用以下pdf文檔,as a presentation document.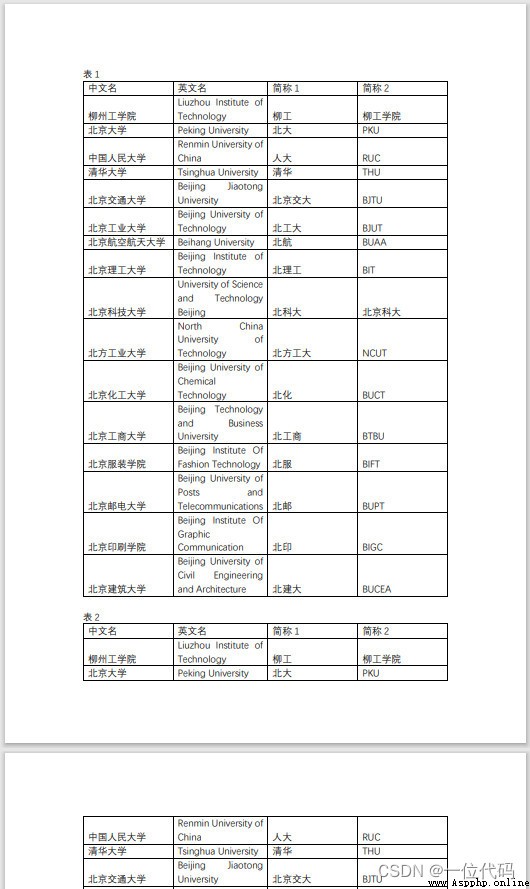
(1)extract_tables()方法
All tables in the output document,返回一個嵌套列表,Its structure level is table-row-cell.如:
#extract_tables()用法
with pdfplumber.open(r'test.pdf') as pdf_info: # 打開pdf文件
page_one = pdf_info.pages[0] # 選擇第一頁
page_one_table =page_one.extract_tables() # 獲取pdfAll tabular data on the first page of the document
for row in page_one_table:
print('Tabular data for the first page:', row)

(2)、extact_table()方法
All tables of the document are not returned,Only return table data with the most rows,If there are multiple tables with the same number of rows,Then the top table data is output by default.The returned data structure level is row-cell,Each row of the table is a separate list,The elements in the list are the data of each cell of the original table.如:
# extract_table()用法
with pdfplumber.open(r'test.pdf') as pdf_info: # 打開pdf文件
page_one = pdf_info.pages[0] # 選擇第一頁
page_one_table = page_one.extract_table()
for row in page_one_table:
print(row)

三、提取pdfform data and save toexcel中
完整版,提取pdfform data and save toexcel中
import pdfplumber
from openpyxl import Workbook
class PDF(object):
def __init__(self, file_path):
self.pdf_path = file_path
# 讀取pdf文件
try:
self.pdf_info = pdfplumber.open(self.pdf_path)
print('讀取文件完成!')
except Exception as e:
print('讀取文件失敗:', e)
# 打印pdf的基本信息、返回字典,作者、創建時間、修改時間/總頁數
def get_pdf(self):
pdf_info = self.pdf_info.metadata
pdf_page = len(self.pdf_info.pages)
print('pdf共%s頁' % pdf_page)
print("pdf文件基本信息:\n", pdf_info)
self.close_pdf()
# 提取表格數據,並保存到excel中
def get_table(self):
wb = Workbook() # 實例化一個工作簿對象
ws = wb.active # 獲取第一個sheet
con = 0
try:
# Get the text in the table for each page,返回table、row、cell格式:[[[row1],[row2]]]
for page in self.pdf_info.pages:
for table in page.extract_tables():
for row in table:
# Perform a simple cleaning process on the characters of each cell
row_list = [cell.replace('\n', ' ') if cell else '' for cell in row]
ws.append(row_list) # 寫入數據
con += 1
print('---------------分割線,第%s頁---------------' % con)
except Exception as e:
print('報錯:', e)
finally:
wb.save('\\'.join(self.pdf_path.split('\\')[:-1]) + '\pdf_excel.xlsx')
print('寫入完成!')
self.close_pdf()
# 關閉文件
def close_pdf(self):
self.pdf_info.close()
if __name__ == "__main__":
file_path = input('請輸入pdf文件路徑:')
pdf_info = PDF(file_path)
# pdf_info.get_pdf() # 打印pdf基礎信息
# 提取pdfform data and save toexcel中,文件保存到跟pdfin the same file path
pdf_info.get_table()
-end-