# Python 正則表達式(二)使用 re模塊
活動地址:CSDN21天學習挑戰賽
本篇在Python正則表達式(一)的基礎上,繼續講解Python正則表達式的相關內容。
在Python語言中,使用 re模塊提供的內置標准庫函數來處理正則表達式。在這個模塊中,既可以直接匹配正則表達式的基本函數,也可以通過編譯正則表達式對象,並使用其方法來使用正則表達式。在本節的內容中,將詳細講解使用re模塊的基本知識。
在下表中,列出了 Python語言內置模塊re中常用的內置函數和方法,它們中的大多數函數也與已經編譯的正則表達式對象((regex obiect)和正則匹配對象(regex matchobject) 的萬法同名並且具有相同的功能。
在 Python程序中,函數compile()的功能是編譯正則表達式。使用函數compile()的語法如下所示。
compile(source, filename, mode [, flags [,dont_ inherit] ])
通過使用上述格式,能夠將source編譯為代碼或者AST 對象。代碼對象能夠通過 exec語句來執行或者eval()進行求值。各個參數的具體說明如下所示。
●參數 source: 字符串或者AST(Abstract Syntax Trees)對象;
●參數 filename: 代碼文件名稱,如果不是從文件讀取代碼則傳遞一些可辨認的值;
●參數 mode:指定編譯代碼的種類,可以指定為exce、eval 和 single;
●參數 flags 和 dont_inherit: 可選參數,極少使用。
例如在下面的實例中,演示了使用函數 cmpile() 將正則表達式的字符串形式編譯為Patterm實例的過程:
import re
pattern = re.compile('[a-zA-Z]')
result = pattern.findall('as3SioPdj#@23awe')
print (result)
在上述代碼中,先使用函數re.compile將正則表達式的字符串形式編譯為Pattern實例,然後使用Pattern實例處理文本並獲得匹配結果(一個Match實例),最後使用Match實例獲得信息,進行其他的操作。執行後輸出:
在Python程序中,函數match()的功能是在字符串中匹配正則表達式,如果匹配成功則返回MatchObject對象實例。使用函數match()的語法格式如下所示。
re.match(pattern, string, flags=0)
●參數 pattern: 匹配的正則表達式;
●參數 string: 要匹配的字符串;
●參數 lags: 標志位,用於控制正則表達式的匹配方式,例如是否區分大小寫、多行匹配等。
參數lags的選項值信息如下表所示:
匹配成功後,函數match() 會返回一個匹配的對象,否則返回None。我們可以使用函數group(num)或函數groups()來獲取匹配表達式。
例如下面在Python的交互式命令行程序中演示了使用match()以及group()的過程:
>>> import re
>>> m = re.match('foo', 'foo') #模式匹配字符串
>>> if m is not None: #如果匹配成功,就輸出匹配內容
... m.group()
...
'foo'
例如下面是一個失敗的匹配示例,會返回None.
>>> import re
>>> m = re.match('papa', ' foo') #模式匹配字符串
>>> if m is not None: #如果匹配成功,就輸出匹配內容
... m.group()
...
因為匹配失敗,所以m被賦值為None。
在Python程序中,函數search()的功能是掃描整個字符串並返回第一個成功的匹配。 事實上,要搜索的模式出現在一個字符串 中間部分的概率,遠大於出現在字符串起始部分的概率。這也就是將函數search()派上用場的時候。函數search()的工作方式與函數match()完全一致, 不同之處在於函數search()會用它的字符串參數,在任意位置對給定正則表達式模式搜索第一次出現的匹配情況。如果搜索到成功的匹配,就會返回一個匹配對象。否則,返回None。
接下來將舉例說明match()和search()之間的差別。以匹配個更長的字符串為例,下面使用字符串“foo”去匹配“seafood”:
>>> import re
>>> m = re.match('foo', 'seafood')#匹配失敗
>>> if m is not None: m.group()
...
由此可以看到。此處匹配失敗。match()試圖從字符串的起始部分開始匹配模式。也就是說,模式中的“f"將匹配到字符串的首字母“s”上。這樣的匹配肯定是失敗的。然而,字符串“foo"確實出現在"seafood”之中(某個位置),所以,我們該如何讓python得出肯定的結果呢?答案是使用searh()函數,而不是嘗試匹配。search() 函數不但會搜索模式在字符中第一次出現的位置,而且嚴格地對學符從左到右搜索。
>>> import re
>>> m = re.search('foo', 'seafood')#匹配失敗
>>> if m is not None: m.group()
...
'foo' #搜索成功,但是匹配失敗
>>>
在Python程序中,函數findall()的功能是在字符串中查找所有符合正則表達式的字符串,並返回這些字符串的列表。如果在正則表達式中使用了組,則返回一個元組。 函數re.match()函數和函數re.search()的作用基本一樣, 不同的是,函數re.match()只從字符串中第一個字符開始匹配。而函數re.scarch()則搜索整個字符串。
使用函數findall()的語法格式如下所示。
re.findall (pattern, string, flags=0)
請看下面的實例,功能是使用函數fndall()匹配字符串。
import re #導入模塊 re
#定義一個要操作的字符串變量s
s = "adfad asdfasdf asdfas asdfawef asd adsfas"
#將正則表達式的字符串形式編譯為Pattern實例
reObjl = re.compile('((\w+)\s+\w+)')
print (reObjl.findall(s)) #第1次調用函數findall()
#將正則表達式的字符串形式編譯為Pattern實例
reObj2 = re.compile('(\w+)\s+\w+')
print (reObj2.findall(s)) #第2次調用函數findall()
#將正則表達式的字符串形式編譯為Pattern實例
reObj3 = re.compile('\w+\s+\w+')
print (reObj3.findall(s)) #第3次調用函數findal
因為函數 findall()返回的總是正則表達式在字符串中所有匹配結果的列表,所以此處主要討論列表中“結果”的展現方式,即fndall中返回列表中每個元素包含的信息。執行後會輸出:
在Python程序中,有兩個函數/方法用於實現搜索和替換功能,這兩個函數是sub()和subn()。 兩者幾乎樣,都是將某個字符串 中所有匹配正則表達式的部分進行某種形式的替換。用來替換的部分通常是一個字符串, 但它也可能是一個函數,該函數返回一個用來替換的字符串。函數subn()和函數sub()的用法類似,但是函數subn()還可以返回一個表示替換的總數,替換後的字符串和表示替換總數的數字一起作為-個擁有 兩個元素的元組返回。
在Python程序中,使用函數sub()和函數subn()的語法格式如下所示。
re.sub( pattern, repl, string[, count])
re.subn( pattern, repl, string[, count] )
上述各個參數的具體說明如下所示。
●pattern: 正則表達式模式;
●repl: 要替換成的內容;
● string: 進行內容替換的字符串;
●count: 可選參數,最大替換次數。
例如在下面的實例中,演示了使用函數sub()實現替換功能的過程:
import re #導入模塊re
print(re.sub('[abc]', 'o','Mark')) #找出字母a、b或者C
print(re.sub('[abc]', 'o','rock')) #將"rock"變成"rook”
print(re.sub('[abc]', 'o','caps')) #將caps變成oops
在上述實例代碼中,首先在“Mark"中找出字母a、b或者c,並以字母“o”替換,Mark就變成Mork了。然後將“rock”變成“rook”。重點看最後行代碼,有的讀者可能認為可以將caps 變成oaps,但事實並非如此。函數re.sub()能夠替換所有的匹配項,並且不只是第一個匹配項。因此正則表達式將會把caps變成ops,因為c和a都被轉換為o。執行後會輸出: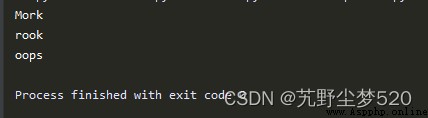
在Python程序中,模塊re和正則表達式中的對象函數split() 對於相對應字符串的工作方式是類似的,但是與分割一個固定字符串相比,它們基於正則表達式的模式分隔字符串,為字符串分隔功能添加一些額外功能。如果不想為每次模式的出現都分割字符串,就可以通過為參數max設定一個值(非零)的方式來指定最大分割數。如果給定的分隔符不是使用特殊符號來匹配多重模式的正則表達式,那麼函數re.split()與函數str.split() 的工作方式相同,例如下面的演示過程基於單引號進行分割。
>>> re.split(':', 'strl:str2:str3')
['strl', 'str2', 'str3']
請看下面的實例,功能是使用函數split()分割一個字符串。
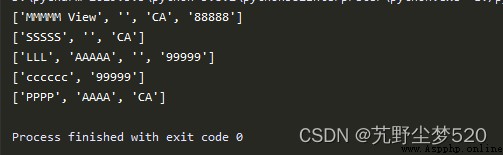
import re
DATA = (
'MMMMM View, CA 88888',
'SSSSS, CA' ,
'LLL AAAAA, 99999',
'cccccc 99999',
'PPPP AAAA CA',
)
for datum in DATA:
print(re.split(',|(?= (?:\d{5}|[A-Z]{2})) ',datum))
上面的正則表達式擁有一個簡單的組件, 使用pi語句基於退號分割字符串。更重要的部分是最後的正則表達式,可以通過該正則表達式預覽擴展符號。在普通的英文字符串中,如果空格緊跟在五個數字(ZIP編碼)成者兩個大寫字母(美國聯邦州縮寫)之後,就用spit() 函數分隔該空格。執行後會輸出: