目錄
前言
一、特征類型判別
二、定量數據特征處理
三.定類數據特征處理
1.LabelEncoding
2.OneHot Encoding
優點:
缺點:
應用場景:
無用場景:
代碼實現
編輯
方法二:
編輯
點關注,防走丟,如有纰漏之處,請留言指教,非常感謝
參閱:
當我們開始准備數據建模、構建機器學習模型的時候,第一時間考慮的不應該是就考慮到選擇模型的種類和方法。而是首先拿到特征數據和標簽數據進行研究,挖掘特征數據包含的信息以及思考如何更好的處理這些特征數據。那麼數據類型本身代表的含義就需要我們進行思考,究竟是定量計算還是進行定類分析更好呢?這就是這篇文章將要詳解的一個問題。
特征類型判斷以及處理是前期特征工程重要的一環,也是決定特征質量好壞和權衡信息丟失最重要的一環。其中涉及到的數據有數值類型的數據,例如:年齡、體重、身高這類特征數據。也有字符類型特征數據,例如性別、社會階層、血型、國家歸屬等數據。
按照數據存儲的數據格式可以歸納為兩類:
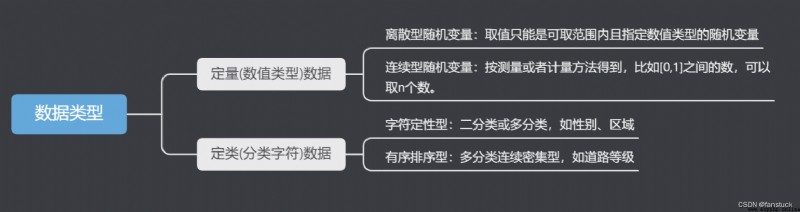
按照特征數據含義又可分為:
拿到獲取的原始特征,必須對每一特征分別進行歸一化,比如,特征A的取值范圍是[-1000,1000],特征B的取值范圍是[-1,1].如果使用logistic回歸,w1*x1+w2*x2,因為x1的取值太大了,所以x2基本起不了作用。所以,必須進行特征的歸一化,每個特征都單獨進行歸一化。
關於處理定量數據我已經在:數據預處理歸一化詳細解釋這篇文章裡面講述的很詳細了,這裡進行前後關聯,共有min-max標准化、Z-score標准化、Sigmoid函數標准化三種方法:
根據特征數據含義類型來選擇處理方法:
我的上篇文章數據預處理歸一化詳細解釋 並沒有介紹關於定類數據我們如何去處理,在本篇文章詳細介紹一些常用的處理方法:
直接替換方法適用於原始數據集中只存在少量數據需要人工進行調整的情況。如果需要調整的數據量非常大且數據格式不統一,直接替換的方法也可以實現我們的目的,但是這種方法需要的工作量會非常大。因此, 我們需要能夠快速對整列變量的所有取值進行編碼的方法。
LabelEncoding,即標簽編碼,作用是為變量的 n 個唯一取值分配一個[0, n-1]之間的編碼,將該變量轉換成連續的數值型變量。
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
le.fit(['擁堵','緩行','暢行'])
le.transform(['擁堵','擁堵','暢行','緩行'])array([0, 0, 1, 2])
對於處理定類數據我們很容易想到將該類別的數據全部替換為數值:比如車輛擁堵情況,我們把擁堵標為1,緩行為2,暢行為3.那麼這樣是實現了標簽編碼的,但同時也給這些無量綱的數據轉為了有量綱數據,我們本意是沒有將它們比較之意的。機器可能會學習到“擁堵<緩行<暢行”,所以采用這個標簽編碼是不夠的,需要進一步轉換。因為有三種區間,所以有三個比特,即擁堵編碼為100,緩行為010,暢行為001.如此一來每兩個向量之間的距離都是根號2,在向量空間距離都相等,所以這樣不會出現偏序性,基本不會影響基於向量空間度量算法的效果。
自然狀態碼為:000,001,010,011,100,101
獨熱編碼為:000001,000010,000100,001000,010000,100000
我們可以使用sklearn的onehotencoder來實現:
from sklearn import preprocessing
enc = preprocessing.OneHotEncoder()
enc.fit([[0, 0, 1], [0, 1, 0], [1, 0, 0]]) # fit來學習編碼
enc.transform([[0, 0, 1]]).toarray() # 進行編碼array([[1., 0., 1., 0., 0., 1.]])
數據矩陣是3*3的,那麼原理是怎麼來的呢?我們仔細觀察:

第一列的第一個特征維度有兩種取值0/1,所以對應的編碼方式為10、01.
第二列的第二個特征也是一樣的,類比第三列的第三哥特征。固001的獨熱編碼就是101001了。
因為大部分算法是基於向量空間中的度量來進行計算的,為了使非偏序關系的變量取值不具有偏序性,並且到圓點是等距的。使用one-hot編碼,將離散特征的取值擴展到了歐式空間,離散特征的某個取值就對應歐式空間的某個點。將離散型特征使用one-hot編碼,會讓特征之間的距離計算更加合理。離散特征進行one-hot編碼後,編碼後的特征,其實每一維度的特征都可以看做是連續的特征。就可以跟對連續型特征的歸一化方法一樣,對每一維特征進行歸一化。比如歸一化到[-1,1]或歸一化到均值為0,方差為1。
將離散特征通過one-hot編碼映射到歐式空間,是因為,在回歸,分類,聚類等機器學習算法中,特征之間距離的計算或相似度的計算是非常重要的,而我們常用的距離或相似度的計算都是在歐式空間的相似度計算,計算余弦相似性,基於的就是歐式空間。
獨熱編碼解決了分類器不好處理屬性數據的問題,在一定程度上也起到了擴充特征的作用。它的值只有0和1,不同的類型存儲在垂直的空間。
當類別的數量很多時,特征空間會變得非常大。在這種情況下,一般可以用PCA來減少維度。而且one hot encoding+PCA這種組合在實際中也非常有用。
獨熱編碼用來解決類別型數據的離散值問題。
將離散型特征進行one-hot編碼的作用,是為了讓距離計算更合理,但如果特征是離散的,並且不用one-hot編碼就可以很合理的計算出距離,那麼就沒必要進行one-hot編碼。 有些基於樹的算法在處理變量時,並不是基於向量空間度量,數值只是個類別符號,即沒有偏序關系,所以不用進行獨熱編碼。 Tree Model不太需要one-hot編碼: 對於決策樹來說,one-hot的本質是增加樹的深度。
方法一:
實現one-hot編碼有兩種方法:sklearn庫中的 OneHotEncoder() 方法只能處理數值型變量如果是字符型數據,需要先對其使用 LabelEncoder() 轉換為數值數據,再使用 OneHotEncoder() 進行獨熱編碼處理,並且需要自行在原數據集中刪去進行獨熱編碼處理的原變量。
import pandas as pd
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
lE = LabelEncoder()
df=pd.DataFrame({'路況':['擁堵','暢行','暢行','擁堵','暢行','緩行','緩行','擁堵','緩行','擁堵','擁堵','擁堵']})
df['路況']=lE.fit_transform(df['路況'])
OHE = OneHotEncoder()
X = OHE.fit_transform(df).toarray()
df = pd.concat([df, pd.DataFrame(X, columns=['擁堵', '緩行','暢行'])],axis=1)
df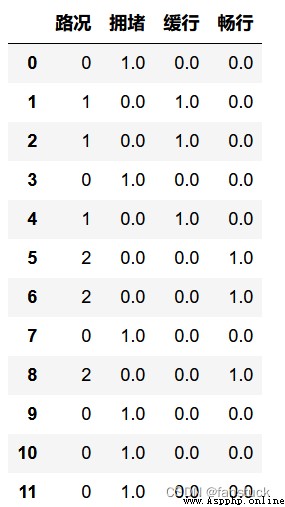
pandas自帶get_dummies()方法
get_dummies() 方法可以對數值數據和字符數據進行處理,直接在原數據集上應用該方法即可。該方法產生一個新的Dataframe,列名由原變量延伸而成。將其合並入原數據集時,需要自行在原數據集中刪去進行虛擬變量處理的原變量。
import pandas as pd
df=pd.DataFrame({'路況':['擁堵','暢行','暢行','擁堵','暢行','緩行','緩行','擁堵','緩行','擁堵','擁堵','擁堵']})
pd.get_dummies(df,drop_first=False) 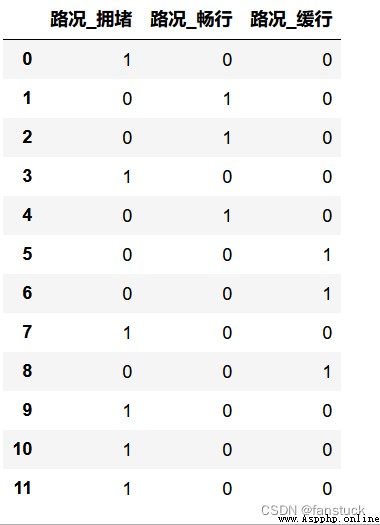
以上就是本期全部內容。我是fanstuck ,有問題大家隨時留言討論 ,我們下期見。
數據挖掘OneHotEncoder獨熱編碼和LabelEncoder標簽編碼
類別型數據的預處理方法