作者簡介:信年* ,大家可以叫我 信年 ,一位精通五門語言的博主
CSDN博客專家認證、華為雲享專家、阿裡雲專家博主 、掘金創作榜No.1
如果文章知識點有錯誤的地方,請指正!和大家一起學習,一起進步
人生格言:沒有我不會的語言,沒有你過不去的坎兒。
如果感覺博主的文章還不錯的話,還請關注、點贊、收藏三連支持一下博主哦
作者主頁傳送門:點此傳送
系列文章&專欄推薦:暫未開放
為大家推薦一款刷題網站呀點擊跳轉
所有編程語言,都可以從此網站中找到並參考學習喲~
背景
實現
結論
人臉識別是用戶身份驗證的最新趨勢。蘋果推出的新一代iPhone X使用面部識別技術來驗證用戶身份。百度也在使“刷臉”的方式允許員工進入辦公室。對於很多人來說,這些應用程序有一種魔力。但在這篇文章中,我們的目的是通過教你如何在Python中制作你自己的面部識別系統的簡化版本來揭開這個主題的神秘性。
 https://github.com/Skuldur/facenet-face-recognition
https://github.com/Skuldur/facenet-face-recognition在討論實現的細節之前,我想討論FaceNet的細節,它是我們將在我們的系統中使用的網絡。
FaceNet
FaceNet是一個神經網絡,它可以學習從臉部圖像到緊湊的歐幾裡得空間(Euclidean space)的映射,在這個空間裡,距離對應的是人臉的相似性。也就是說,兩張面部圖像越相似,它們之間的距離就越小。
Triplet Loss
FaceNet使用了一種名為Triplet Loss的獨特的損失方法來計算損失。Triplet Loss最小化了anchor與正數之間的距離,這些圖像包含相同的身份,並最大化了anchor與負數之間的距離,這些圖像包含不同的身份。

圖1: Triplet Loss等式
Siamese網絡
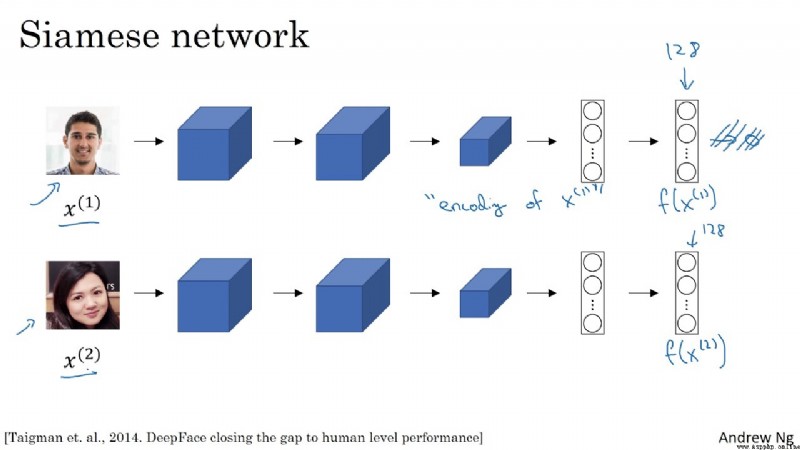
圖2:一個Siamese網絡的例子,它使用面部圖像作為輸入,輸出一個128位數字編碼的圖像。
FaceNet是一個Siamese網絡。Siamese網絡是一種神經網絡體系結構,它學習如何區分兩個輸入。這使他們能夠了解哪些圖像是相似的,哪些不是。這些圖像可以包含面部圖像。
Siamese網絡由兩個完全相同的神經網絡組成,每個神經網絡都有相同的權重。首先,每個網絡將兩個輸入圖像中的一個作為輸入。然後,每個網絡的最後一層的輸出被發送到一個函數,該函數決定這些圖像是否包含相同的身份。
在FaceNet中,這是通過計算兩個輸出之間的距離來完成的。
既然我們已經闡明了這個理論,我們就可以直接去實現這個過程。在我們的實現中,我們將使用Keras和Tensorflow。此外,我們還使用了從deeplearning.ai的repo中得到的兩個實用程序文件來為所有與FaceNet網絡的交互做了個摘要:
Kera地址:Keras: the Python deep learning APIKeras documentation https://keras.io/
https://keras.io/
Tensorflow地址:https://www.tensorflow.org/https://www.tensorflow.org/
deeplearning.ai的repo地址:https://github.com/shahariarrabby/deeplearning.ai/tree/master/COURSE%204%20Convolutional%20Neural%20Networks/Week%2004/Face%20Recognitionhttps://github.com/shahariarrabby/deeplearning.ai/tree/master/COURSE%204%20Convolutional%20Neural%20Networks/Week%2004/Face%20Recognition
編譯FaceNet網絡
我們要做的第一件事就是編譯FaceNet網絡,這樣我們就可以在面部識別系統中使用它。
import os
import glob
import numpy as np
import cv2
import tensorflow as tf
from fr_utils import *
from inception_blocks_v2 import *
from keras import backend as K
K.set_image_data_format('channels_first')
FRmodel = faceRecoModel(input_shape=(3, 96, 96))
def triplet_loss(y_true, y_pred, alpha = 0.3):
anchor, positive, negative = y_pred[0], y_pred[1], y_pred[2]
pos_dist = tf.reduce_sum(tf.square(tf.subtract(anchor,
positive)), axis=-1)
neg_dist = tf.reduce_sum(tf.square(tf.subtract(anchor,
negative)), axis=-1)
basic_loss = tf.add(tf.subtract(pos_dist, neg_dist), alpha)
loss = tf.reduce_sum(tf.maximum(basic_loss, 0.0))
return loss
FRmodel.compile(optimizer = 'adam', loss = triplet_loss, metrics = ['accuracy'])
load_weights_from_FaceNet(FRmodel)我們將以一個(3,96,96)的輸入形狀開始初始化我們的網絡。這意味著紅-綠-藍(RGB)通道是向網絡饋送的圖像卷(image volume)的第一個維度。所有被饋送網絡的圖像必須是96×96像素的圖像。
接下來,我們將定義Triplet Loss函數。上面的代碼片段中的函數遵循我們在上一節中定義的Triplet Loss方程的定義。
一旦我們有了損失函數,我們就可以使用Keras來編譯我們的面部識別模型。我們將使用Adam優化器來最小化由Triplet Loss函數計算的損失。
 https://keras.io/optimizers/#adam
https://keras.io/optimizers/#adam准備一個數據庫
現在我們已經編譯了FaceNet,我們准備一個我們希望我們的系統能夠識別的個人數據庫。我們將使用圖像目錄中包含的所有圖像,以供我們的個人數據庫使用。
注意:我們將只在實現中使用每個單獨的圖像。原因是FaceNet網絡強大到只需要一個單獨的圖像就能識別它們!
def prepare_database():
database = {}
for file in glob.glob("images/*"):
identity = os.path.splitext(os.path.basename(file))[0]
database[identity] = img_path_to_encoding(file, FRmodel)
return database對於每個圖像,我們將把圖像數據轉換為128個浮點數的編碼。我們通過調用函數img_path_to_encoding來實現這一點。該函數接受一個圖像的路徑,並將圖像輸入到我們的面部識別網絡中。然後,它返回來自網絡的輸出,這恰好是圖像的編碼。
一旦我們將每個圖像的編碼添加到我們的數據庫,我們的系統就可以開始識別人臉了!
識別人臉
正如在背景部分所討論的,FaceNet被訓練來盡可能地最小化同一個體的圖像之間的距離,並使不同個體之間的圖像之間的距離最大化。我們的實現使用這些信息來確定為我們的系統饋送的新圖像最有可能是哪一個個體。
def who_is_it(image, database, model):
encoding = img_to_encoding(image, model)
min_dist = 100
identity = None
# Loop over the database dictionary's names and encodings.
for (name, db_enc) in database.items():
dist = np.linalg.norm(db_enc - encoding)
print('distance for %s is %s' %(name, dist))
if dist < min_dist:
min_dist = dist
identity = name
if min_dist > 0.52:
return None
else:
return identity上面的函數將新圖像輸入到一個名為img_to_encoding的效用函數中。該函數使用FaceNet處理圖像,並返回圖像的編碼。既然我們有了編碼,我們就能找到最可能屬於這個圖像的那個個體。
為了找到個體,我們通過數據庫,計算新圖像和數據庫中的每個個體之間的距離。在新圖像中距離最小的個體被選為最有可能的候選。
最後,我們必須確定候選圖像和新圖像是否包含相同的對象。因為在我們的循環結束時,我們只確定了最有可能的個體。這就是下面的代碼片段所發揮的作用。
if min_dist > 0.52:
return None
else:
return identity這裡比較棘手的部分是,值0.52是通過在我的特定數據集上反復實驗來實現的。最好的值可能要低得多或稍微高一些,這取決於你的實現和數據。我建議嘗試不同的值,看看哪個值最適合你的系統!
使用面部識別建立一個系統
在這篇文章的開頭,我鏈接到的Github庫中的代碼是一個演示,它使用筆記本電腦的攝像頭來為我們的面部識別算法饋送視頻幀。一旦算法識別出框架中的一個人,演示就會播放一個音頻信息,它允許用戶在數據庫中使用它們的圖像名稱。圖3顯示了演示示例。

圖3:當網絡在圖片中識別出個體時,圖片即時被捕捉。數據庫中圖像的名稱是“skuli.jpg”,因此播出的音頻信息是“Welcome skuli, have a nice day!”
現在,你應該熟悉了面部識別系統的工作方式,以及如何使用python中的FaceNet網絡的預先訓練版本來創建你自己的簡化的面部識別系統。如果你想在Github庫中進行演示,並添加你認識的人的圖像,那麼就可以繼續使用這個庫來進行你的下一次實驗。
感謝你們的閱讀
後續還會繼續更新,歡迎持續關注喲~
如果有錯誤,歡迎指正呀
如果覺得收獲滿滿,可以點點贊支持一下喲~