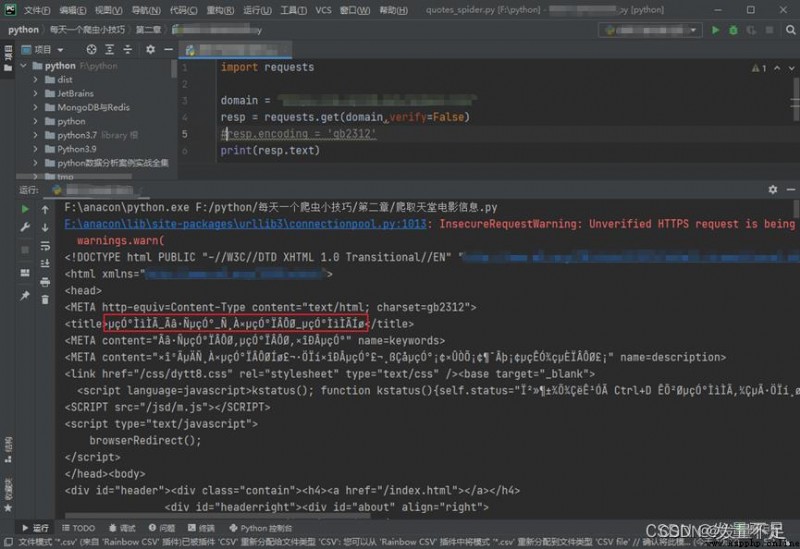
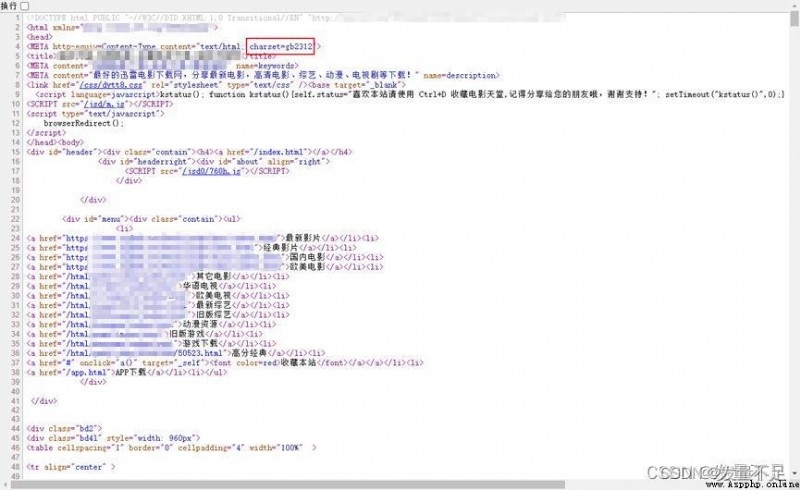
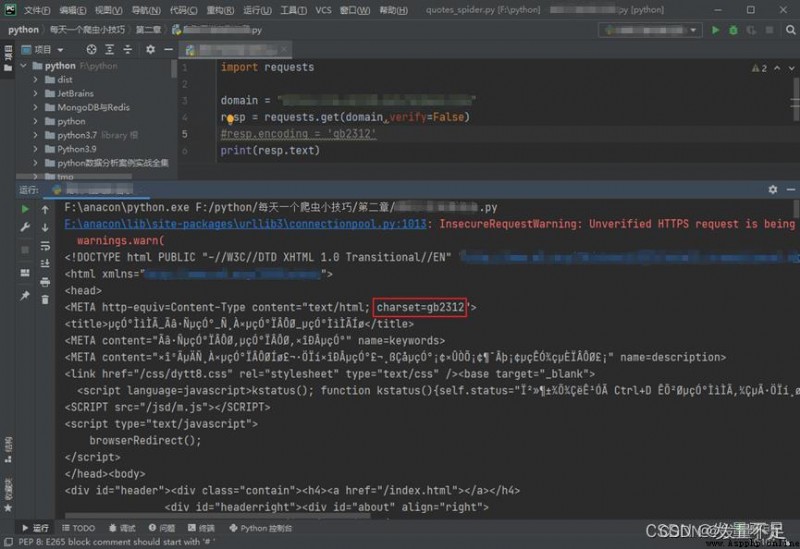
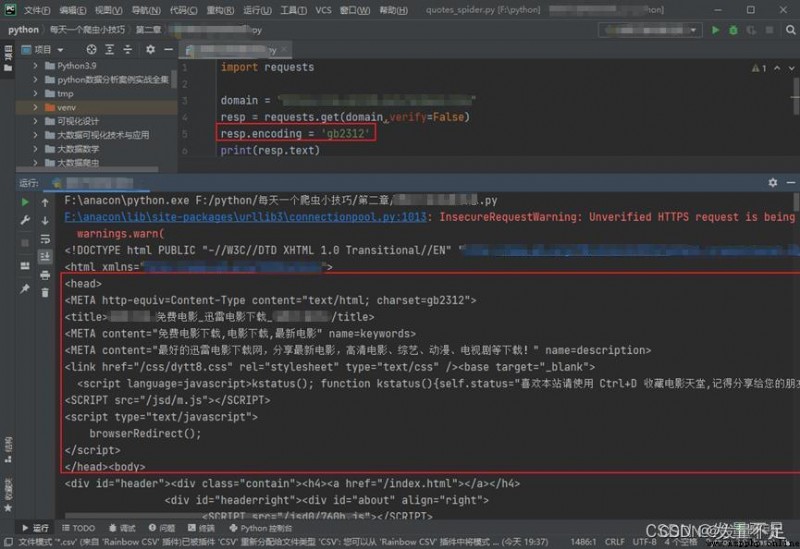
resp.encoding = 'gb2312'
List of articles One . purpos
Chen Tuo 2022/06/10-2022/06/11
Preface Today, Id like to sha
目錄前言RedisRedis簡介Python操作redis結
2021 year 9 month Python Analy
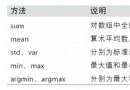
文章目錄1 通用函數2 利用數組進行數據處理2.1 np.m
 Développement de la gravure et du test du firmware esp32 avec micropython
Développement de la gravure et du test du firmware esp32 avec micropython