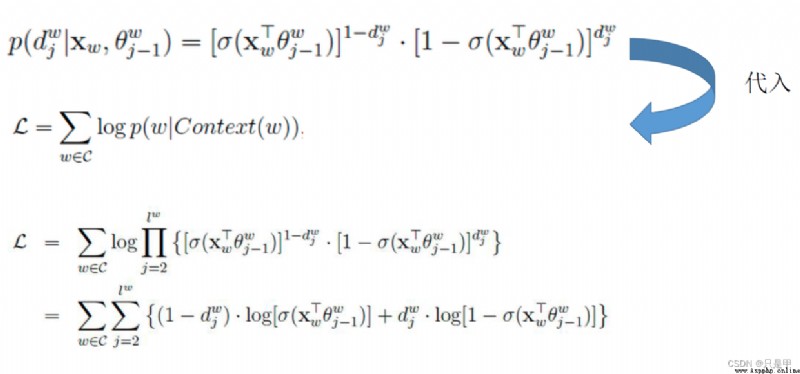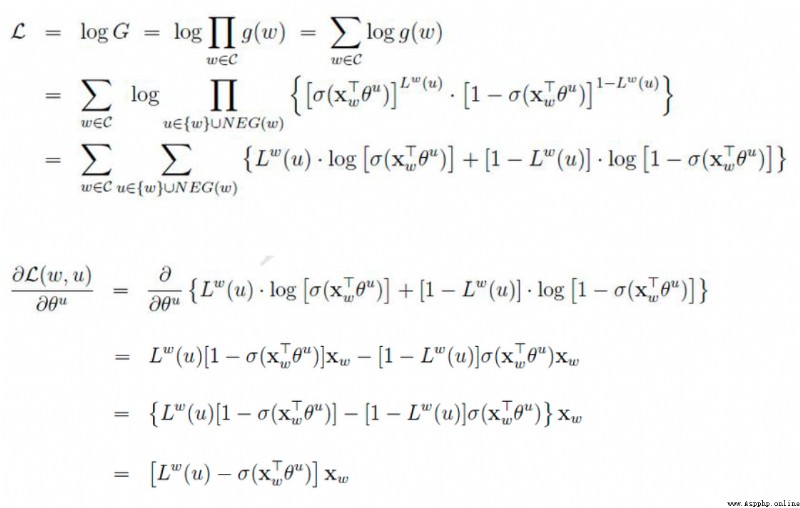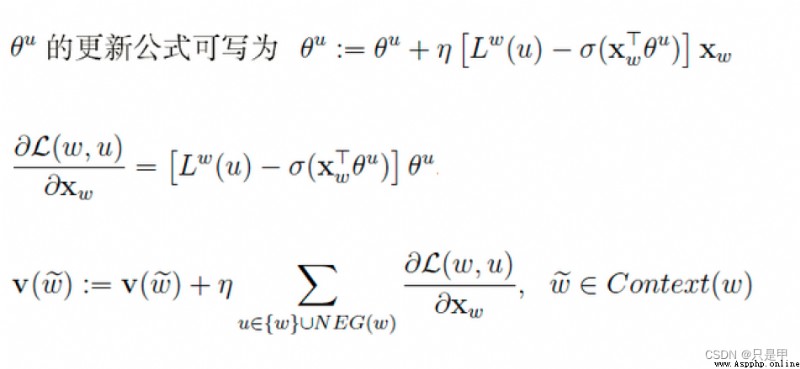

機器翻譯:
拼寫糾錯:
智能問答:

我今天下午打籃球
p(S)=p(w1,w2,w3,w4,w5,…,wn)
=p(w1)p(w2|w1)p(w3|w1,w2)...p(wn|w1,w2,...,wn-1)
p(S)被稱為語言模型,即用來計算一個句子概率的模型
語言模型存在哪些問題呢?
p(wi|w1,w2,...,wi-1) = p(w1,w2,...,wi-1,wi) /p(w1,w2,...,wi-1)
假設下一個詞的出現依賴它前面的一個詞:
p(S)=p(w1)p(w2|w1)p(w3|w1,w2)...p(wn|w1,w2,...,wn-1)
=p(w1)p(w2|w1)p(w3|w2)...p(wn|wn-1)
假設下一個詞的出現依賴它前面的兩個詞:
p(S)=p(w1)p(w2|w1)p(w3|w1,w2)...p(wn|w1,w2,...,wn-1)
=p(w1)p(w2|w1)p(w3|w1,w2)...p(wn|wn-1,wn-2)
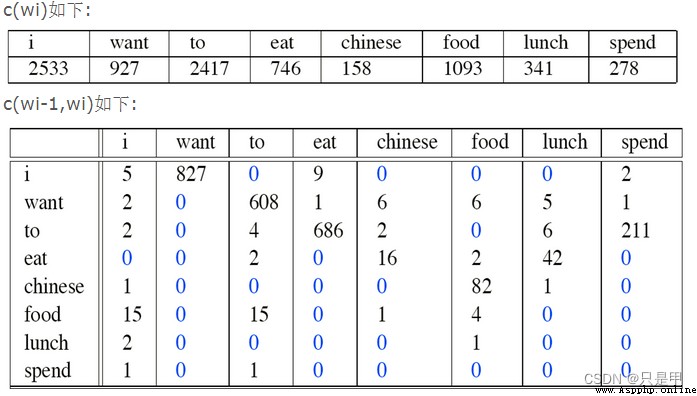
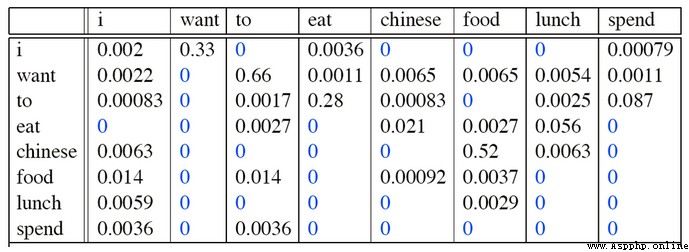
I want english food
p(I want chinesefood)=P(want|I)
×P(chinese|want)
×P(food|chinese)
假設詞典的大小是N則模型參數的量級是 O ( N n ) O(N^n) O(Nn)
下面是一些詞語: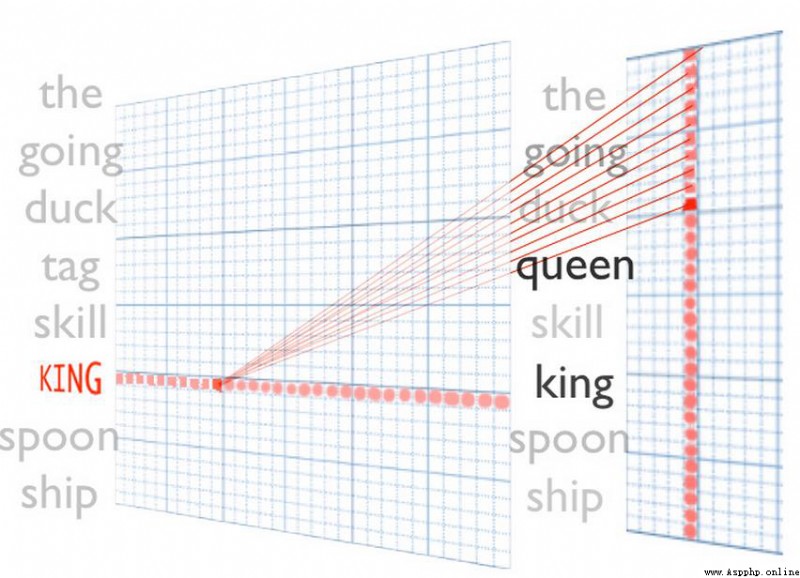
expect代表的是我們常見的向量,例如取值范圍[-1,1]
右邊圖我們可以看到 是單詞在向量空間中的分布情況,例如 had has have語義比較接近,所以在向量空間中也距離也是比較接近的。
詞意相近的詞:
詞向量與語言的關系:
左邊是英語,後面是西班牙語
我們可以看到即便語言不同,詞向量空間所處的位置不變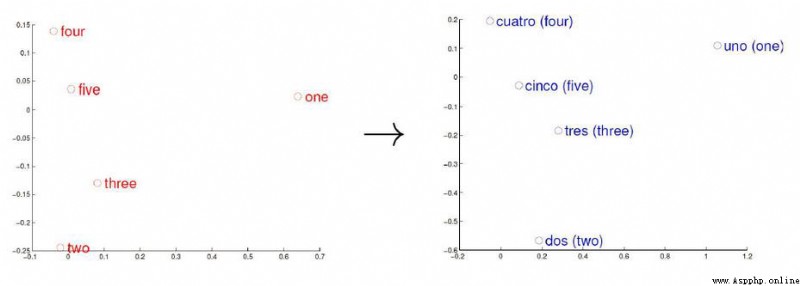
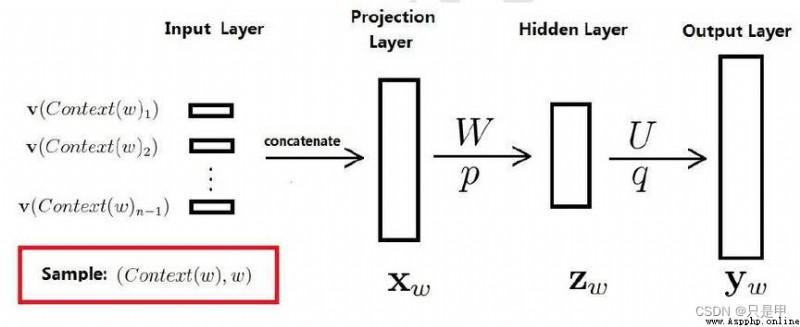
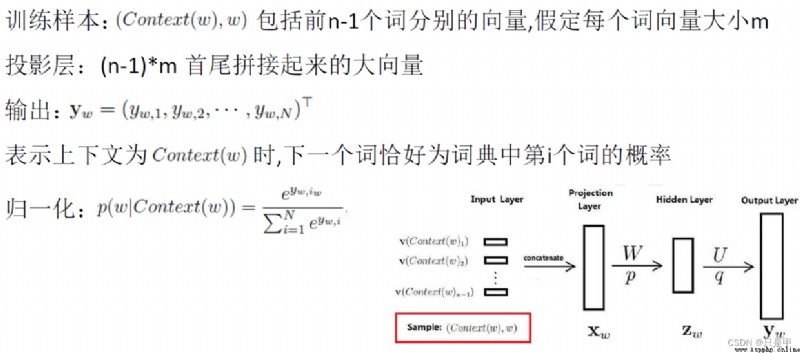


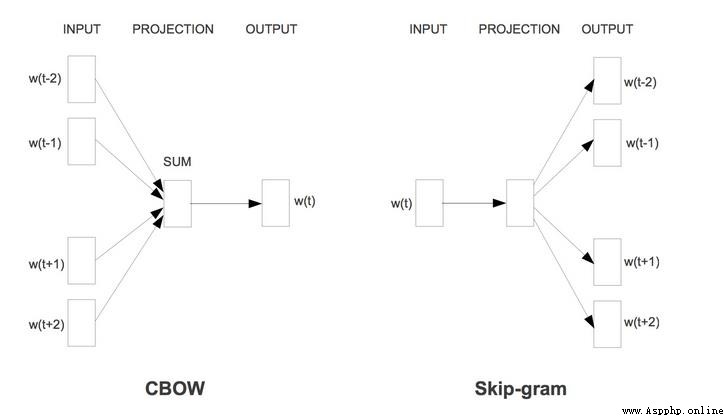
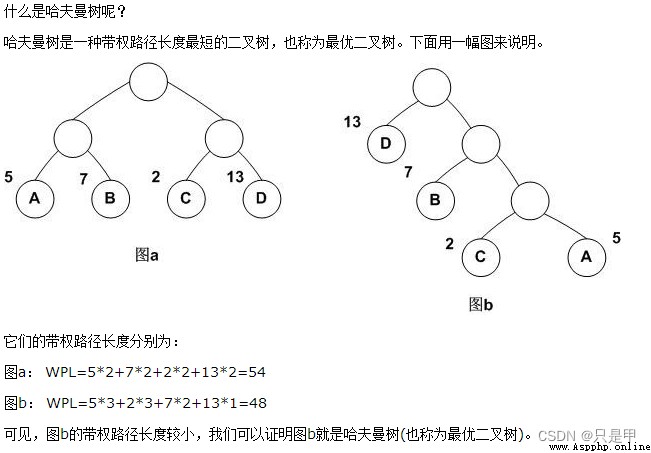
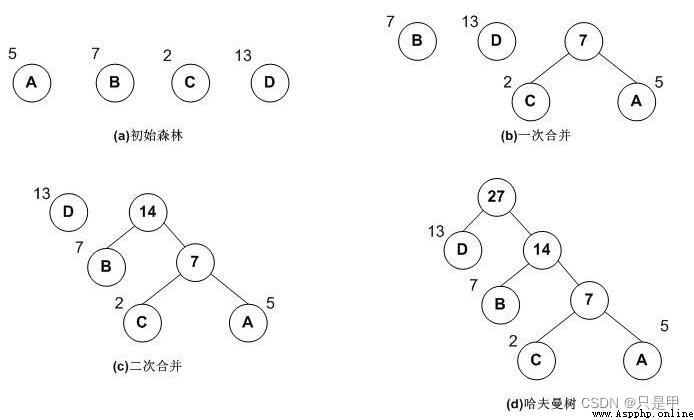

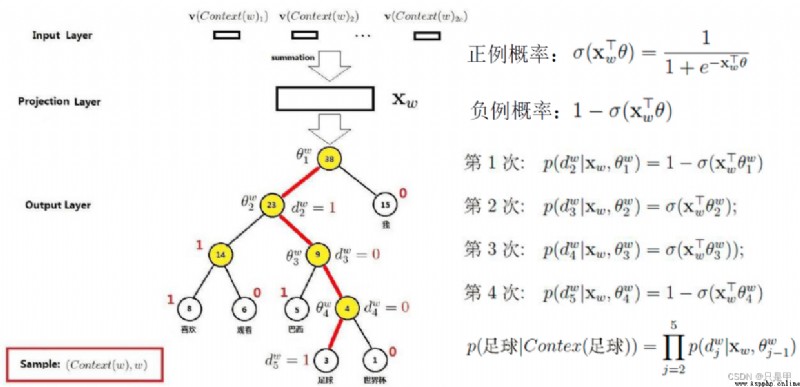
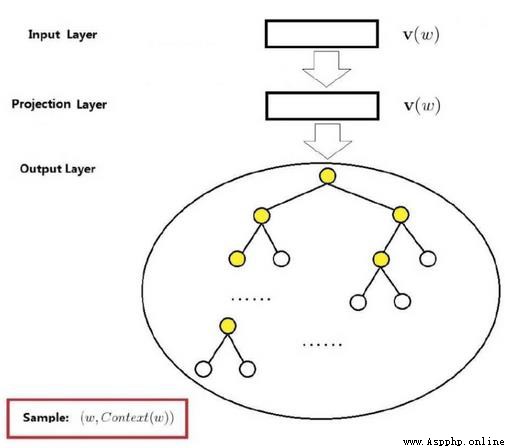
輸入層:
是上下文的詞語的詞向量,在訓練CBOW模型,詞向量只是個副產品,確切來說,是CBOW模型的一個參數。訓練開始的時候,詞向量是個隨機值,隨著訓練的進行不斷被更新)。
投影層:
對其求和,所謂求和,就是簡單的向量加法。
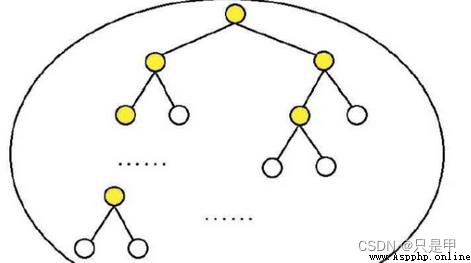
輸出層
輸出最可能的w。由於語料庫中詞匯量是固定的|C|個,所以上述過程其實可以看做一個多分類問題。給定特征,從|C|個分類中挑一個。