這是 “Python 工匠”系列的第 5 篇文章。

毫無疑問,函數是 Python 語言裡最重要的概念之一。在編程時,我們將真實世界裡的大問題分解為小問題,然後通過一個個函數交出答案。函數即是重復代碼的克星,也是對抗代碼復雜度的最佳武器。
如同大部分故事都會有結局,絕大多數函數也都是以返回結果作為結束。函數返回結果的手法,決定了調用它時的體驗。所以,了解如何優雅的讓函數返回結果,是編寫好函數的必備知識。
Python 函數通過調用 return 語句來返回結果。使用 returnvalue 可以返回單個值,用 returnvalue1,value2 則能讓函數同時返回多個值。
如果一個函數體內沒有任何 return 語句,那麼這個函數的返回值默認為 None。除了通過 return 語句返回內容,在函數內還可以使用拋出異常(raise Exception)的方式來“返回結果”。
接下來,我將列舉一些與函數返回相關的常用編程建議。
Python 語言非常靈活,我們能用它輕松完成一些在其他語言裡很難做到的事情。比如:讓一個函數同時返回不同類型的結果。從而實現一種看起來非常實用的“多功能函數”。
就像下面這樣: 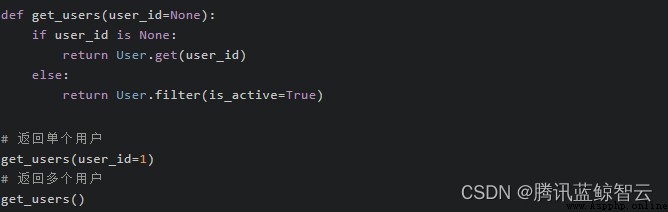 當我們需要獲取單個用戶時,就傳遞
當我們需要獲取單個用戶時,就傳遞 user_id 參數,否則就不傳參數拿到所有活躍用戶列表。一切都由一個函數 get_users 來搞定。這樣的設計似乎很合理。
然而在函數的世界裡,以編寫具備“多功能”的瑞士軍刀型函數為榮不是一件好事。這是因為好的函數一定是 “單一職責(Single responsibility)” 的。單一職責意味著一個函數只做好一件事,目的明確。這樣的函數也更不容易在未來因為需求變更而被修改。
而返回多種類型的函數一定是違反“單一職責”原則的,好的函數應該總是提供穩定的返回值,把調用方的處理成本降到最低。像上面的例子,我們應該編寫兩個獨立的函數 get_user_by_id(user_id)、 get_active_users()來替代。
假設這麼一個場景,在你的代碼裡有一個參數很多的函數 A,適用性很強。而另一個函數 B 則是完全通過調用 A 來完成工作,是一種類似快捷方式的存在。
比方在這個例子裡, double 函數就是完全通過 multiply 來完成計算的:  對於上面這種場景,我們可以使用
對於上面這種場景,我們可以使用 functools 模塊裡的 partial() 函數來簡化它。
partial(func,*args,**kwargs)基於傳入的函數與可變(位置/關鍵字)參數來構造一個新函數。所有對新函數的調用,都會在合並了當前調用參數與構造參數後,代理給原始函數處理。
利用 partial 函數,上面的 double 函數定義可以被修改為單行表達式,更簡潔也更直接。 
建議閱讀:partial 函數官方文檔
我在前面提過,Python 裡的函數可以返回多個值。基於這個能力,我們可以編寫一類特殊的函數:同時返回結果與錯誤信息的函數。 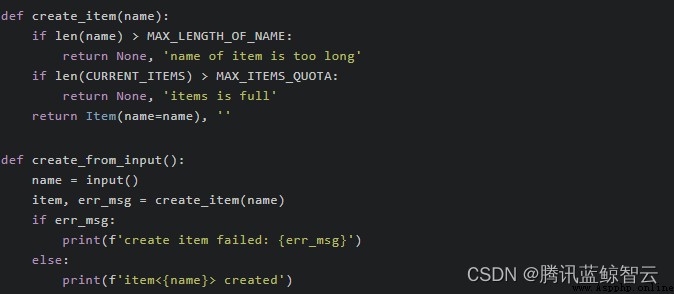 在示例中,
在示例中, create_item 函數的作用是創建新的 Item 對象。同時,為了在出錯時給調用方提供錯誤詳情,它利用了多返回值特性,把錯誤信息作為第二個結果返回。
乍看上去,這樣的做法很自然。尤其是對那些有 Go 語言編程經驗的人來說更是如此。但是在 Python 世界裡,這並非解決此類問題的最佳辦法。因為這種做法會增加調用方進行錯誤處理的成本,尤其是當很多函數都遵循這個規范而且存在多層調用時。
Python 具備完善的異常(Exception)機制,並且在某種程度上鼓勵我們使用異常(官方文檔關於 EAFP 的說明)。所以,使用異常來進行錯誤流程處理才是更地道的做法。
引入自定義異常後,上面的代碼可以被改寫成這樣: 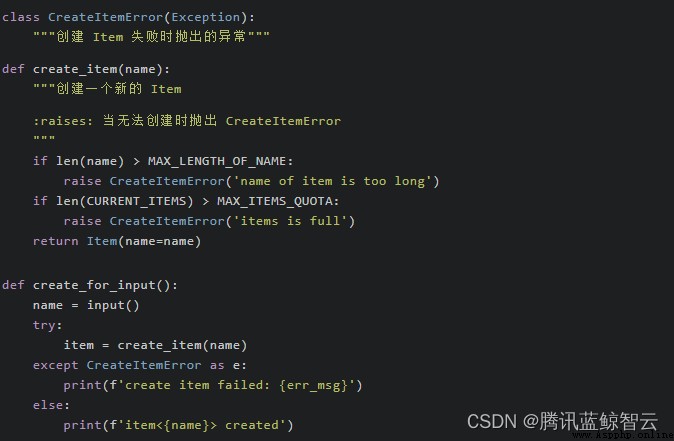 使用“拋出異常”替代“返回 (結果, 錯誤信息)”後,整個錯誤流程處理乍看上去變化不大,但實際上有著非常多不同,一些細節:
使用“拋出異常”替代“返回 (結果, 錯誤信息)”後,整個錯誤流程處理乍看上去變化不大,但實際上有著非常多不同,一些細節:
Item 類型或是拋出異常create_item 的一級調用方完全可以省略異常處理,交由上層處理。這個特點給了我們更多的靈活性,但同時也帶來了更大的風險。Hint:如何在編程語言裡處理錯誤,是一個至今仍然存在爭議的主題。比如像上面不推薦的多返回值方式,正是缺乏異常的 Go 語言中最核心的錯誤處理機制。另外,即使是異常機制本身,不同編程語言之間也存在著差別。 異常,或是不異常,都是由語言設計者進行多方取捨後的結果,更多時候不存在絕對性的優劣之分。但是,單就 Python 語言而言,使用異常來表達錯誤無疑是更符合 Python 哲學,更應該受到推崇的。
None 值通常被用來表示“某個應該存在但是缺失的東西”,它在 Python 裡是獨一無二的存在。很多編程語言裡都有與 None 類似的設計,比如 JavaScript 裡的 null、Go 裡的 nil 等。因為 None 所擁有的獨特 虛無 氣質,它經常被作為函數返回值使用。
當我們使用 None 作為函數返回值時,通常是下面 3 種情況。
當某個操作類函數不需要任何返回值時,通常就會返回 None。同時,None 也是不帶任何 return 語句函數的默認返回值。
對於這種函數,使用 None 是沒有任何問題的,標准庫裡的 list.append()、 os.chdir() 均屬此類。
有一些函數,它們的目的通常是去嘗試性的做某件事情。視情況不同,最終可能有結果,也可能沒有結果。而對調用方來說,“沒有結果”完全是意料之中的事情。對這類函數來說,使用 None 作為“沒結果”時的返回值也是合理的。
在 Python 標准庫裡,正則表達式模塊 re 下的 re.search、 re.match 函數均屬於此類,這兩個函數在可以找到匹配結果時返回 re.Match 對象,找不到時則返回 None。
有時, None 也會經常被我們用來作為函數調用失敗時的默認返回值,比如下面這個函數: 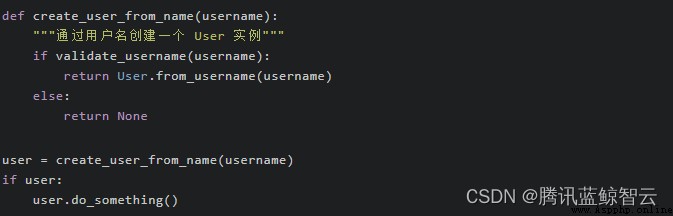 當
當 username 不合法時,函數 create_user_from_name 將會返回 None。但在這個場景下,這樣做其實並不好。
不過你也許會覺得這個函數完全合情合理,甚至你會覺得它和我們提到的上一個“沒有結果”時的用法非常相似。那麼如何區分這兩種不同情形呢?關鍵在於:函數簽名(名稱與參數)與 None 返回值之間是否存在一種“意料之中”的暗示。
讓我解釋一下,每當你讓函數返回 None 值時,請仔細閱讀函數名,然後問自己一個問題:假如我是該函數的使用者,從這個名字來看,“拿不到任何結果”是否是該函數名稱含義裡的一部分?
分別用這兩個函數來舉例:
re.search():從函數名來看, search,代表著從目標字符串裡去搜索匹配結果,而搜索行為,一向是可能有也可能沒有結果的,所以該函數適合返回 Nonecreate_user_from_name():從函數名來看,代表基於一個名字來構建用戶,並不能讀出一種 可能返回、可能不返回的含義。所以不適合返回 None對於那些不能從函數名裡讀出 None 值暗示的函數來說,有兩種修改方式。第一種,如果你堅持使用 None 返回值,那麼請修改函數的名稱。比如可以將函數 create_user_from_name() 改名為 create_user_or_none()。
第二種方式則更常見的多:用拋出異常**(raise Exception)**來代替 None 返回值。因為,如果返回不了正常結果並非函數意義裡的一部分,這就代表著函數出現了“意料以外的狀況”,而這正是 Exceptions 異常 所掌管的領域。
使用異常改寫後的例子: 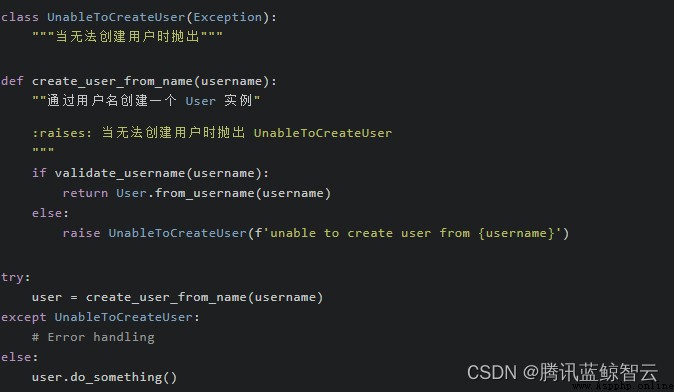 與 None 返回值相比,拋出異常除了擁有我們在上個場景提到的那些特點外,還有一個額外的優勢:可以在異常信息裡提供出現意料之外結果的原因,這是只返回一個 None 值做不到的。
與 None 返回值相比,拋出異常除了擁有我們在上個場景提到的那些特點外,還有一個額外的優勢:可以在異常信息裡提供出現意料之外結果的原因,這是只返回一個 None 值做不到的。
我在前面提到函數可以用 None 值或異常來返回錯誤結果,但這兩種方式都有一個共同的缺點。那就是所有需要使用函數返回值的地方,都必須加上一個 if 或 try/except 防御語句,來判斷結果是否正常。
讓我們看一個可運行的完整示例: 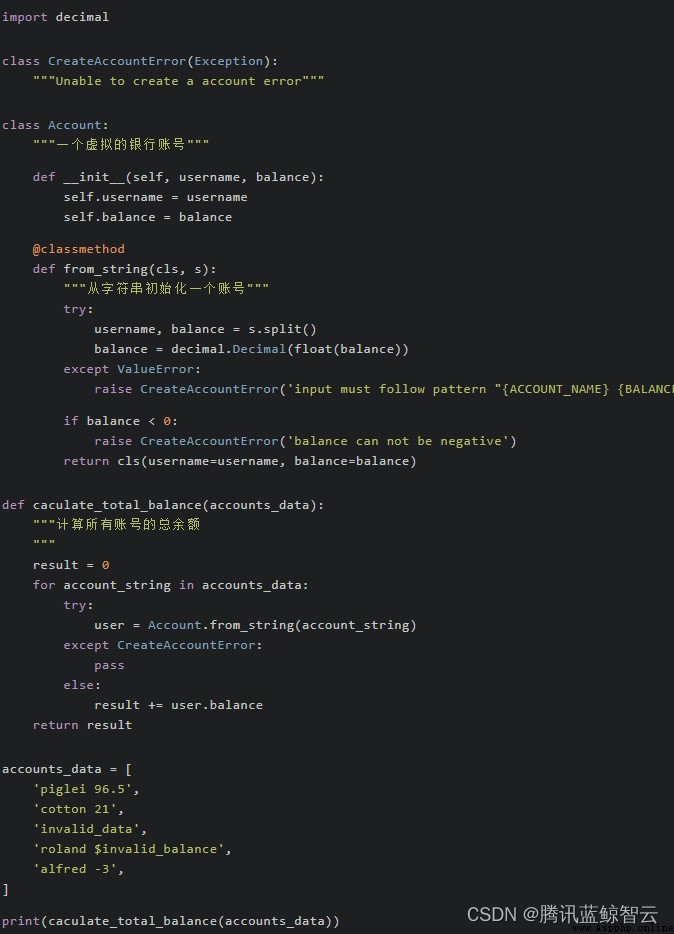
補充圖中顯示不到的為:{BALANCE}" ')
在這個例子裡,每當我們調用 Account.from_string 時,都必須使用 try/except 來捕獲可能發生的異常。如果項目裡需要調用很多次該函數,這部分工作就變得非常繁瑣了。針對這種情況,可以使用“空對象模式(Null object pattern)”來改善這個控制流。
Martin Fowler 在他的經典著作《重構》 中用一個章節詳細說明過這個模式。簡單來說,就是使用一個符合正常結果接口的“空類型”來替代空值返回/拋出異常,以此來降低調用方處理結果的成本。
引入“空對象模式”後,上面的示例可以被修改成這樣: 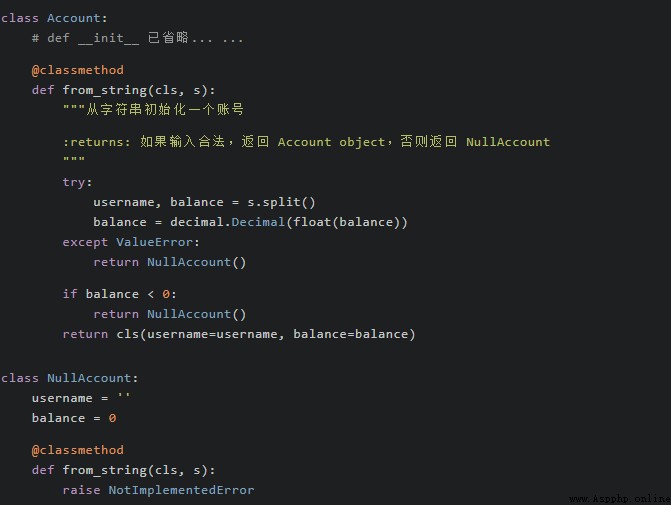 在新版代碼裡,我定義了
在新版代碼裡,我定義了 NullAccount 這個新類型,用來作為 from_string 失敗時的錯誤結果返回。這樣修改後的最大變化體現在 caculate_total_balance 部分:  調整之後,調用方不必再顯式使用
調整之後,調用方不必再顯式使用 try語句來處理錯誤,而是可以假設 Account.from_string 函數總是會返回一個合法的 Account 對象,從而簡化整個計算邏輯。
Hint:在 Python 世界裡,“空對象模式”並不少見,比如大名鼎鼎的 Django 框架裡的 AnonymousUser 就是一個典型的 null object。
在函數裡返回列表特別常見,通常,我們會先初始化一個列表 results=[],然後在循環體內使用 results.append(item) 函數填充它,最後在函數的末尾返回。
對於這類模式,我們可以用生成器函數來簡化它。粗暴點說,就是用 yielditem 替代 append 語句。使用生成器的函數通常更簡潔、也更具通用性。

我在 系列第 4 篇文章“容器的門道” 裡詳細分析過這個模式,更多細節可以訪問文章,搜索 “寫擴展性更好的代碼” 查看。
當函數返回自身調用時,也就是 遞歸 發生時。遞歸是一種在特定場景下非常有用的編程技巧,但壞消息是:Python 語言對遞歸支持的非常有限。
這份“有限的支持”體現在很多方面。首先,Python 語言不支持“尾遞歸優化”。另外 Python 對最大遞歸層級數也有著嚴格的限制。
所以我建議:盡量少寫遞歸。如果你想用遞歸解決問題,先想想它是不是能方便的用循環來替代。如果答案是肯定的,那麼就用循環來改寫吧。如果迫不得已,一定需要使用遞歸時,請考慮下面幾個點:
sys.getrecursionlimit() 規定的最大層數限制functools.lru_cache 的緩存工具函數來降低遞歸層數在這篇文章中,我虛擬了一些與 Python 函數返回有關的場景,並針對每個場景提供了我的優化建議。最後再總結一下要點:
functools.partial 定義快捷函數