目錄
前言
一、分類數據(Categorical data)
離散與分類
實例場景
二、創建
1.Series創建
標簽轉換
2.DataFrame創建
3.操作
1.CategoricalDtype函數
2.unique唯一標簽
三.轉換
點關注,防走丟,如有纰漏之處,請留言指教,非常感謝
時至如今Pandas仍然是十分火熱的基於Python的數據分析工具,與numpy、matplotlib稱為數據分析三大巨頭,是學習Python數據分析的必經之路。Pandas提供了大量能使我們快速便捷地處理數據的函數和方法,它是使Python成為強大而高效的數據分析環境的重要因素之一。
使用Pandas進行數據預處理時需要對Pandas的基礎數據結構Series和DataFrame有一個基礎的了解。若是還不清楚的可以再去看看我之前的詳解博文:
一文速學-數據分析之Pandas數據結構和基本操作代碼
結合Pandas處理不同種類的數據,算下來共有重復值處理、缺失值處理、異常值處理等眾多處理數據的方法。但我們使用Pandas做數據分析進階操作,經常會使用到機器學習算法模型以及神經網絡等算法,需要我們對數據進行預處理操作,其中就有label標簽數據。而Pandas將此類標簽數據單獨提取出作為Catagorical data分類數據。了解處理此類型數據能夠高效提升對我們進行數據進行建模和分析。對數據分析處理感興趣的還可以閱讀博主前幾篇詳解博文:
一文速學-Pandas異常值檢測及處理操作各類方法詳解+代碼展示
一文速學-Pandas處理重復值操作各類方法詳解+代碼展示
一文速學-Pandas處理缺失值操作各類方法詳解
以上三篇很容易學會,沒有比較難的實戰。此篇博客基於Jupyter之上進行演示,本篇博客的願景是希望我或者讀者通過閱讀這篇博客能夠學會方法並能實際運用,而且能夠記錄到你的思想之中。希望讀者看完能夠提出錯誤或者看法,博主會長期維護博客做及時更新。
分類是與統計中的分類變量相對應的數據類型。分類變量具有有限且通常固定的可能值數量(類別;R因子級別)。例如性別、社會階層、血型、國家歸屬、觀察時間或通過李克特量表進行的評級。
在學習該數據類型之前,我給大家稍微講講統計學的一些相關知識,方便大家後續理解函數的相關操作。根據數據類型我們可以可以將數據分為兩種類型:
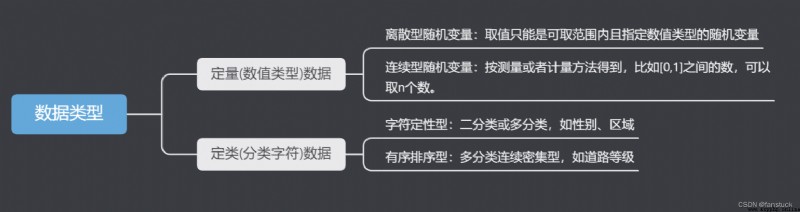
在統計學中,數據按變量值是否連續可分為連續數據與離散數據兩種.
性質:符號x如果能夠表示對象集合S中的任意元素,就是變量。如果變量的域(即對象的集合S)是離散的,該變量就是離散變量;如果它的域是連續的,它就是連續變量。
與統計分類變量相比,分類數據可能有一個順序(例如“強烈同意”與“同意”或“第一次觀察”與“第二次觀察”),但不可能進行數值運算(加法、除法等)。 在R語言基礎之中,名義型變量和有序型變量稱為因子,這些分類變量的可能值稱為一個水平,level,例如good,better,best,都稱為一個level。由這些水平值構成的向量就稱為因子。我們發現R語言的因子和Pandas的Catagorical data數據類型幾乎差不多。分類數據的所有值要麼在類別中,要麼就是np.nan。順序是由類別的順序定義的,而不是值的詞匯順序。在內部,數據結構由一個類別數組和一個整數代碼數組組成,這些代碼指向類別數組中的實值。
通過Series創建只需要在創建語句後面加上dtype="catagory":
series_cate=pd.Series(["a", "b", "c", "a"], dtype="category")通過DataFrame創建後使用一列astype直接轉換就好了:
df = pd.DataFrame({"A": ["a", "b", "c", "a"]})
df["B"] = df["A"].astype("category")
df.dtypes
通過使用自定義函數或者功能函數,例如cut(),能夠將數值特征通過范圍打上標簽:
df = pd.DataFrame({"value": np.random.randint(0, 100, 20)})
labels = ["{0} - {1}".format(i, i + 9) for i in range(0, 100, 10)]
df["group"] = pd.cut(df.value, range(0, 105, 10), right=False, labels=labels)
df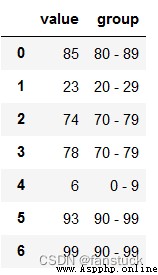
通過Categorical函數可以實現更高級的標簽轉換:
raw_cat=pd.Categorical(df['group'], categories=['40 - 49','60 - 69'])
df["group2"] = raw_cat
df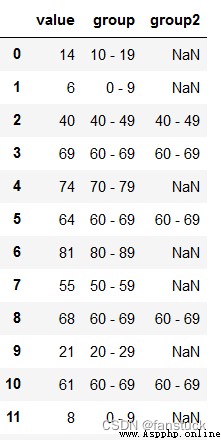
可以去除空值保留想要保留的特征。
DataFrama可以整個轉化為Catagory
df = pd.DataFrame({"A": ["a", "b", "c", "a"],"B":[1,2,3,4]},dtype="category")
df.dtypes
或者和轉換一列一樣全部轉換為category:
df = pd.DataFrame({"A": ["a", "b", "c", "a"],"B":[1,2,3,4]})
df_cat = df.astype("category")
df_cat.dtypes 
在上面傳遞dtype='category'的示例中參數均為默認,默認轉換的category的類別:.
若需要控制上述兩種情況,需要引入CategoricalDtype函數:
from pandas.api.types import CategoricalDtype
s = pd.Series(["a", "b", "c", "a"])
cat_type = CategoricalDtype(categories=["b", "c", "d"], ordered=True)
s_cat = s.astype(cat_type)
s_cat 
上述代碼就是在默認情況下,轉換為category類型並沒有設定categories,可以通過CategoricalDtype後期加上去。
對於DataFrame也是如此:
from pandas.api.types import CategoricalDtype
df = pd.DataFrame({"A": ["a", "b", "c", "a"],"B":[1,2,3,4]})
cat_type = CategoricalDtype(categories=list("abcd"), ordered=True)
df_cat = df.astype(cat_type)
df_cat.info 
為了執行逐表轉換,整個DataFrame中的所有標簽都用作每列的類別,可以通過編程方式通過categories=pd.unique(df.to_numpy().ravel())確定categories參數。
df = pd.DataFrame({"A": ["a", "b", "c", "a"],"B":[1,2,3,4]})
categories = pd.unique(df['A'].to_numpy().ravel())
categoriesarray(['a', 'b', 'c'], dtype=object)
如果已經有了代碼和類別,那麼可以使用from_codes()構造函數在正常構造函數模式下保存分解步驟:
splitter = np.random.choice([0, 1], 5, p=[0.5, 0.5])
s = pd.Series(pd.Categorical.from_codes(splitter, categories=["train", "test"])) 
我們知道Category可以通過Series和DataFrame來創建,那麼轉換成原格式也是一樣的:
Series.astype(original_dtype)
np.asarray(categorical)以上就是本期全部內容。我是fanstuck ,有問題大家隨時留言討論 ,我們下期見。
 Django personal blog building --5-- click the list to display the specific content
Django personal blog building --5-- click the list to display the specific content
Preface : The next step is to