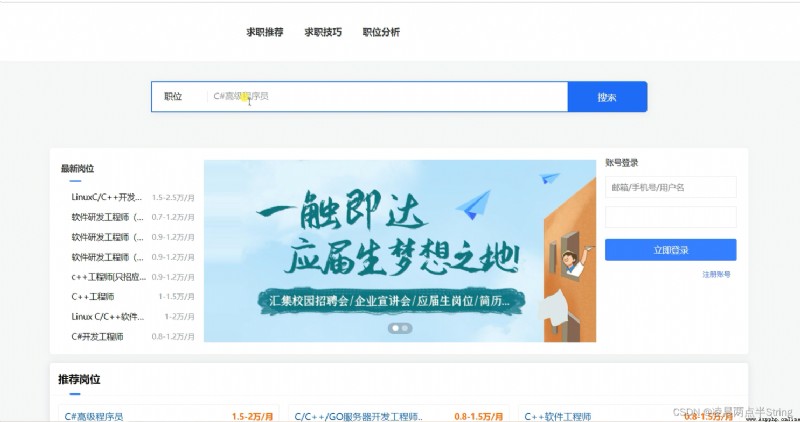
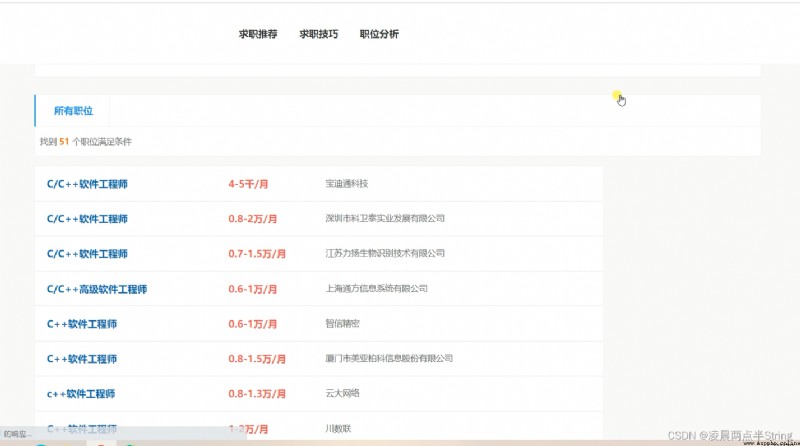
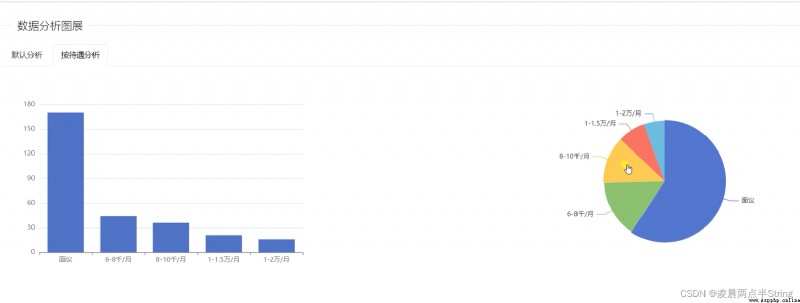
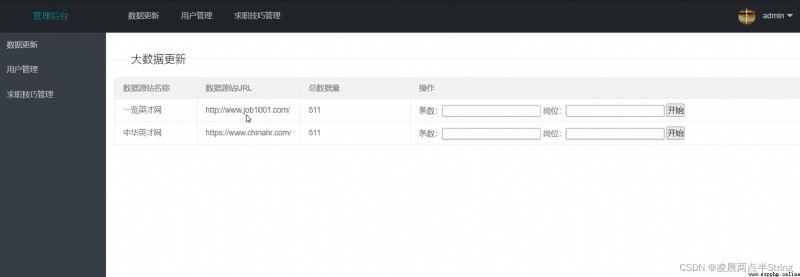
本求職招聘管理系統主要包括系統用戶管理模塊、企業新聞管理模塊、招聘發布會管理、招聘信息管理、登錄模塊、和退出模塊等多個模塊。它幫助求職招聘管理實現了信息化、網絡化,通過測試,實現了系統設計目標,相比傳統的管理模式,本系統合理的利用了求職招聘管理數據資源,有效的減少了求職招聘管理的經濟投入,大大提高了求職招聘管理的效率
計算機畢業設計Python+django的可視化的網頁搜索引擎設計(源碼+系統+mysql數據庫+Lw文檔)
開發語言:Python
python框架:django
軟件版本:python3.7/python3.8
數據庫:mysql 5.7或更高版本
數據庫工具:Navicat11
開發軟件:PyCharm/vs code
前端框架:vue.js
可開發框架:ssm/Springboot/vue/python/PHP/小程序/安卓均可開發

def yilan(tiao=None, zhiwei=None):
url = 'http://www.job1001.com/SearchResult.php'
data = {
'region_1': '', 'jtzw': zhiwei}
a = requests.post(url=url, data=data)
soup = BeautifulSoup(a.text, 'html.parser')
# print(soup)
# 總數
if tiao == '0':
num = soup.find('div', {
"class": 'search_result_sum'}).get_text()[1:-7]
else:
num = tiao
get = "http://www.job1001.com/SearchResult.php?page="
get1 = '&sums=&&parentName=&key=®ion_1=®ion_2=®ion_3=&keytypes=&jtzw='
get3 = '&data=&dqdh_gzdd=&jobtypes=&edus=&titleAction=&provinceName=&sexs=&postidstr=&postname=&searchzwtrade=&gznum=&rctypes=&salary=&showtype=list&sorttype=score#main_search'
qq = 0
if int(num) / 30 is not int:
qq = int(int(num) / 30) + 1
for i in range(0, qq):
res = requests.get(get + str(i) + get1 + zhiwei + get3)
# print(get + str(i) + get1 + 'python' + get3)
soup = BeautifulSoup(res.text, 'html.parser')
a = soup.findAll('a', href=re.compile("job1001.com/jobs/"))
c2 = soup.findAll('a', href=re.compile("job1001.com/jobs/"))
c = soup.findAll('a', href=re.compile("job1001.com/company/"))
d = soup.findAll('li', {
'class': 'search_region'})
e = soup.findAll('li', {
'class': 'search_date'})
f = soup.findAll('li', {
'class': 'search_salary'})
zdata = ZhaoPinData.objects.filter(id=1)
if zdata is None:
id = 0
else:
id = ZhaoPinData.objects.all().count()
# 崗位名稱
for i in a:
ZhaoPinData.objects.create(name=i.get_text())
# print(i.get_text())
# 公司名稱
num1 = id
for i in c:
i22 = str(i.get_text)
a1 = i22.find('title="')
a2 = i22.find('">')
c23 = i22[int(a1) + 7:int(a2)]
num1 = num1 + 1
ZhaoPinData.objects.filter(id=num1).update(qiyename=c23)
# zdata['qiyename'] = c
# print(c)
num1 = id
# 源站鏈接
for a in c2:
i = str(a)
a1 = i.find('href="http://')
a2 = i.find(' target="_blank" title="')
q3 = i[int(a1):a2]
q3 = q3.replace('href="', '')
q3 = q3.replace('" rel="nofollow"', '')
q3 = q3.replace('"', '')
# print(q3)
# a = requests.get(url=q3)
# soup11 = BeautifulSoup(a.text, 'html.parser')
# xue = soup11.findAll('li', {'class': 'info_left'})
num1 = num1 + 1
ZhaoPinData.objects.filter(id=num1).update(url=q3,pro=zhiwei)
# href="http://
# .html" rel="nofollow" target="_blank" title="
# 工作地區
num1 = id
for i in d:
i = str(i)
a1 = i.find('region">')
a2 = i.find('</li>')
c = i[a1 + 8:a2]
if c != '工作地區':
num1 = num1 + 1
ZhaoPinData.objects.filter(id=num1).update(diqu=c)
# zdata['diqu'] = c
# 發布時間
num1 = id
for i in e:
i = str(i)
a1 = i.find('search_date">')
a2 = i.find('</li>')
c = i[a1 + 13:a2]
if c != '更新時間':
c = str(c)
timeArray = time.strptime(c, "%Y-%m-%d")
timeStamp = int(time.mktime(timeArray))
num1 = num1 + 1
ZhaoPinData.objects.filter(id=num1).update(time=timeStamp)
# zdata['time'] = c
# 薪資待遇
num1 = id
for i in f:
i = str(i)
a1 = i.find('search_salary">')
a2 = i.find('</li>')
c = i[a1 + 15:a2]
if c != '薪資待遇':
num1 = num1 + 1
ZhaoPinData.objects.filter(id=num1).update(daiyu=c)
ZhaoPinData.objects.filter(id=num1).update(laiyuan='一覽英才網')
ZhaoPinData.objects.filter(id=num1).update(update_time=time.time())
return 'OK'