認知層次結構自底向上分為數據、信息、知識、智慧四個層級。
DIKW體系:
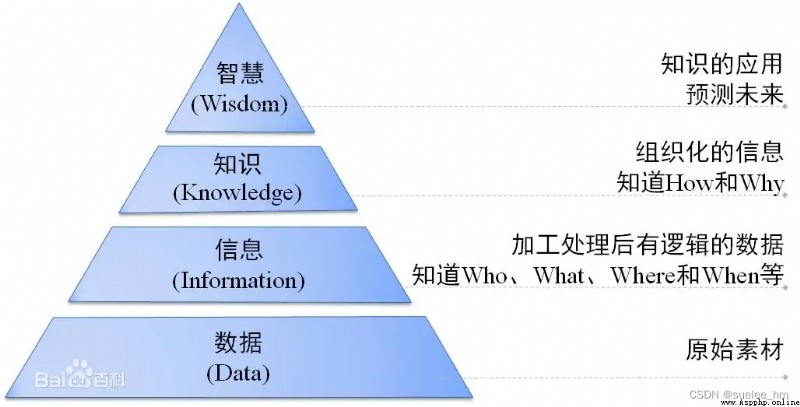
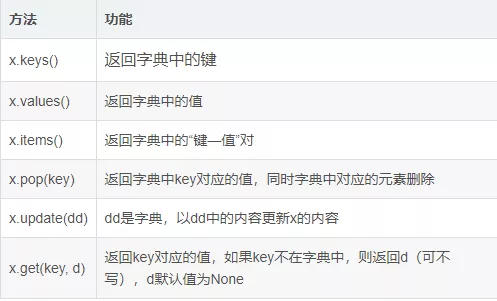
數據是沒有經過組織或處理的文字符號圖像等,來源於事實。數據僅僅代表本身,可以說,數據是孤獨的,比如165,數據165就代表165,沒有別的。
信息是什麼呢,我們通過某種方式對組織或處理數據時,需要進行分析,讓數據之間產生關系,這樣可以用來回答一些簡單的問題,比如誰?哪裡?信息就是有序排列的數據。比如,165後面加上cm就變成身高,當然具體是什麼,還要結合語境。
知識就是判斷信息是否有用的過程,這個過程結合上下文,诠釋,反省。信息結合越多,就越容易判斷正誤。比如女性身高165cm,這是通過對信息的诠釋,得出的一個判斷結論,這是一個積累過程。
智慧,做正確判斷的能力,和對知識的正確使用,智慧可以回答為什麼的問題,判斷是非、對錯、好壞,關注未來,試圖理解過去沒有理解的東西,是人類特有的。我們有了女性身高165cm的知識,當我們想要給女朋友買一件衣服的時候,我們就會選出適合的尺碼,而不會選擇一件童裝。
比如,榴蓮是數據,好吃或不好吃是信息,嘗過一下直接實踐後得到的經驗,這是知識產生的過程,吃過以後有了判斷這就是智慧。
這些都是人類的認知發展過程。
信息和數據的關系:
數據是信息的載體,是信息的表現形式。因此,如果一個數據被賦予了意義,就可以被稱作是信息。因此我們可以認為沒有數據就沒有信息,數據是信息的來源。[1]
數據是記錄,是載體,是呈現方式,而且方式不限於電子;信息則是內容,是數據的內涵,信息是加載於數據之上,對數據作具有含義的解釋。
信息有意義,而數據沒有。因此,我們將數據處理之後的結果稱為信息,可以看出信息具有針對性、時效性的特點。也可以認為,數據比較具象,而信息比較抽象。
數據是原始事實,而信息是數據處理的結果。
不同知識、經驗的人,對於同一數據的理解,可得到不同信息。
人類作為文字的發明者和使用者,通過文字來表示和傳達信息,是一種非常自然的方式。但在計算機中,卻不能通過文字來表示信息,因為機器無法理解文字。
計算機由邏輯電路組成,邏輯電路通常只有兩種物理狀態:“打開”的狀態和“關閉”的狀態。這兩種狀態正好可以用數字1和0來進行表示,使用1表示打開的狀態,0表示關閉的狀態。[2]
這種使用數字1和0來表示信息的方法,稱為二進制表示法。那麼如何讓只能讀懂0和1的計算機讀懂人類的文字呢?這就需要給計算機做一本字典,把文字翻譯成計算機的語言,也就是不同的0和1組合與文字做一個對應關系,這就是計算機編碼。
比如如在計算機中輸入“我喜歡你”,計算機看不懂你說的什麼,因為他只能讀懂0和1這些數字呀。所以呢,我們先在計算機中編寫一本字典告訴它:

這時候計算機就會對照這本字典來理解的你的意思,哦,原來你說的是000 001 010 011。
在現實中,人們已經做了這項工作,當然這個字典全世界通用的,否則一個地方的計算機就無法識別另一個地方的計算機數據了。
計算機用01組合表示一個字符, 一個字節能表示2^8=255種組合。
通過這種編碼工作,就可以把人類的文字翻譯成二進制數據,這樣計算機便可以處理這些數據了。
為保證人類和設備,設備和計算機之間能進行正確的信息交換,人們編制的統一的信息交換代碼,這就是ASCII碼表,它的全稱是“美國信息交換標准代碼”。
通過這種編碼工作,就可以把人類的文字翻譯成二進制數據,這樣計算機便可以處理這些數據了。
例如:查表得 A 的ASCII碼值為(01000001)2=(41)16=65;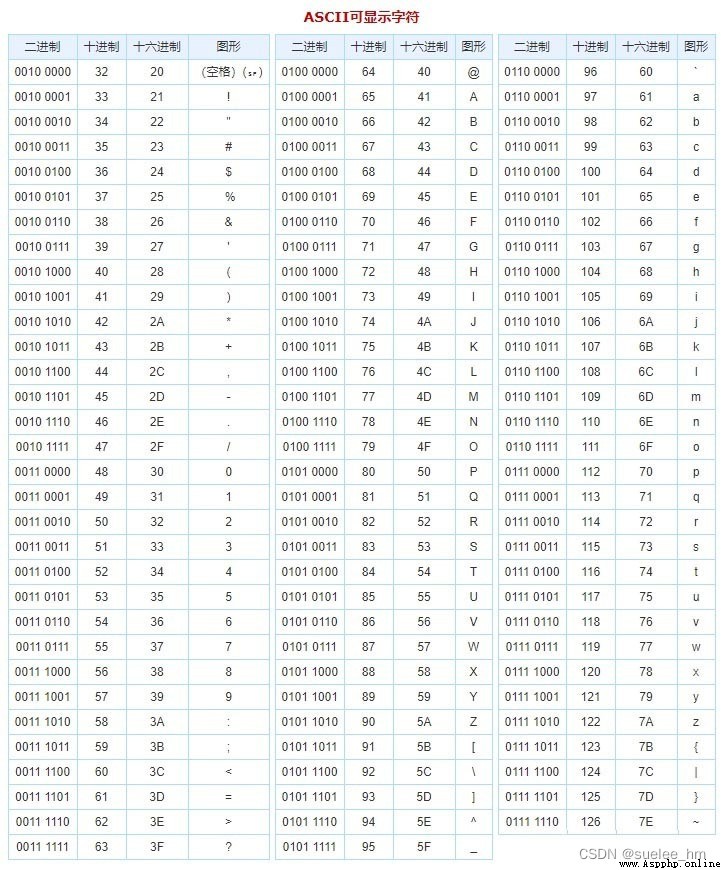
因為計算機是外國人發明的,他們使用的是英文,所有就沒有考慮中文漢字的編碼問題,為了用0、1代碼串表示漢字,我國制定了漢字的信息交換碼GB2312-80,簡稱國標碼。
由於漢字的字符多,一個字節的二進制不能包含全部漢字,所有國標碼的每一個符號都用兩個字節(16位二進制)代碼來表示。
國標碼共有字符7445個。一級漢字3755個,按漢語拼音順序排列;二級漢字3008個,按部首和筆畫排列。
隨著計算機的普及,每個非英文國家各自編制了自己的一套編碼, 始終得不到同一,於是Unicode應運而生。所有語言編碼統一到Unicode編碼裡,這樣就不出現亂碼的問題了。
unicode編碼都是倆字節的, 偏僻的可能用了四字節。
編碼的存儲:
如果我們需要編碼的文本都是英文的, 那麼用unicode的兩個字節是不是很浪費,明明一個字節就可以,卻用了兩字節。
為了節約, 出現了utf-8編碼, UTF-8編碼把一個Unicode字符根據不同的數字大小編碼成1-6個字節,常用的英文字母被編碼成1個字節,漢字通常是3個字節,只有很生僻的字符才會被編碼成4-6個字節。如果你要傳輸的文本包含大量英文字符,用UTF-8編碼就能節省空間。
Unicode和utf-8的關系:
在內存裡統一使用unicode,記錄到硬盤或者編輯文本的時候都轉換成了utf8。
Unicode 統一字符編碼,給每一個字符一個唯一編碼,保證不重復。
UTF-8 將Unicode編碼後的字符串保存到硬盤的一種壓縮編碼方式。
比特(位bit):
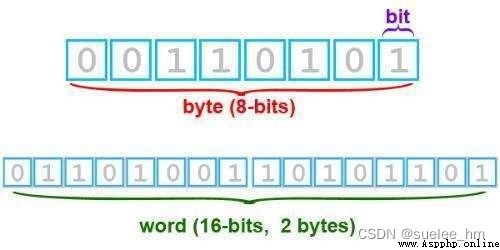
位也叫比特,比特也叫位。32bit,64bit(也稱32位,64位)1字節(Byte) = 8比特(位bit)1比特(位bit) = 1個2進制位字節(Byte):
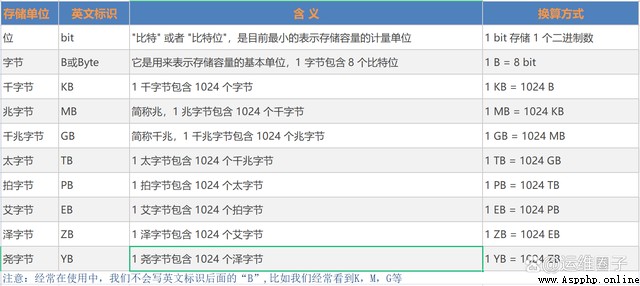
(在編程中,分析變量在內存布局最常用的是字節單位,因此KB不會用到,再大計量單位還有兆(MB),GB,TB)。
1比特 = 1個2進制位
1字節=8比特
因此1字節 = 8個二進制位。
計算機存儲容量的基本單位:
計算機存儲容量的基本單位是字節,又名Byte,用大寫字母B表示。比特和字節同為存儲容量的單位,都用來表示計算機的存儲容量大小,但是兩者是不一樣的,比特是計算機存儲容量的最小單位;字節是計算機中存儲容量的基本單位。
什麼是字節?
字節,是英文單詞 Byte的中文翻譯,是計算機中存儲容量的常用單位,實際意義上表示一組8個二進制位。舉個例子,一個英文字母,通常用8個二進制位的編碼表示,那麼存儲的時候,就說這個英文單詞占用一個字節的存儲空間。而一個中文漢字,通常要占用兩個字節的存儲空間。
為什麼存儲容量的基本單位是字節?
從上面字節的定義分析可知,計算機裡面的英文字母和、中文漢字,或者其他計算機符號,都是通過二進制的編碼存儲的,如果用占用多少二進制編碼位來表示存儲容量,將非常不方便,也不好記。如果把這些二進制位,8個分為一組,取名字節,這樣就很方便,也更容易記住,這也和ASCII碼相對應。比如說字母a占用一個字節的存儲空間,比說字母a占用8個二進制位或8個比特為好記得多。這也就是計算機中存儲容量的基本單位用字節的緣故。
所以雖然計算機中存儲容量的表示單位有字節和比特,但是計算機存儲容量的基本單位是字節,而不是比特;比特只是作為計算機存儲容量的最小單位而存在。
二進制和運算:
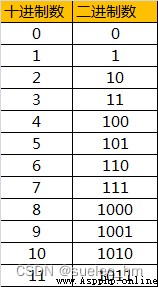
我們平時使用的十進制是逢10進1,同理二進制就是逢2進1。
二進制的運算:

[1]:信息和數據有什麼區別? - 知乎
[2]:Python零基礎入門到精通-3.1節:掌握計算機的信息表示 - 知乎