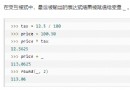
不過PyAudio安裝的時候經常報錯:
pip install pyaudio -i https://pypi.tuna.tsinghua.edu.cn/simple
這裡是用pip安裝,使用的是清華的源來安裝。不過因為pip不能解決依賴關系,所以才報錯。
具體更換的方式可參考清華鏡像的使用幫助。
因此如果是在Anaconda的環境下,則可以使用conda命令來安裝。
這裡也可以配置成國內的源:
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/msys2/
# 設置搜索時顯示通道地址
conda config --set show_channel_urls yes
轉載地址:https://blog.csdn.net/observador/article/details/83618540
清華官方鏡像使用說明。
安裝命令:conda install pyaudio
如果是在Ubuntu下,則可以使用apt來安裝:sudo apt-get install python-pyaudio
如果是安裝的anaconda3,那麼其它的第三方庫就不需要安裝了,如果不是,那麼請根據需求安裝import中的第三方庫。
import pyaudio
import numpy as np
from scipy import fftpack
import wave
import time
回來繼續說語音識別,要搞語音識別,首先就需要錄音,下面有兩種錄音方式:
這種錄音方式較為死板,就是不管你說沒說完話,到時間了就結束錄音,但這種方式的優點就是代碼較為簡單。
def Luyin(filename, times=0):
CHUNK = 1024 # 塊大小
FORMAT = pyaudio.paInt16 # 每次采集的位數
CHANNELS = 1 # 聲道數
RATE = 16000 # 采樣率:每秒采集數據的次數
RECORD_SECONDS = times # 錄音時間
WAVE_OUTPUT_FILENAME = filename # 文件存放位置
p = pyaudio.PyAudio()
stream = p.open(format=FORMAT, channels=CHANNELS, rate=RATE, input=True, frames_per_buffer=CHUNK)
print("* 錄音中...")
frames = []
for i in range(0, int(RATE / CHUNK * RECORD_SECONDS)):
data = stream.read(CHUNK)
frames.append(data)
print("* 錄音結束")
stream.stop_stream()
stream.close()
p.terminate()
if startflag:
with wave.open(WAVE_OUTPUT_FILENAME, 'wb') as wf:
wf.setnchannels(CHANNELS)
wf.setsampwidth(p.get_sample_size(FORMAT))
wf.setframerate(RATE)
wf.writeframes(b''.join(frames))
第二種錄音方式較為靈活,通過設定一個阈值,在聲音大於阈值時開始錄音,小於阈值結束錄音,設定一定時間,來判斷是否是真的結束了說話,而不是停頓。
下面是兩者融合之後的代碼。
如果需要定時錄音則設置times不等於0,如果不需要,則默認為根據音量來控制錄音開關。
def recording(filename, times=0, threshold=7000):
""" :param filename: 文件名 :param time: 錄音時間,如果指定時間,按時間來錄音,默認為自動識別是否結束錄音 :param threshold: 判斷錄音結束的阈值 :return: """
CHUNK = 1024 # 塊大小
FORMAT = pyaudio.paInt16 # 每次采集的位數
CHANNELS = 1 # 聲道數
RATE = 16000 # 采樣率:每秒采集數據的次數
RECORD_SECONDS = times # 錄音時間
WAVE_OUTPUT_FILENAME = filename # 文件存放位置
p = pyaudio.PyAudio()
stream = p.open(format=FORMAT, channels=CHANNELS, rate=RATE, input=True, frames_per_buffer=CHUNK)
print("* 錄音中...")
frames = []
if times > 0:
for i in range(0, int(RATE / CHUNK * RECORD_SECONDS)):
data = stream.read(CHUNK)
frames.append(data)
else:
stopflag = 0
stopflag2 = 0
startflag = False
f3 = False
startTime = time.time()
while True:
data = stream.read(CHUNK)
rt_data = np.frombuffer(data, np.dtype('<i2'))
# print(rt_data*10)
# 傅裡葉變換
fft_temp_data = fftpack.fft(rt_data, rt_data.size, overwrite_x=True)
fft_data = np.abs(fft_temp_data)[0:fft_temp_data.size // 2 + 1]
# 測試阈值,輸出值用來判斷阈值
# print(sum(fft_data) // len(fft_data))
# flags = sum(fft_data) // len(fft_data)
# 判斷麥克風是否停止,判斷說話是否結束,# 麥克風阈值,默認7000
if sum(fft_data) // len(fft_data) > threshold:
stopflag += 1
startflag = True
f3 = True
stopTime = time.time()
else:
stopflag2 += 1
if f3:
stopTime = time.time()
f3 = False
oneSecond = int(RATE / CHUNK)
if stopflag2 + stopflag > oneSecond:
# if stopflag2 > oneSecond // 3 * 2:
if stopflag2 > oneSecond // 3 * 2 and startflag and time.time() - stopTime >= 1.5 or time.time() - startTime > 8:
break
else:
stopflag2 = 0
stopflag = 0
if startflag:
frames.append(data)
print("* 錄音結束")
stream.stop_stream()
stream.close()
p.terminate()
if startflag:
with wave.open(WAVE_OUTPUT_FILENAME, 'wb') as wf:
wf.setnchannels(CHANNELS)
wf.setsampwidth(p.get_sample_size(FORMAT))
wf.setframerate(RATE)
wf.writeframes(b''.join(frames))
錄音完之後,只需要直接上傳音頻文件即可,根據百度的開發文檔,可以直接從json數據中提取出識別結果。
from aip import AipSpeech
''' 你的APPID AK SK 參數在申請的百度雲語音服務的控制台查看'''
APP_ID = '你的app id'
API_KEY = '你的api key'
SECRET_KEY = '你的secret_key'
self.client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
def shiBie(path):
''' 語音識別模塊 path:音頻文件所在路徑 輸出:字符串 '''
with open(path, 'rb') as fp:
voices = fp.read()
try:
result = self.client.asr(voices, 'wav', 16000, {
'dev_pid': 1537, })
# if result["err_no"] == "0":
result_text = result["result"][0]
print("you said: " + result_text)
return result_text
except KeyError:
print("KeyError")
語音合成也很簡單,這裡如果要播放音頻的話還得安裝一個第三方庫playsound。
最後建議封裝成函數,使用的時候可以直接調用。
# 導入AipSpeech AipSpeech是語音識別的Python SDK客戶端
from aip import AipSpeech
''' 你的APPID AK SK 參數在申請的百度雲語音服務的控制台查看'''
APP_ID = ''
API_KEY = ''
SECRET_KEY = ''
client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
result = client.synthesis('你要合成的話', 'zh', 1, {
'vol': 5,
})
# 識別正確返回語音二進制 錯誤則返回dict 參照下面錯誤碼
if not isinstance(result, dict):
with open('auidio.mp3', 'wb') as f:
f.write(result)
from playsound import playsound
#auidio.mp3是文件的名字,這裡必須是mp3文件,且和上面的保存的名字要一致
playsound("auido.mp3")