現實的創作來源於生活的靈感!
項目引入
昨天突然發現有一個比較頭疼的問題,有一份數據是某一個學校的寢室數據,有不同的維度的分類,總的數據大概有4000數據,需要進行分類,然後按照不同分類維度進行表格制作,最後生成8個文件夾,每個文件夾裡面有24個表格,這個就是我們這一個程序的最終實現功能。如果我們用Excel篩選需要點很多次,而且需要幾個人的配合工作,這樣就比較的費力,那麼作為數據分析的Python神器,可不可以解決這個問題了,答案是當然可以!
項目思路
1.首先對這個大量的數據進行導入,用CSV這個庫,然後按照Python的對象進行寫入和解析,最後存儲在pycharm運行內存空間,方便我們下一步操作。2.導入之後我們就需要分類了,這個時候需要我們寫一個算法了,我把它叫做“字典迭代算法”當然是我自己命名的,這個裡面涉及到很多的坑,最後我們需要把這個功能封裝起來。3.數據保存也就是,CSV文件的寫入數據,最後利用Python的內置模塊OS進行文件夾的分類創建,最後實現保存數據,這個時候我們還要解決CSV文件的中文亂碼問題。
源碼和數據集點擊這裡下載喲!!
難點
1.解析數據之後如何分割數據,進行保存2.寫入文件的時候如何解決亂碼問題3.怎樣去結構化我們的代碼程序
代碼介紹
大概的思路就是這樣,下面我們來具體看看這個程序的功能實現的功能步驟
解析數據
# 1.解析CSV海量數據,用字典保存在內存空間
def csv_data():
global dormitory_data
import csv
dormitory_data = []
with open(r"寢室數據.csv", encoding='utf-8-sig') as file:#將你的CSV文件和該程序文件放在一個文件夾下面
f_csv = csv.reader(file)#讀取文件裡面的每一行數據,轉換為列表賦值給新的變量
header = next(f_csv)#利用迭代的方法,直接取出表頭行(標題行),更新f_csv的數據,去除了標題行
for row in f_csv:
data = {}
for index in range(7):
data[header[index]] = row[index]
dormitory_data.append(data)
這裡我們對一份Excel的數據,修改它的後綴名,變成CSV文件的後綴名即可,然後我們就對這個數據進行導入和解析了。
這個解析過程和我們之前的一篇文章《用Python寫一個成績計算系統》的有異曲同工之妙。主要要理解對表頭行的提取很數據迭代解析,最後存儲在一個列表裡面。注意這裡一般都是需要聲明全局變量的。
效果執行

分割數據
# 分割數據,按照數據的特點
def csv_sort():
global dicts
dicts=[];i = 0
dormitory_datas = dormitory_data.copy()#字典迭代刪除迭代數據是一個坑,需要我們時刻更新數據庫值
dormitory_datass= dormitory_data.copy()
for x in dormitory_datass:
b = []
for sort in dormitory_datass:
a_1 = sort["宿捨編號"]
b.append(a_1)
dicts.append(x)
dormitory_data.remove(x)
dormitory_datass=dormitory_data.copy()
if b[i][:3] != b[i+1][:3]:
break
這裡不要小看這個幾行代碼,這個裡面的算法是需要進行反復的測試,才實行的,裡面有幾個坑,真的是有點頭疼,還好最後解決了。
1.首先我們要按照一個算法去分割數據,我們浏覽數據之後發現,每一個組團的1-4棟寢室數據都是有相關聯的,1樓到2樓的寢室編號我們按照前三位的數據節點,進行索引判斷,這樣去迭代每一個數據,然後進行比較,最後如果不同的話,我們就發現那麼肯定是不同的樓層了,需要我們進行分割數據了。
2.但是我們發現我們跳出循環之後,也就是迭代完1樓的寢室數據之後,我們驚奇的字典的數據雖然是變化了,但是唯獨也發生了變化,這個就是第一個坑,因為列表的刪除有一個特點,它是利用迭代索引進行刪除的,這個在我之前的計算機二級Python程序語言設計-疑難雜症知識點匯總,提到了這個解決辦法。我最後利用字典的復制存儲,不斷的去更新和彌補這個數據字典,bug才解決,這個時候真的需要靜下心來慢慢思索。
3.利用字典迭代算法,判斷什麼時候需要分割數據,最後封裝這個函數功能。
保存數據
#保存數據,按照不同的分類
def keep_data():
import csv
import os
import codecs
for w in range(65,73):
W=chr(w)
path = '%s棟寢室'%W # 創建總的文件夾
if not os.path.exists(path):
os.mkdir(path)
os.chdir(path)
else:
os.chdir(path)
a = []
dict = dormitory_data[0]
for headers in dict.keys(): # 把字典的鍵取出來,注意不要使用sorted不然會導致鍵的順序改變
a.append(headers)
header = a # 把列名給提取出來,用列表形式呈現
for k in range(1,5):
K=k
for p in range(1,7):
P=p
csv_sort()
with open('%s組%d棟%d樓.csv'%(W,K,P ),'a', newline='', encoding='utf-8-sig') as f:
writer = csv.DictWriter(f, fieldnames=header,) # 提前預覽列名,當下面代碼寫入數據時,會將其一一對應。
writer.writeheader() # 寫入列名
writer.writerows(dicts) # 寫入數據
print("{}組{}棟寢室{}樓數據已經寫入成功!!!! ! !".format(W,K,P))
這個功能同樣有幾個坑,首先我們需要對數據設計好迭代for循環保存,並且利用OS模塊繼續自動的創建文件夾,最後對其數據進行命名,方便我們查看還有就是我們的CSV文件裡面的編碼是utf-8模式,但是Excel裡面的編碼不同,這個就會造成我們的中文數據形式的亂碼問題。
所以我們就去用了這個辦法來解決了
encoding='utf-8-sig'
下面我們來看看整體操作的演示效果
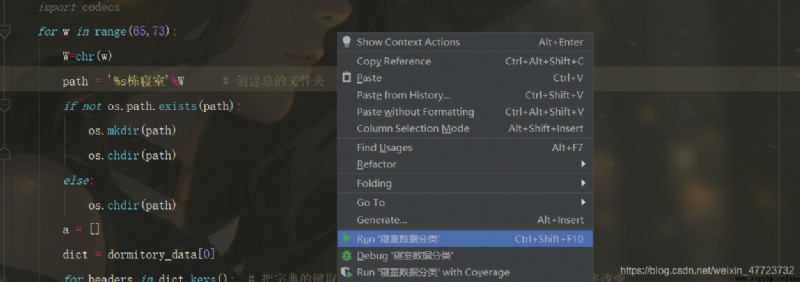

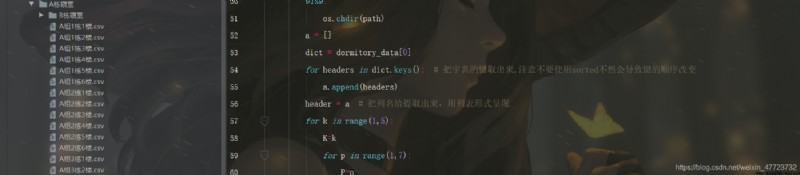
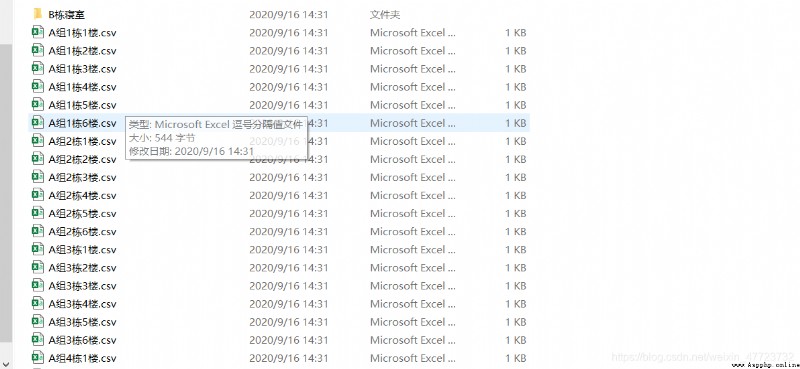

代碼升級版
1.我們還可以參考一些辦法,對這個表格數據進行自動制作,添加頭部文件信息,當然我這裡就不做演示了,你們可以自己去尋找不同的解決方法。2.我們還可以對數據表格進行網格線繪制,使其我們的表格更加美觀,比如字體居中等3.編寫一個自動打印的程序,鏈接到我們的電腦打印機,一鍵化打印這些數據,極大地提高了我們的效率。
這些功能讀者可以自己去實現,我這裡就不做說明了,畢竟代碼的涉及和項目不容易,哈哈哈哈!
自動化辦公,一鍵化處理,本來就是Python的強項,我們可以利用它的功能來解決我們學習生活的難題,最後我想致敬那些每天為了數據整理,瘋狂的點擊Excel的工作人員,畢竟這個東西頭大,難搞,枯燥,乏味
最後我想要說的是雖然設計項目程序比較的頭疼,但是它可以移植,並且不斷的升級,最後別人用1個小時,你只需要3秒鐘運行查看即可!
程序源碼
# -*- coding : utf-8 -*-
# @Time : 2020/9/15 13:26
# @author : 王小王
# @Software : PyCharm
# @File : 寢室數據分類.py-1.0版本
# @CSDN : https://blog.csdn.net/weixin_47723732
# 1.解析CSV海量數據,用字典保存在內存空間
def csv_data():
global dormitory_data
import csv
dormitory_data = []
with open(r"寢室數據.csv", encoding='utf-8-sig') as file:#將你的CSV文件和該程序文件放在一個文件夾下面
f_csv = csv.reader(file)#讀取文件裡面的每一行數據,轉換為列表賦值給新的變量
header = next(f_csv)#利用迭代的方法,直接取出表頭行(標題行),更新f_csv的數據,去除了標題行
for row in f_csv:
data = {}
for index in range(7):
data[header[index]] = row[index]
dormitory_data.append(data)
# 分割數據,按照數據的特點
def csv_sort():
global dicts
dicts=[];i = 0
dormitory_datas = dormitory_data.copy()#字典迭代刪除迭代數據是一個坑,需要我們時刻更新數據庫值
dormitory_datass= dormitory_data.copy()
for x in dormitory_datass:
b = []
for sort in dormitory_datass:
a_1 = sort["宿捨編號"]
b.append(a_1)
dicts.append(x)
dormitory_data.remove(x)
dormitory_datass=dormitory_data.copy()
if b[i][:3] != b[i+1][:3]:
break
#保存數據,按照不同的分類
def keep_data():
import csv
import os
import codecs
for w in range(65,73):
W=chr(w)
path = '%s棟寢室'%W # 創建總的文件夾
if not os.path.exists(path):
os.mkdir(path)
os.chdir(path)
else:
os.chdir(path)
a = []
dict = dormitory_data[0]
for headers in dict.keys(): # 把字典的鍵取出來,注意不要使用sorted不然會導致鍵的順序改變
a.append(headers)
header = a # 把列名給提取出來,用列表形式呈現
for k in range(1,5):
K=k
for p in range(1,7):
P=p
csv_sort()
with open('%s組%d棟%d樓.csv'%(W,K,P ),'a', newline='', encoding='utf-8-sig') as f:
writer = csv.DictWriter(f, fieldnames=header,) # 提前預覽列名,當下面代碼寫入數據時,會將其一一對應。
writer.writeheader() # 寫入列名
writer.writerows(dicts) # 寫入數據
print("{}組{}棟寢室{}樓數據已經寫入成功!!!! ! !".format(W,K,P))
def main():
csv_data()
keep_data()
if __name__ == '__main__':
main()
每文一語
學以致用,方能學以為用!