HTTP Protocol is a form of data interaction between server and client .
Common request header information :
Common response header information
Safe HTTP( Hypertext transfer ) agreement . Here security involves data encryption .
encryption :
There is no guarantee that the client gets the secret key sent by the server .
The server submits the public key to the certificate authority first , After passing the audit, the public key is digitally signed , Encapsulate the public key into the certificate , Then send the certificate to the client . After the client gets the certificate, the public key must be provided by the server .
There are two modules of network request, including ,urllib( It's old , More trouble ) and requests( Very concise , Very efficient ).
requests characteristic :
requests effect :
requests Module coding process :
Strictly follow the process of the browser sending the request .
Environmental installation :pip install requests
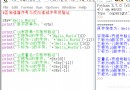
Actual code :
import requests
if __name__ == "__main__":
#step1 Appoint URL
url = "https://www.sogou.com/"
#step2 Initiate request
#get Method will return a response object
response = requests.get(url=url)
#step3 Get response data , What is returned is the response data in the form of string
page_text = response.text
print(page_text)
#step4 Persistent storage
with open('./sougou.html','w',encoding='utf-8') as fp:
fp.write(page_text)
print(' End of crawling data !!!')