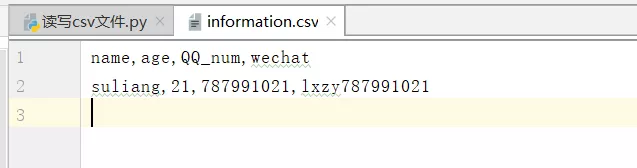
請問如何把這個能改成基於django框架,通過web再浏覽器上實現智能回答
import os
import time
import logging
from collections import deque
import jieba
import jieba.posseg as pseg
from utils import get_logger, similarity
jieba.dt.tmp_dir = "./"
jieba.default_logger.setLevel(logging.ERROR)
logger = get_logger('faqrobot', logfile="faqrobot.log")
class zhishiku(object):
def init(self, q): # a是答案(必須是1給), q是問題(1個或多個)
self.q = [q]
self.a = ""
self.sim = 0
self.q_vec = []
self.q_word = []
def __str__(self): return 'q=' + str(self.q) + '\na=' + str(self.a) + '\nq_word=' + str(self.q_word) + '\nq_vec=' + str(self.q_vec) # return 'a=' + str(self.a) + '\nq=' + str(self.q)class FAQrobot(object):
def init(self, zhishitxt='test.txt', lastTxtLen=10, usedVec=False):
# usedVec 如果是True 在初始化時會解析詞向量,加快計算句子相似度的速度
self.lastTxt = deque([], lastTxtLen)
self.zhishitxt = zhishitxt
self.usedVec = usedVec
self.reload()
def load_qa(self): print('問答知識庫開始載入') self.zhishiku = [] with open(self.zhishitxt, encoding='utf-8') as f: txt = f.readlines() abovetxt = 0 # 上一行的種類: 0空白/注釋 1答案 2問題 for t in txt: # 讀取FAQ文本文件 t = t.strip() if not t or t.startswith('#'): abovetxt = 0 elif abovetxt != 2: if t.startswith('【問題】'): # 輸入第一個問題 self.zhishiku.append(zhishiku(t[4:])) abovetxt = 2 else: # 輸入答案文本(非第一行的) self.zhishiku[-1].a += '\n' + t abovetxt = 1 else: if t.startswith('【問題】'): # 輸入問題(非第一行的) self.zhishiku[-1].q.append(t[4:]) abovetxt = 2 else: # 輸入答案文本 self.zhishiku[-1].a += t abovetxt = 1 for t in self.zhishiku: for question in t.q: t.q_word.append(set(jieba.cut(question)))def load_embedding(self): from gensim.models import Word2Vec if not os.path.exists('Word60.model'): self.vecModel = None return # 載入60維的詞向量(Word60.model,Word60.model.syn0.npy,Word60.model.syn1neg.npy) self.vecModel = Word2Vec.load('Word60.model') for t in self.zhishiku: t.q_vec = [] for question in t.q_word: t.q_vec.append({t for t in question if t in self.vecModel.index2word})def reload(self): self.load_qa() self.load_embedding() print('問答知識庫載入完畢')def maxSimTxt(self, intxt, simCondision=0.1, simType='simple'): """ 找出知識庫裡的和輸入句子相似度最高的句子 simType=simple, simple_POS, vec """ self.lastTxt.append(intxt) if simType not in ('simple', 'simple_pos', 'vec'): return 'error: maxSimTxt的simType類型不存在: {}'.format(simType) # 如果沒有加載詞向量,那麼降級成 simple_pos 方法 embedding = self.vecModel if simType == 'vec' and not embedding: simType = 'simple_pos' for t in self.zhishiku: questions = t.q_vec if simType == 'vec' else t.q_word in_vec = jieba.lcut(intxt) if simType == 'simple' else pseg.lcut(intxt) t.sim = max( similarity(in_vec, question, method=simType, embedding=embedding) for question in questions ) maxSim = max(self.zhishiku, key=lambda x: x.sim) logger.info('maxSim=' + format(maxSim.sim, '.0%')) if maxSim.sim < simCondision: return '抱歉,我沒有理解您的意思。請您轉到人工客服。' return maxSim.adef answer(self, intxt, simType='simple'): """simType=simple, simple_POS, vec, all""" if not intxt: return '' if simType == 'all': # 用於測試不同類型方法的准確度,返回空文本 for method in ('simple', 'simple_pos', 'vec'): outtext = 'method:\t' + self.maxSim(intxt, simType=method) print(outtext) return '' else: outtxt = self.maxSimTxt(intxt, simType=simType) # 輸出回復內容,並計入日志 return outtxtif name == 'main':
robot = FAQrobot('test.txt', usedVec=False)
while True:
# simType=simple, simple_pos, vec, all
print('回復:' + robot.answer(input('輸入:'), 'simple_pos') + '\n')