Some understanding of python3 (decorator, garbage collection, process thread cooperation, global interpreter lock, etc.)
編輯:Python
List of articles
One 、 What is? *args and **kwargs?
1.1 Why is there *args and **kwargs?
1.2 *args and **kwargs What is the purpose of ?
1.3 *args What is it? ?
1.4 **kwargs What is it? ?
1.5 *args And **kwargs What's the difference ?
Two 、 What is a decorator ?
2.1 What is a decorator ?
2.2 How to use the decorator ?
3、 ... and 、Python Garbage collection (GC)
3.1 What are the garbage collection algorithms ?
3.2 Reference count ( The main ) What is it? ?
3.3 Mark - What is purge ?
3.4 What is generational recycling ?
Four 、python Of sorted Function press... On the dictionary key Sort and press value Sort
4.1 python Of sorted What is a function ?
4.2 python Of sorted Function example ?
5、 ... and 、 Direct assignment 、 Shallow copy and deep copy
5.1 The concept is introduced
5.2 Introduce
5.3 Variable definition process
5.3 assignment
5.4 Shallow copy
5.5 Deep copy
5.6 The core : Immutable object type and Variable object types
5.6.1 Immutable object type
5.6.2 Variable object types
6、 ... and 、 process 、 Threads 、 coroutines
6.1 process
6.1.1 What is a process ?
6.1.2 How processes communicate ?
6.2 Threads
6.2.1 What is thread ?
6.2.2 How threads communicate ?
6.3 process vs Threads
6.3.1 difference
6.3.2 Application scenarios
6.4 coroutines
6.4.1 What is a journey ?
6.4.2 The advantages of synergy ?
7、 ... and 、 Global interpreter lock
7.1 What is a global interpreter lock ?
7.2 GIL What's the role ?
7.3 GIL What's the impact? ?
7.4 How to avoid GIL The impact ?
One 、 What is? *args and **kwargs?
1.1 Why is there *args and **kwargs?
For some written functions , May not know in advance , How many arguments will function users pass to you , So use these two keywords in this scenario .
1.2 *args and **kwargs What is the purpose of ?
*args and **kwargs Mainly used for function definition . You can pass an indefinite number of arguments to a function ;
1.3 *args What is it? ?
Introduce : Used to send a variable number of parameter lists of non key value pairs to a function ;
give an example
def test_var_args(f_arg, *argv):
print("first normal arg:", f_arg)
for arg in argv:
print("another arg through *argv:", arg)
test_var_args('yasoob', 'python', 'eggs', 'test')
# output
first normal arg: yasoob
another arg through *argv: python
another arg through *argv: eggs
another arg through *argv: test
1.4 **kwargs What is it? ?
Introduce : Key value pairs of indefinite length are allowed , Pass as an argument to a function . If you want to handle named arguments in a function , You should use kwargs;
give an example :
def greet_me(**kwargs):
for key, value in kwargs.items():
print("{0} == {1}".format(key, value))
# output
>>> greet_me(name="yasoob")
name == yasoob
Essence of decorator : One Python A function or class ;
effect : You can let other functions or classes add additional functionality without any code changes , The return value of the decorator is also a function / Class object .
Use scenarios : It is often used in scenarios with cross-sectional requirements , such as : Inserting log 、 Performance testing 、 Transaction processing 、 cache 、 Permission check and other scenarios , Decorators are an excellent design for this type of problem .
advantage : We have decorators , We can extract a lot of the same code that has nothing to do with the function itself and reuse it again . General speaking , The purpose of a decorator is to add extra functionality to existing objects .
2.2 How to use the decorator ?
Simple decorator
def use_logging(func):
def wrapper():
logging.warn("%s is running" % func.__name__)
return func() # hold foo When passed in as a parameter , perform func() It's like execution foo()
return wrapper
def foo():
print('i am foo')
foo = use_logging(foo) # Because of the decorator use_logging(foo) The returned function object wrapper, This statement is equivalent to foo = wrapper
foo() # perform foo() It's like execution wrapper()
@ Grammatical sugar
def use_logging(func):
def wrapper():
logging.warn("%s is running" % func.__name__)
return func()
return wrapper
@use_logging
def foo():
print("i am foo")
foo()
Parameter decorator
# function : Load data
def loadData(filename):
''' function : Load data input: filename String File name return: data List Data list '''
data = []
with open(filename,"r",encoding="utf-8") as f:
line = f.readline().replace("\n","")
while line:
data.append(line)
line = f.readline().replace("\n","")
return data
# function : Decorator And Data sampling
def simpleData(func):
''' function : Decorator And Data sampling '''
def wrapper(*args):
dataList = func(*args)
rate = 0.05
dataListLen = len(dataList)
if dataListLen>100000:
rate = 0.001
elif dataListLen>10000:
rate = 0.01
elif dataListLen>1000:
rate = 0.05
elif dataListLen>100:
rate = 0.1
else:
rate =1
shuffle(dataList)
simpleDataList =dataList[:int(rate*len(dataList))]
return dataList,simpleDataList
return wrapper
# Use
dataList,simpleDataList = simpleData(loadData)(f"{
basePath}{
name}.txt")
3、 ... and 、Python Garbage collection (GC)
3.1 What are the garbage collection algorithms ?
Reference count
Mark - eliminate
Generational recycling
3.2 Reference count ( The main ) What is it? ?
The core : The core of every object is a structure PyObject, It has a reference counter inside (ob_refcnt)
typedef struct_object {
int ob_refcnt;
struct_typeobject *ob_type;
} PyObject;
Introduce : stay Python At the core of each object in a structure is a structure PyObject, It has a reference counter inside (ob_refcnt). The program will be updated in real time in the process of running ob_refcnt Value , To reflect the number of names that reference the current object . When the reference count value of an object is 0, Then its memory will be released immediately .
The following is the case that causes the reference count to increase by one :
Object created , for example a=2
Object is quoted ,b=a
Object as a parameter , Into a function
Object as an element , Stored in a container
The following situation will cause the reference count to decrease by one :
The object alias is displayed del
The object alias is given to the new object
An object leaves its scope
The container in which the object is located is destroyed or the object is deleted from the container
advantage : If efficient 、 The implementation logic is simple 、 Real time , Once the reference count of an object is set to zero , Memory is released directly . You don't have to wait for a specific time like other mechanisms . Randomly assign garbage collection to the running phase , The processing time of reclaiming memory is allocated to normal time , The normal program runs smoothly .
shortcoming :
The logic is simple , But the implementation is a little troublesome . Each object needs to allocate a separate space to count the reference count , This virtually increases the burden of space , And the reference count needs to be maintained , It is easy to make mistakes during maintenance .
In some scenarios , It may be slower . Normally, garbage collection will run smoothly , But when you need to release a large object , Like a dictionary , You need to loop nested calls to all referenced objects , It may take a long time .
Circular reference . This will be fatal to reference counting , Reference counting has no solution to this , Therefore, it must be supplemented by other garbage collection algorithms .
a=[1,2]
b=[2,3]
a.append(b)
b.append(a)
DEL a
DEL b
To be honest, it feels like a deadlock problem , This problem occurs in structures that can be cycled List Dict Object wait , Code above a、b All references between are 1, and a、b The referenced objects are subtracted after deletion 1( So their respective reference counts are still 1), It's embarrassing at this time , All are 1 There is a gold medal of no death ( Has always been a 1 It won't change ). This situation cannot be solved by reference counting alone .
3.3 Mark - What is purge ?
motivation : To solve the problem of circular reference, only container objects will have reference loops , Such as the list 、 Dictionaries 、 class 、 Tuples .
Ideas :
A) Marking stage , Traverse all objects , If it's accessible (reachable), That is, there are objects that reference it , Then mark the object as reachable ;
B) Sweep phase , Traverse the object again , If you find that an object is not marked reachable , Then it will be recycled .
The pointer :
root Linked list (root object)
unreachable Linked list
Situation 1
a=[1,3]
b=[2,4]
a.append(b)
b.append(a)
del a
del b
For scenarios A, It was never implemented again DEL At the time of statement ,a,b All reference counts are 2(init+append=2), But in DEL After execution ,a,b The number of citations subtracts from each other 1.a,b Fall into the circle of circular references , Then mark - Clear the algorithm and start doing things , Find one end a, Start dismantling this a,b Reference ring of ( We from A set out , Because it has a right to B References to , Will B The reference count of minus 1; Then follow the reference to B, because B There is one right A References to , Same will A Reference subtraction of 1, such , This completes the ring removal between circular reference objects .), After removing it, I found ,a,b The circular reference becomes 0, therefore a,b It is handled to unreachable Directly deleted from the linked list .
Situation two
a=[1,3]
b=[2,4]
a.append(b)
b.append(a)
del a
For scenarios B, Take a brief look at that b The reference count after ring removal is also 1, however a Take ring , for 0 了 . This is the time a Has entered unreachable In the list , Has been sentenced to death , But at this point ,root There is... In the list b. If a Be done , There is no justice in the world … , stay root In the list b Will be referenced by reference detection a, If a It was done away with , that b Just … be doomed , The first instance is over , second instance a innocent , So I was dragged to root In the list .
motivation : For programs , There is a certain proportion of memory blocks, the life cycle is relatively short ; And the rest of the memory block , The life cycle will be longer , Even from the beginning of the program to the end of the program . The proportion of short-lived objects is usually in 80%~90% Between , This idea is simply : The longer an object exists , The more likely it's not garbage , The less you should collect . This is executing the tag - Clearing algorithm can effectively reduce the number of traversal objects , So as to improve the speed of garbage collection .
The three generation (generation 0,1,2):
0 Represents the young object ,
1 On behalf of young people ,
2 On behalf of the elderly
According to the weak generation Hypothesis ( The younger the object, the more likely it is to die , Older objects usually survive longer .)
New objects are put into 0 generation , If the object is in the 0 For once gc Survived the garbage collection , Then it is placed in the 1 Inside ( It is upgraded ). If the first 1 The objects in the generation are in the 1 For once gc Survived the garbage collection , It was placed in the 2 Inside .
Four 、python Of sorted Function press... On the dictionary key Sort and press value Sort
4.1 python Of sorted What is a function ?
sorted function
expression :sorted(iterable,key,reverse)
Parameters :
iterable Represents an object that can be iterated , For example, it can be dict.items()、dict.keys() etc. ;
key It's a function , Used to select the elements involved in the comparison ;
reverse It is used to specify whether the sorting is reverse or sequential ,reverse=true In reverse order ,reverse=false Time is sequence , by default reverse=false.
4.2 python Of sorted Function example ?
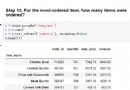
Press key Value to sort the dictionary
[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-b9lCbmq5-1653633156450)(img/ Wechat screenshot _20201104224302.png)]
Use it directly sorted(d.keys()) Can press key Value to sort the dictionary , Here is the sequence of key Value sorted , If you want to sort in reverse order , So long as reverse Set as true that will do .
sorted Function press value Value to sort the dictionary
[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-QhICVrFW-1653633156451)(img/ Wechat screenshot _20201104224402.png)]
d.items() It's actually going to be d Convert to iteratable object , The elements of the iteration object are (‘lilee’,25)、(‘wangyan’,21)、(‘liqun’,32)、(‘lidaming’,19),items() Method to convert dictionary elements into tuples , And here key Parameter corresponding lambda The expression means to select the second element in the tuple as the comparison parameter ( If you write key=lambda item:item[0] The first element is selected as the comparison object , That is to say key Value as the comparison object .lambda x:y in x Represents the output parameter ,y Express lambda The return value of the function ), So this method can be used to value Sort . Note that the sorted return value is a list, The name value pairs in the original dictionary are converted to list Tuples in .
5、 ... and 、 Direct assignment 、 Shallow copy and deep copy
5.1 The concept is introduced
Variable : Is an element of a system table , Have a connection space to the object
object : A piece of allocated memory , Store the values it represents
quote : Is an automatically formed pointer from a variable to an object
type : Belong to the object , Not variables
Immutable object : Once created, immutable objects , Including strings 、 Tuples 、 value type ( The value that the object points to in memory cannot be changed . When you change a variable , Because the value it refers to cannot be changed , It is equivalent to copying the original value and then changing it , This will open up a new address , The variable points to the new address .)
The variable object : Objects that can be modified , Include list 、 Dictionaries 、 aggregate ( The value that the object points to in memory can be changed . Variable ( To be exact, quote ) After change , In fact, the value it refers to changes directly , There was no duplication , There is no new address , Generally speaking, it means to change in place .)
5.2 Introduce
Direct assignment : In fact, it is the of the object quote ( Alias ).
Shallow copy (copy): Copy parent object , Does not copy the inner child of an object .
Deep copy (deepcopy): copy Modular deepcopy Method , It completely copies the parent object and its children .
5.3 Variable definition process
about : a = {1: [1,2,3]}
python Interpreter process :
Create variables a;
Create an object ( Allocate a piece of memory ), To store values {1: [1,2,3]};
Associate variables with objects , Connected by a pointer , The connection from a variable to an object is called a reference ( Variables refer to objects )
5.3 assignment
Introduce :b = a. Assignment reference , Copy only references to new objects , Will not open up new memory space , here a and b They all point to the same object ;
[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-LNnA6MAb-1653633156452)(img/ Wechat screenshot _20210221224625.png)]
5.4 Shallow copy
Introduce :a and b Is a separate object , But their sub objects still point to the unified object ( Is quoted ).
Three forms : eg: lst = [1,2,[3,4]]
Slicing operation :lst1 = lst[:] perhaps lst1 = [each for each in lst]
Factory function :lst1 = list(lst)
copy function :lst1 = copy.copy(lst)
[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-gI46eUXy-1653633156452)(img/ Wechat screenshot _20210221224952.png)]
Shallow replication is discussed in two cases :
1) When the shallow copy value is Immutable object ( character string 、 Tuples 、 value type ) when and “ assignment ” It's the same thing , Object's id value (id() Function to get the memory address of an object ) Same as the original value of shallow copy .
2) When the shallow copy value is The variable object ( list 、 Dictionaries 、 aggregate ) There will be a “ Not so independent objects ” There is . There are two situations :
Case one : There are no complex sub objects in the copied object , The change of the original value does not affect the value of the shallow copy , At the same time, the change of shallow copy value will not affect the original value . Original value id Value is different from light copy original value .
The second case : The copied object has complex sub objects ( For example, a child element in a list is a list ), If you don't change the complex sub objects , The value change of shallow copy will not affect the original value . However, changing the value of complex sub objects in the original value will affect the value of shallow copy .
5.5 Deep copy
Introduce :b = copy.deepcopy(a). a and b It completely copies the parent object and its children , The two are completely independent .
[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-zE2FOao4-1653633156453)(img/ Wechat screenshot _20210221225331.png)]
5.6 The core : Immutable object type and Variable object types
5.6.1 Immutable object type
Introduce : Immutable type , Whether it's a deep copy or a shallow copy , The address value is the same as the copied value
When you add elements to the outer layer , The shallow copy will not change with the original list ; When adding elements to the inner layer , Light copy will change .
No matter how the original list changes , The deep copy remains unchanged .
The assigned object changes with the original list .
For variable object depth copies ( The outer layer changes the element )
import copy
l=[1,2,3,[4, 5]]
l1=l # assignment
l2=copy.copy(l) # Shallow copy
l3=copy.deepcopy(l) # Deep copy
l.append(6)
print(l)
print(l1)
print(l2)
print(l3)
result :
[1, 2, 3, [4, 5], 6] #l Add an element 6
[1, 2, 3, [4, 5], 6] #l1 Then add an element 6
[1, 2, 3, [4, 5]] #l2 remain unchanged
[1, 2, 3, [4, 5]] #l3 remain unchanged
For variable object depth copies ( Inner change elements )
import copy
l=[1,2,3,[4, 5]]
l1=l # assignment
l2=copy.copy(l) # Shallow copy
l3=copy.deepcopy(l) # Deep copy
l[3].append(6)
print(l)
print(l1)
print(l2)
print(l3)
result :
[1, 2, 3, [4, 5, 6]] #l[3] Add an element 6
[1, 2, 3, [4, 5, 6]] #l1 Then add an element 6
[1, 2, 3, [4, 5, 6]] #l2 Then add an element 6
[1, 2, 3, [4, 5]] #l3 remain unchanged
6、 ... and 、 process 、 Threads 、 coroutines
6.1 process
6.1.1 What is a process ?
Introduce : Is a computer program in execution . in other words , When each code is executed , First of all, it is a process itself . Each running process has its own address space 、 Memory 、 Data stack and other resources .
characteristic :
Multiple processes can be in different CPU Up operation , Mutual interference
The same CPU On , Can run multiple processes , Automatically allocate time slices by the operating system
Because the resources between processes cannot be shared , Need interprocess communication , To send data , Receive messages, etc
Multi process , Also known as “ parallel ”.
6.1.2 How processes communicate ?
Processes are isolated from each other , To achieve interprocess communication (IPC),multiprocessing Module supports two forms : Queues and pipes , Both methods use messaging .
Process queue queue: Unlike threads queue, process queue Is generated using multiprocessing Module generated . When generating child processes , The code will be copied to the child process for execution once , And child processes have the same different namespaces as the main process .
The Conduit pipe: The default pipeline is full duplex , If the pipeline is mapped to False, The left side can only be used to receive , The right side can only be used to send , Similar to a one-way street ;
Shared data manage:Queue and pipe It just implements the data interaction , There is no data sharing , That is, one process changes the data of another process .
The process of pool : Multiple processes are opened for concurrency , There are usually several cpu The core just starts several processes , But too many processes will affect the efficiency , This is mainly reflected in the switching overhead , Therefore, the process pool is introduced to limit the number of processes . Maintains a sequence of processes within the process pool , When used , Go to the process pool to get a process , If there are no processes available in the process pool sequence , Then the program will wait , Until a process is available in the process pool .
6.2 Threads
6.2.1 What is thread ?
Introduce : Threads , Is the code executed in the process . Multiple threads can run under one process , These threads share operating system resources requested within the main process . When starting multiple threads in a process , Each thread executes in sequence . In the current operating system , Thread preemption is also supported , That is, other threads waiting to run , You can use priority , Signals, etc , Suspend the running thread , Run it yourself first .
6.2.2 How threads communicate ?
Shared variables : Create global variables , Multiple threads share a global variable , Convenient and simple . But the disadvantage is that shared variables are prone to data competition , Not thread safe , The solution is to use mutexes .
Variable sharing leads to the problem of thread synchronization : If multiple threads modify a data together , Then unexpected results may occur , In order to ensure the correctness of the data , Multiple threads need to be synchronized . Use Thread Object's Lock and Rlock It can realize simple thread synchronization , Both of these objects have acquire Methods and release Method , For data that requires only one thread at a time , It can be operated in acquire and release Between methods .
queue : Threads use queues to communicate , Because all methods of the queue are thread safe , Therefore, threads will not compete for resources .Queue.Queue Is an in-process non blocking queue
6.3 process vs Threads
6.3.1 difference
Each thread in a process shares the same resources as the main process , Compared with independent processes , It is easier to share information and communicate between threads ( All in progress , And shared memory, etc ).
Threads are usually in the form of Concurrent execution , Because of this concurrency and data sharing mechanism , Make multi task collaboration possible .
The process is generally in the form of Parallel execution , This kind of parallelism enables programs to run in multiple at the same time CPU Up operation ;
difference : Multiple threads can only be applied to by the process “ Time slice ” Internal operation ( One CPU The process within , Multiple threads started , Thread scheduler shares the executable time slice of this process ), The process can really realize the “ meanwhile ” function ( Multiple CPU Running at the same time ).
6.3.2 Application scenarios
Compute intensive tasks use multiple processes
IO intensive ( Such as : Network communication ) Tasks use multithreading , Less use of multiple processes . 【IO Operation requires exclusive resources 】
6.4 coroutines
6.4.1 What is a journey ?
Introduce : coroutines , Also called tasklet , fibers , English name Coroutine. The role of the process , yes Executing functions A when , Can interrupt at any time , To execute functions B, Then interrupt to continue executing function A( You can switch freely ). But this is not a function call ( No call statement ), This whole process looks like multithreading , However, there is only one thread in the process .
6.4.2 The advantages of synergy ?
The main features of the cooperative process are : The coordination processes are coordinated , This makes the concurrency count more than tens of thousands , The performance of a coroutine is much higher than that of a thread .【 Note that this is also “ Concurrent ”, No “ parallel ”.】
Advantages of cooperation :
The switching cost of the cooperation process is less , Switching at the program level , The operating system is completely unaware of , So it's more lightweight
Single thread can achieve the effect of concurrency , Make the most of cpu
Disadvantages of the process :
The essence of the process is single thread , Can't use multi-core , Can be a program to open multiple processes , Open multiple threads in each process , Start the process in each thread
A process is a single thread , So once the process is blocked , Will block the entire thread
Use scenarios :
about IO Intensive tasks are ideal for , If it is cpu intensive , Multiple processes are recommended + The way of cooperation .
7、 ... and 、 Global interpreter lock
7.1 What is a global interpreter lock ?
GIL Full name Global Interpreter Lock, Global interpreter lock . Role is , Limit simultaneous execution of multiple threads , Ensure that only one thread is executing at the same time . GIL Not at all Python Characteristics of , It's about achieving Python Parser (CPython) A concept introduced by .
7.2 GIL What's the role ?
In order to make more effective use of the performance of multi-core processor , There are multithreaded programming methods , What comes with this is the consistency of data between threads and the integrity of state synchronization . python To take advantage of multiple cores , Start to support multithreading , But threads are not independent , So threads in the same process are data sharing , When each thread accesses data resources, a race state will appear , That is, data may be occupied by multiple threads at the same time , Data confusion , This is thread insecurity . The simplest way to solve the data integrity and state synchronization between multiple threads is to lock .GIL It can restrict the simultaneous execution of multiple threads , Ensure that only one thread is executing at the same time .
7.3 GIL What's the impact? ?
GIL No doubt it's a global exclusive lock . There is no doubt that the existence of global locks will have a significant impact on the efficiency of multithreading . Even almost equal to Python It's a single threaded program .
7.4 How to avoid GIL The impact ?
Method 1 : Use process + coroutines Instead of Multithreading In multiple processes , Because each process exists independently , So each thread in the process has its own GIL lock , They don't influence each other . however , Because processes exist independently , So the inter process communication needs to be realized through the queue .
Method 2 : Replace the interpreter . image JPython and IronPython Such a parser is due to the characteristics of the implementation language , They don't need to GIL With the help of the . However, due to the use of Java/C# For parser implementation , They also lost access to the community C Opportunities for useful features of language modules . So these parsers are always relatively small .