源代碼:https://gitee.com/shentuzhigang/mini-project/tree/master/brand-crawler
import json
import openpyxl
import requests
allBrandList = []
r = requests.get(
'https://wxapi.appvipshop.com/vips-mobile/rest/shopping/category/index/get_tab/v1?api_key=ce29a51aa5c94a318755b2529dcb8e0b&_xcxid=1648525360552&app_name=shop_weixin_mina&client=wechat_mini_program&source_app=shop_weixin_mina&app_version=4.0&client_type=wap&format=json&mobile_platform=2&ver=2.0&standby_id=native&mobile_channel=nature&mars_cid=1648202533707_3e155b4df020055b73d22e80fb75afa6&warehouse=VIP_SH&fdc_area_id=103103101&province_id=103103&wap_consumer=B&t=1648525360&net=wifi&width=414&height=622&hierarchy_id=107&category_id=&category_filter=&sale_for=&client_from=wxsmall')
json1 = r.json()
data1 = json1['data']['data']['tabs']
for tab in data1:
print(tab['categoryId'])
r2 = requests.get(
'https://wxapi.appvipshop.com/vips-mobile/rest/shopping/category/index/get_tab_data/v1?api_key=ce29a51aa5c94a318755b2529dcb8e0b&_xcxid=1648525360675&app_name=shop_weixin_mina&client=wechat_mini_program&source_app=shop_weixin_mina&app_version=4.0&client_type=wap&format=json&mobile_platform=2&ver=2.0&standby_id=native&mobile_channel=nature&mars_cid=1648202533707_3e155b4df020055b73d22e80fb75afa6&warehouse=VIP_SH&fdc_area_id=103103101&province_id=103103&wap_consumer=B&t=1648525360&net=WIFI&width=750&height=500&pcmpWidth=510&hierarchy_id=107&category_id=' +
tab['categoryId'] + '&sale_for=')
json2 = r2.json()
data2 = json2['data']['data']
sectionList = data2['sectionList']
for section in sectionList:
if section['sectionType'] == 'category' and section['category']['name'] == '精選品牌':
for brand in section['category']['children']:
B = dict(brand)
for b in brand:
if isinstance(brand[b],dict):
B = dict(B,**brand[b])
print(B)
allBrandList.append(B)
f = openpyxl.Workbook()
sheet1 = f.create_sheet('vip')
keys = dict()
i = 1
for jkey in range(len(allBrandList)):
for key, value in allBrandList[jkey].items():
if key in keys:
continue
sheet1.cell(row=1, column=i).value = key
keys[key] = i
i += 1
for jkey in range(len(allBrandList)):
jk = jkey + 2
cT = 0
for key, value in allBrandList[jkey].items():
cT += 1
sheet1.cell(row=jk, column=keys[key]).value = str(value)
f.save('vip.xlsx')
import json
import openpyxl
load_dict = ''
with open("dewu.json", 'r') as load_f:
load_dict = json.load(load_f)
series = load_dict['data']['list']
allBrandList = []
for l in series:
dc = dict()
for d in l:
dc = dict(dc, **l[d])
print(dc)
allBrandList.append(dc)
keys = dict()
i = 1
for jkey in range(len(allBrandList)):
for key, value in allBrandList[jkey].items():
if key in keys:
continue
keys[key] = i
i += 1
f = openpyxl.Workbook()
sheet1 = f.create_sheet('dewu')
for jkey in range(len(allBrandList)):
jk = jkey + 1
cT = 0
for key, value in allBrandList[jkey].items():
cT += 1
if cT == 0:
sheet1.cell(row=jk, column=keys[key]).value = key
else:
sheet1.cell(row=jk, column=keys[key]).value = str(value)
f.save('dewu.xlsx')
平台限制只能取到前10000
Python2
# coding=utf-8
import json
import urllib2
f = open('data.json','w')
listAll = []
for i in range(1,100):
url = "https://api-service.chanmama.com/v2/home/brand/search?page="+ str(i) +"&category=&keyword=&fans_age=&fans_gender=-1&fans_province=&sort=day_volume&order_by=desc&size=100&has_aweme_sale=0&has_live_sale=0&interaction_inc_range=&amount_range="
print url
request = urllib2.Request(url)
# 模仿火狐浏覽器
request.add_header("cookie", "***")
request.add_header("user-agent", "Mozilla/5.0")
response = urllib2.urlopen(request)
code = response.getcode()
content = response.read()
s = json.loads(content)
data = s['data']
list = data['list']
listAll.extend(list)
f.write(json.dumps(listAll))
Python3
# coding=utf-8
import json
import requests
f = open('data.json', 'w')
listAll = []
for i in range(1, 100):
url = "https://api-service.chanmama.com/v2/home/brand/search?page=" + str(
i) + "&category=&keyword=&fans_age=&fans_gender=-1&fans_province=&sort=day_volume&order_by=desc&size=100&has_aweme_sale=0&has_live_sale=0&interaction_inc_range=&amount_range="
print(url)
response = requests.get(url, headers={
"cookie": "***",
# 模仿火狐浏覽器
"user-agent": "Mozilla/5.0"
})
code = response.status_code
content = response.json()
data = content['data']
list = data['list']
listAll.extend(list)
# f.write(json.dumps(listAll))
版本一
import requests
import json
cookie = '***'
headers = {
"cookie": cookie,
# 模仿火狐浏覽器
"user-agent": "Mozilla/5.0"
}
response = requests.get(
'https://h5-shop.aikucun.com/api/commodity/subscribe/v2/queryActivityTagV2/WWDLOwYqYqr?shopBizCode=WWDLOwYqYqr',
headers=headers)
tags = response.json()
tagNos = []
allBrandList = []
for tag in tags['data']:
tagNos.append(tag['activityTagNo'])
for status in range(1, 3):
print('tag:' + tag['activityTagNo'] + ',status:' + str(status))
res = requests.get(
'https://h5-shop.aikucun.com/api/commodity/subscribe/v2/h5/querybrandList?shopBizCode=WWDLOwYqYqr',
params={
'tagNo': tag['activityTagNo'],
'status': status
},
headers=headers)
json1 = res.json()
if 'data' in json1:
data = json1['data']
brandLists = data['brandList']
for brandList in brandLists:
blist = brandList['brandList']
for b in blist:
allBrandList.append(b)
print(dict(b, **b['brandExtend']))
f = open('aikucun.json', 'w', encoding='utf-8')
f.write(json.dumps(allBrandList).encode('utf-8').decode('utf-8'))
版本二
保存到xlsx
解決亂碼問題
import re
import requests
import openpyxl
cookie = ''
headers = {
"cookie": cookie,
# 模仿火狐浏覽器
"user-agent": "Mozilla/5.0"
}
response = requests.get(
'https://h5-shop.aikucun.com/api/commodity/subscribe/v2/queryActivityTagV2/WWDLOwYqYqr?shopBizCode=WWDLOwYqYqr',
headers=headers)
tags = response.json()
tagNos = []
allBrandList = []
for tag in tags['data']:
tagNos.append(tag['activityTagNo'])
for status in range(1, 3):
print('tag:' + tag['activityTagNo'] + ',status:' + str(status))
res = requests.get(
'https://h5-shop.aikucun.com/api/commodity/subscribe/v2/h5/querybrandList?shopBizCode=WWDLOwYqYqr',
params={
'tagNo': tag['activityTagNo'],
'status': status
},
headers=headers)
json1 = res.json()
if 'data' in json1:
data = json1['data']
brandLists = data['brandList']
for brandList in brandLists:
blist = brandList['brandList']
for b in blist:
print(dict(b, **b['brandExtend']))
if 'pcodelen' in b and b['pcodelen'] != '':
str0 = r'u"\u{0}'.format(r'\u'.join(re.findall(r'.{4}', str(b['pcodelen'])))) + '"'
print(str0)
str1 = str(eval(str0))
b['pinpaiming0'] = str1 + str(b['pinpaiming'])[len(str1):]
print(b['pinpaiming0'])
allBrandList.append(b)
print(sorted(dict(b, **b['brandExtend']).items(), key=lambda d: d[0]))
# f = open('aikucun.json', 'w', encoding='utf-8')
# f.write(json.dumps(allBrandList).encode('utf-8').decode('utf-8'))
keys = dict()
i = 1
for jkey in range(len(allBrandList)):
for key, value in allBrandList[jkey].items():
if key in keys:
continue
keys[key] = i
i += 1
f = openpyxl.Workbook()
sheet1 = f.create_sheet('aikucun')
for jkey in range(len(allBrandList)):
jk = jkey + 1
cT = 0
for key, value in allBrandList[jkey].items():
cT += 1
if cT == 0:
sheet1.cell(row=jk, column=keys[key]).value = key
else:
sheet1.cell(row=jk, column=keys[key]).value = str(value)
f.save('aikucun.xlsx')
import requests
import json
headers = {
# 模仿火狐浏覽器
"user-agent": "Mozilla/5.0"
}
allBrandList = []
for i in range(-300, 600):
for ty in [1, 5]:
response = requests.post('https://www.webuy.ai/sesame/hyk/shopCategory/brand/detail',
headers=headers,
json={
"exhibitionParkType": ty,
"categoryId": i,
"shopId": 3572,
"pageSize": 1000,
"pageNo": 1,
"isPageQuery": False
})
print(response.json())
json1 = response.json()
entry = json1['entry']
for b in entry:
print(b)
allBrandList.append(b)
f = open('webuy.json', 'w', encoding='utf-8')
f.write(json.dumps(allBrandList).encode('utf-8').decode('utf-8'))
import requests
from bs4 import BeautifulSoup
import openpyxl
from openpyxl.drawing.image import Image
from PIL import Image as PILImage
from io import BytesIO
from concurrent.futures import ThreadPoolExecutor
import threading
import time
f = openpyxl.Workbook()
sheet1 = f.create_sheet('chinasspp')
headers = ['品牌名稱', '行業類別', '公司名稱', '聯系電話', '公司傳真', '官方網站', '聯系地址', '在線客服']
for index, name in enumerate(headers):
sheet1.cell(row=1, column=index + 1).value = name
count = 1
def parseDetail(no, link):
response = requests.get(link)
response.encoding = "gbk"
soup = BeautifulSoup(response.text, 'lxml')
print('no' + str(no))
for item in soup.select_one("#brand_info_ctl00_blink").select('li'):
key = item.text.split(':')[0]
value = item.text.split(':')[1]
# print(item)
# print(key + ':' + value)
# print(headers.index(key))
sheet1.cell(row=no, column=headers.index(key) + 1).value = value.encode('utf-8').decode('utf-8')
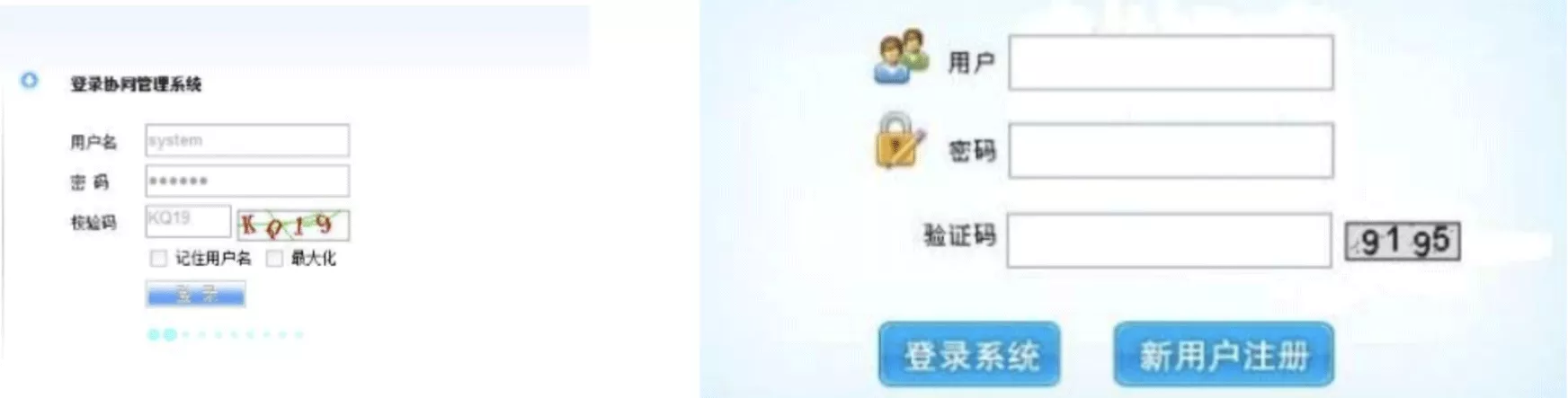
if key == '聯系電話':
url1 = 'http://www.chinasspp.com' + item.select_one('img').attrs.get('src')
img1 = PILImage.open(BytesIO(requests.get(url1).content))
sheet1.add_image(Image(img1), chr(ord("A") + headers.index(key)) + str(no))
if key == '公司傳真':
url2 = 'http://www.chinasspp.com' + item.select_one('img').attrs.get('src')
img2 = PILImage.open(BytesIO(requests.get(url2).content))
sheet1.add_image(Image(img2), chr(ord("A") + headers.index(key)) + str(no))
with ThreadPoolExecutor(max_workers=16) as pool:
for i in range(1, 516):
print('Page ' + str(i))
response = requests.get("http://www.chinasspp.com/brand/%E5%A5%B3%E8%A3%85%E5%93%81%E7%89%8C/" + str(i) + "/")
soup = BeautifulSoup(response.text, 'lxml')
soup.select(".brand")
for brand in soup.select(".brand"):
link = brand.select_one('.logo').attrs.get('href')
count += 1
th = pool.submit(parseDetail, count, link)
pool.shutdown(wait=True)
f.save('chinasspp.xlsx')