from selenium import webdriver
from selenium.common.exceptions import TimeoutException
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from lxml import etree
import re,time
MONGO_URL='localhost'
MONGO_DB='jd_goods'
MONG0_TABLE='jd_goods'
from config import MONGO_DB,MONG0_TABLE,MONGO_URL
from pymongo import MongoClient
client = MongoClient(MONGO_URL)
db=client[MONGO_DB]
def main():
try:
chrome_options=Options()
chrome_options.add_argument("--headless")
browser=webdriver.Chrome(executable_path="C:\Python34\Scripts\chromedriver.exe",chrome_options=chrome_options)
browser = webdriver.Chrome()# Create Google browser objects
wait = WebDriverWait(browser, 10)# Wait for the person
browser.set_window_size(1400, 900)# Set browser page size
total = search()
total = int(re.compile('(\d+)').search(total).group(1))
for i in range(2, total + 1):
next_page(i)
except:
print(" error !")
finally:
browser.close()
if __name__=='__main__':
main()
def search():
try:
jd_url='https://www.jd.com/'
browser.get(jd_url)
input = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR, "#key"))
)# Fixed usage , May refer to selenium Official documents , Get the search input box element
submit=wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR, "#search > div > div.form > button > i")))# Get the submit button element
input.send_keys(" food ")# Fixed usage
submit.click()# Click the finish button
scroll_to_down()# Control the mouse slide , Complete the display of all page data
total = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, "#J_bottomPage > span.p-skip > em:nth-child(1)"))).text# Get the text about the number of pages at the bottom of the page
get_product()# Parse the page and complete the storage to mongodb
return total# return total Text information
except TimeoutError:
return search()# because selenium Timeout errors are often reported , If so, run the function again
def common_click(driver,element_id,sleeptime=2):# The code here is from Baidu online , Complete the page click operation
actions = ActionChains(driver)
actions.move_to_element(element_id)
actions.click(element_id)
actions.perform()
time.sleep(sleeptime)
def scroll_to_down(): # Solve the problem of incomplete data display
browser.execute_script("window.scrollBy(0,3000)")
time.sleep(1)
browser.execute_script("window.scrollBy(0,5000)")
time.sleep(1)
browser.execute_script("window.scrollBy(0,8000)")
time.sleep(1)
def next_page(page_num):
try:
input = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR, "#J_bottomPage > span.p-skip > input"))
)
submit = wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR, "#J_bottomPage > span.p-skip > a"))
)
input.clear()
input.send_keys(page_num)
submit.click()
scroll_to_down()
get_product()
wait.until(EC.text_to_be_present_in_element((By.CSS_SELECTOR,"#J_bottomPage > span.p-num > a.curr"),str(page_num)))# Judge whether the current page is highlighted
except TimeoutError:
return next_page(page_num)
def get_product():
html=browser.page_source# Get the source code of the page
response = etree.HTML(html.lower())# Easy to use xpath Parsing the page
items = response.xpath('//li[@class="gl-item"]')# Get all items of the product
for item in items:
try:
price = item.xpath('.//div[@class="p-price"]//strong//i/text()')[0]
shop = item.xpath('.//div[@class="p-shop"]//a/text()')[0]
src = item.xpath('.//div[@class="p-img"]//a//img/@src')[0]
eva_num = item.xpath('.//div[@class="p-commit"]//strong/a/text()')[0]
title = item.xpath('.//div[@class="p-name p-name-type-2"]//a/@title')[0]
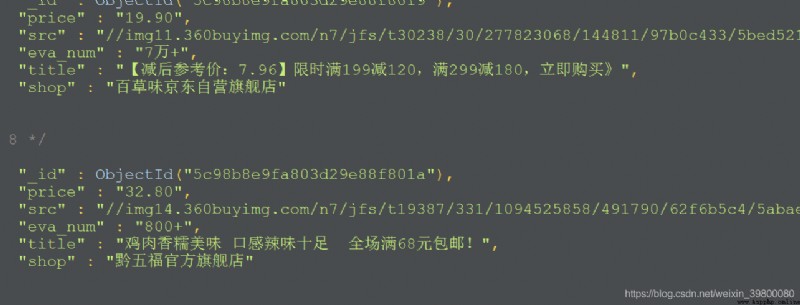
product = {
'title': title,
'src': src,
'price': price,
'eva_num': eva_num,
'shop': shop,
}
# print(product)
save_to_mongo(product)# Save to database
except IndexError: # Because the array may be thrown out of bounds , So you need to feed back exceptions , Avoid code termination
pass
def save_to_mongo(dict):
if db[MONG0_TABLE].insert(dict):
print(' Store in mongdb success ——————————')
return True
return False
windows Next win+r Open the operation interface , Input cmd Enter interface , Input :C:\Users\ child >cd C:\Program Files\MongoDB\Server\3.4\bin
namely mongodb The installation path bin Under the folder , Then input :C:\Program Files\MongoDB\Server\3.4\bin>mongod -dbpath E:\mongodb\data\db
from selenium import webdriver
from selenium.common.exceptions import TimeoutException
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from lxml import etree
import re,time
def search():
try:
jd_url='https://www.jd.com/'
browser.get(jd_url)
input = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR, "#key"))
)# Fixed usage , May refer to selenium Official documents , Get the search input box element
submit=wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR, "#search > div > div.form > button > i")))# Get the submit button element
input.send_keys(" food ")# Fixed usage
submit.click()# Click the finish button
scroll_to_down()# Control the mouse slide , Complete the display of all page data
total = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, "#J_bottomPage > span.p-skip > em:nth-child(1)"))).text# Get the text about the number of pages at the bottom of the page
get_product()# Parse the page and complete the storage to mongodb
return total# return total Text information
except TimeoutError:
return search()# because selenium Timeout errors are often reported , If so, run the function again
def common_click(driver,element_id,sleeptime=2):# The code here is from Baidu online , Complete the page click operation
actions = ActionChains(driver)
actions.move_to_element(element_id)
actions.click(element_id)
actions.perform()
time.sleep(sleeptime)
def scroll_to_down(): # Solve the problem of incomplete data display
browser.execute_script("window.scrollBy(0,3000)")
time.sleep(1)
browser.execute_script("window.scrollBy(0,5000)")
time.sleep(1)
browser.execute_script("window.scrollBy(0,8000)")
time.sleep(1)
def next_page(page_num):
try:
input = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR, "#J_bottomPage > span.p-skip > input"))
)
submit = wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR, "#J_bottomPage > span.p-skip > a"))
)
input.clear()
input.send_keys(page_num)
submit.click()
scroll_to_down()
get_product()
wait.until(EC.text_to_be_present_in_element((By.CSS_SELECTOR,"#J_bottomPage > span.p-num > a.curr"),str(page_num)))# Judge whether the current page is highlighted
except TimeoutError:
return next_page(page_num)
def get_product():
html=browser.page_source# Get the source code of the page
response = etree.HTML(html.lower())# Easy to use xpath Parsing the page
items = response.xpath('//li[@class="gl-item"]')# Get all items of the product
for item in items:
try:
price = item.xpath('.//div[@class="p-price"]//strong//i/text()')[0]
shop = item.xpath('.//div[@class="p-shop"]//a/text()')[0]
src = item.xpath('.//div[@class="p-img"]//a//img/@src')[0]
eva_num = item.xpath('.//div[@class="p-commit"]//strong/a/text()')[0]
title = item.xpath('.//div[@class="p-name p-name-type-2"]//a/@title')[0]
product = {
'title': title,
'src': src,
'price': price,
'eva_num': eva_num,
'shop': shop,
}
# print(product)
save_to_mongo(product)# Save to database
except IndexError: # Because the array may be thrown out of bounds , So you need to feed back exceptions , Avoid code termination
pass
def save_to_mongo(dict):
if db[MONG0_TABLE].insert(dict):
print(' Store in mongdb success ——————————')
return True
return False
def main():
try:
chrome_options=Options()# Browser operation
chrome_options.add_argument("--headless")# Set up headless browser
browser=webdriver.Chrome(executable_path="C:\Python34\Scripts\chromedriver.exe",chrome_options=chrome_options) # Pass parameters
browser = webdriver.Chrome()# Create Google browser objects
wait = WebDriverWait(browser, 10)# Wait for the person
browser.set_window_size(1400, 900)# Set browser page size
total = search()
total = int(re.compile('(\d+)').search(total).group(1))
for i in range(2, total + 1):
next_page(i)
except:
print(" error !")
finally:
browser.close()
if __name__=='__main__':
main()
You can see that the database name is jd_goods Here is a data table with the same name