完整項目下載鏈接:代碼及相關材料下載
基於python和cv2、pytorch實現的車牌定位、字符分割、字符識別項目 車牌的檢測和識別的應用非常廣泛,比如交通違章車牌追蹤,小區或地下車庫門禁。在對車牌識別和檢測的過程中,因為車牌往往是規整的矩形,長寬比相對固定,色調紋理相對固定,常用的方法有:基於形狀、基於色調、基於紋理、基於文字特征等方法,近年來隨著深度學習的發展也會使用目標檢測的一些深度學習方法。
車牌的檢測和識別的應用非常廣泛,比如交通違章車牌追蹤,小區或地下車庫門禁。在對車牌識別和檢測的過程中,因為車牌往往是規整的矩形,長寬比相對固定,色調紋理相對固定,常用的方法有:基於形狀、基於色調、基於紋理、基於文字特征等方法,近年來隨著深度學習的發展也會使用目標檢測的一些深度學習方法。

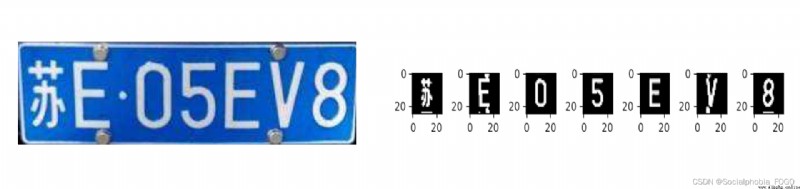
源碼和數據位於 src 文件夾中,src 文件夾中各個子文件功能如下:
characterData:內含有所有簡體中文車牌包含的字符圖片數據集(包括省份漢字、字母、數字)
singledigit:(請自己創建該空文件夾),用於存儲提取出的單個字符圖片
Car.jpg:示例圖片,可以用來測試模型識別效果
getplate.py:車牌定位、字符分割源碼
main.py:模型訓練,字符識別源碼
clone 到本地
在 src 文件夾下添加空文件夾,名為 singledigit
先運行 getplate.py
再運行 main.py,控制台輸出結果
import matplotlib.pyplot as plt
import numpy as np
import torch
import cv2
import os
def find_card(I):
# 識別出車牌區域並返回該區域的圖像
[y, x, z] = I.shape
# y取值范圍分析
Blue_y = np.zeros((y, 1))
for i in range(y):
for j in range(x):
# 藍色rgb范圍
temp = I[i, j, :]
if (I[i, j, 2] <= 30) and (I[i, j, 0] >= 119):
Blue_y[i][0] += 1
MaxY = np.argmax(Blue_y)
PY1 = MaxY
while (Blue_y[PY1, 0] >= 5) and (PY1 > 0):
PY1 -= 1
PY2 = MaxY
while (Blue_y[PY2, 0] >= 5) and (PY2 < y - 1):
PY2 += 1
# x取值
Blue_x = np.zeros((1, x))
for i in range(x):
for j in range(PY1, PY2):
if (I[j, i, 2] <= 30) and (I[j, i, 0] >= 119):
Blue_x[0][i] += 1
PX1 = 0
while (Blue_x[0, PX1] < 3) and (PX1 < x - 1):
PX1 += 1
PX2 = x - 1
while (Blue_x[0, PX2] < 3) and (PX2 > PX1):
PX2 -= 1
# 對車牌區域的修正
PX1 -= 2
PX2 += 2
return I[PY1:PY2, PX1 - 2: PX2, :]
def divide(I):
[y, x, z] = I.shape
White_x = np.zeros((x, 1))
for i in range(x):
for j in range(y):
if I[j, i, 1] > 176:
White_x[i][0] += 1
return White_x
def divide_each_character(I):
[y, x, z] = I.shape
White_x = np.zeros((x, 1))
for i in range(x):
for j in range(y):
if I[j, i, 1] > 176:
White_x[i][0] += 1
res = []
length = 0
for i in range(White_x.shape[0]):
# 使用超參數經驗分割
t = I.shape[1] / 297
num = White_x[i]
if num > 8:
length += 1
elif length > 20 * t:
res.append([i - length - 2, i + 2])
length = 0
else:
length = 0
return res
if __name__ == '__main__':
I = cv2.imread('Car.jpg')
Plate = find_card(I)
# White_x = divide(Plate)
plt.imshow(Plate)
plt.show()
# plt.plot(np.arange(Plate.shape[1]), White_x)
res = divide_each_character(Plate)
plate_save_path = './singledigit/'
for t in range(len(res)):
plt.subplot(1, 7, t + 1)
temp = res[t]
save_img = cv2.cvtColor(Plate[:, temp[0]:temp[1], :],cv2.COLOR_BGR2GRAY)
ma = max(save_img.shape[0], save_img.shape[1])
mi = min(save_img.shape[0], save_img.shape[1])
ans = np.zeros(shape=(ma, ma, 3),dtype=np.uint8)
start =int(ma/2-mi/2)
for i in range(mi):
for j in range(ma):
if save_img[j,i] > 125:
for k in range(3):
ans[j,start+i,k]=255
ans=cv2.merge([ans[:,:,0],ans[:,:,1],ans[:,:,2]])
ans=cv2.resize(ans,(25,25))
dir_name=plate_save_path+str(t)
os.mkdir(dir_name)
cv2.imwrite(dir_name+'/'+str(t)+'.jpg',ans)
plt.imshow(ans)
plt.show()
from torchvision.datasets import ImageFolder
from torchvision import transforms
from torch.utils.data import DataLoader,SubsetRandomSampler
from torch import nn, optim
import numpy as np
import torch
import time
import sys
import cv2
import os
# 車牌字符數組
match = {
0: '0', 1: '1', 2: '2', 3: '3', 4: '4', 5: '5', 6: '6', 7: '7', 8: '8', 9: '9', 10: 'A', 11: 'B', 12: 'C',13: '川', 14: 'D', 15: 'E', 16: '鄂',17: 'F', 18: 'G', 19: '贛', 20: '甘', 21: '貴', 22: '桂', 23: 'H', 24: '黑', 25: '滬', 26: 'J', 27: '冀', 28: '津',29: '京', 30: '吉', 31: 'K', 32: 'L', 33: '遼',34: '魯', 35: 'M', 36: '蒙', 37: '閩', 38: 'N', 39: '寧', 40: 'P', 41: 'Q', 42: '青', 43: '瓊', 44: 'R', 45: 'S',46: '陝', 47: '蘇', 48: '晉', 49: 'T', 50: 'U',51: 'V', 52: 'W ', 53: '皖', 54: 'X', 55: '湘', 56: '新', 57: 'Y', 58: '豫', 59: '渝', 60: '粵', 61: '雲', 62: 'Z',63: '藏', 64: '浙'}
data_path = './characterData/data'
data_transform=transforms.Compose([
transforms.Grayscale(),
transforms.ToTensor()
])
dataset=ImageFolder(data_path,transform=data_transform)
validation_split=.1
shuffle_dataset = True
random_seed= 42
batch_size=100
dataset_size = len(dataset)
indices = list(range(dataset_size))
split = int(np.floor(validation_split * dataset_size))
if shuffle_dataset :
np.random.seed(random_seed)
np.random.shuffle(indices)
train_indices, val_indices = indices[split:], indices[:split]
train_sampler = SubsetRandomSampler(train_indices)
test_sampler = SubsetRandomSampler(val_indices)
train_iter = DataLoader(dataset, batch_size=batch_size,
sampler=train_sampler)
test_iter = DataLoader(dataset, batch_size=batch_size,
sampler=test_sampler)
# lenet訓練
sys.path.append("..")
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
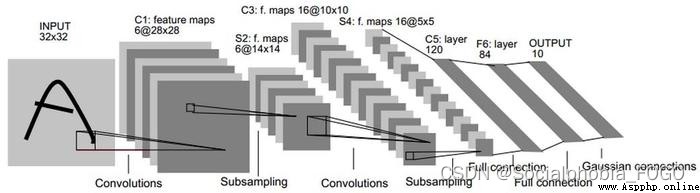
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(1, 6, 5), # in_channels, out_channels, kernel_size
nn.Sigmoid(),
nn.MaxPool2d(2, 2), # kernel_size, stride
nn.Conv2d(6, 16, 5),
nn.Sigmoid(),
nn.MaxPool2d(2, 2)
)
self.fc = nn.Sequential(
nn.Linear(16*4, 120),
nn.Sigmoid(),
nn.Linear(120, 84),
nn.Sigmoid(),
nn.Linear(84, 65)
)
def forward(self, img):
feature = self.conv(img)
output = self.fc(feature.view(img.shape[0], -1))
return output
def evaluate_accuracy(data_iter, net, device=None):
if device is None and isinstance(net, torch.nn.Module):
# 如果沒指定device就使用net的device
device = list(net.parameters())[0].device
acc_sum, n = 0.0, 0
with torch.no_grad():
for X, y in data_iter:
if isinstance(net, torch.nn.Module):
net.eval() # 評估模式, 這會關閉dropout
acc_sum += (net(X.to(device)).argmax(dim=1) == y.to(device)).float().sum().cpu().item()
net.train() # 改回訓練模式
else: # 自定義的模型, 3.13節之後不會用到, 不考慮GPU
if('is_training' in net.__code__.co_varnames): # 如果有is_training這個參數
# 將is_training設置成False
acc_sum += (net(X, is_training=False).argmax(dim=1) == y).float().sum().item()
else:
acc_sum += (net(X).argmax(dim=1) == y).float().sum().item()
n += y.shape[0]
return acc_sum / n
def predict(img,net,device=None):
if device is None and isinstance(net, torch.nn.Module):
# 如果沒指定device就使用net的device
device = list(net.parameters())[0].device
res=''
with torch.no_grad():
for X,y in img:
if isinstance(net, torch.nn.Module):
net.eval() # 評估模式, 這會關閉dropout
temp=net(X.to(device)).argmax(dim=1)
x=np.array(X)
temp=np.array(temp).tolist()
for i in temp:
res+=str(match[i])
net.train() # 改回訓練模式
return res
# 本函數已保存在d2lzh_pytorch包中方便以後使用
def train_ch5(net, train_iter, test_iter, batch_size, optimizer, device, num_epochs):
net = net.to(device)
print("training on ", device)
loss = torch.nn.CrossEntropyLoss()
for epoch in range(num_epochs):
train_l_sum, train_acc_sum, n, batch_count, start = 0.0, 0.0, 0, 0, time.time()
for X, y in train_iter:
x=np.array(X)
Y=np.array(y)
X = X.to(device)
y = y.to(device)
y_hat = net(X)
l = loss(y_hat, y)
optimizer.zero_grad()
l.backward()
optimizer.step()
train_l_sum += l.cpu().item()
train_acc_sum += (y_hat.argmax(dim=1) == y).sum().cpu().item()
n += y.shape[0]
batch_count += 1
test_acc = evaluate_accuracy(test_iter, net)
print('epoch %d, loss %.4f, train acc %.3f, test acc %.3f, time %.1f sec'
% (epoch + 1, train_l_sum / batch_count, train_acc_sum / n, test_acc, time.time() - start))
net = LeNet()
print(net)
lr, num_epochs = 0.001, 40
batch_size=256
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
checkpoint_save_path = "./LeNet5.pth"
if os.path.exists(checkpoint_save_path ):
print('load the model')
net.load_state_dict(torch.load(checkpoint_save_path))
else:
train_ch5(net, train_iter, test_iter, batch_size, optimizer, device, num_epochs)
torch.save(net.state_dict(),checkpoint_save_path)
# 識別車牌內容
# plate_paths=os.listdir('./singledigit')
# ans=''
# for plate in plate_paths:
# #ans+=predict(cv2.imread(plate),net)
# img=cv2.imread('./singledigit/'+plate)
# img2=np.zeros(shape=(3,20,20),dtype=torch.float32)
#
# a=net(torch.from_numpy(img))
# print(ans)
pre_path = './singledigit'
pre_transform=transforms.Compose([
transforms.Grayscale(),
transforms.CenterCrop(size=(20,20)),
transforms.ToTensor()
])
preset=ImageFolder(pre_path,transform=pre_transform)
pre_iter = DataLoader(preset)
ans=predict(pre_iter,net)
print(ans)
runfile('E:/大數據分析方法/workspace/week1/數字圖像處理/test05.py', wdir='E:/大數據分析方法/workspace/week1/數字圖像處理')
LeNet(
(conv): Sequential(
(0): Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1))
(1): Sigmoid()
(2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(3): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))
(4): Sigmoid()
(5): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(fc): Sequential(
(0): Linear(in_features=64, out_features=120, bias=True)
(1): Sigmoid()
(2): Linear(in_features=120, out_features=84, bias=True)
(3): Sigmoid()
(4): Linear(in_features=84, out_features=65, bias=True)
)
)
training on cpu
epoch 1, loss 3.7474, train acc 0.069, test acc 0.074, time 75.7 sec
epoch 2, loss 3.7088, train acc 0.071, test acc 0.074, time 7.4 sec
epoch 3, loss 3.3383, train acc 0.194, test acc 0.358, time 7.2 sec
epoch 4, loss 2.4473, train acc 0.420, test acc 0.473, time 7.0 sec
epoch 5, loss 1.9042, train acc 0.488, test acc 0.565, time 7.0 sec
epoch 6, loss 1.5477, train acc 0.583, test acc 0.639, time 7.1 sec
epoch 7, loss 1.3139, train acc 0.656, test acc 0.698, time 6.8 sec
epoch 8, loss 1.1450, train acc 0.705, test acc 0.737, time 8.0 sec
epoch 9, loss 1.0151, train acc 0.743, test acc 0.770, time 7.6 sec
epoch 10, loss 0.9199, train acc 0.769, test acc 0.788, time 7.2 sec
epoch 11, loss 0.8415, train acc 0.789, test acc 0.804, time 7.2 sec
epoch 12, loss 0.7789, train acc 0.804, test acc 0.817, time 7.4 sec
epoch 13, loss 0.7240, train acc 0.817, test acc 0.830, time 7.4 sec
epoch 14, loss 0.6803, train acc 0.825, test acc 0.834, time 7.2 sec
epoch 15, loss 0.6408, train acc 0.833, test acc 0.838, time 7.2 sec
epoch 16, loss 0.6064, train acc 0.838, test acc 0.845, time 7.5 sec
epoch 17, loss 0.5785, train acc 0.842, test acc 0.854, time 7.3 sec
epoch 18, loss 0.5502, train acc 0.850, test acc 0.856, time 7.4 sec
epoch 19, loss 0.5278, train acc 0.855, test acc 0.857, time 7.3 sec
epoch 20, loss 0.5028, train acc 0.860, test acc 0.875, time 7.2 sec
epoch 21, loss 0.4820, train acc 0.867, test acc 0.877, time 7.3 sec
epoch 22, loss 0.4622, train acc 0.872, test acc 0.883, time 7.4 sec
epoch 23, loss 0.4424, train acc 0.877, test acc 0.885, time 7.4 sec
epoch 24, loss 0.4264, train acc 0.882, test acc 0.881, time 7.5 sec
epoch 25, loss 0.4106, train acc 0.885, test acc 0.890, time 7.3 sec
epoch 26, loss 0.3957, train acc 0.888, test acc 0.893, time 7.3 sec
epoch 27, loss 0.3803, train acc 0.894, test acc 0.900, time 8.3 sec
epoch 28, loss 0.3695, train acc 0.897, test acc 0.900, time 8.3 sec
epoch 29, loss 0.3538, train acc 0.903, test acc 0.903, time 7.9 sec
epoch 30, loss 0.3421, train acc 0.906, test acc 0.907, time 8.1 sec
預測結果為:蘇E05EV8
1、車牌定位僅使用了顏色特征
2、車牌分割僅使用了 x 軸投影波峰波谷
3、卷積神經網絡准確率有待提高
 Python pycharm in version 3.8 is also the lxml successfully installed in the new version, but the etree object has no attribute HTML
Python pycharm in version 3.8 is also the lxml successfully installed in the new version, but the etree object has no attribute HTML
Take the answer : The code of