This article has participated in 「 New people's creation ceremony 」 Activities , Start the road of nuggets creation together .
Create a bayes.py Program , Building word vectors from text , Realize the conversion function from thesaurus to vector .
def loadDataSet():
postingList = [['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'], # Participle available wordcloud
['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'],# This document is a message board for spotted dog lovers
['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'],
['stop', 'posting', 'stupid', 'worthless', 'garbage'],
['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'],
['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']]
classVec = [0,1,0,1,0,1]#1 For insulting words ,0 For normal speech
return postingList,classVec # The second variable returned is a manual tag used to distinguish insulting and non insulting tags .
# Create an empty set
def createVocabList(dataSet):
vocabSet = set([])
for document in dataSet:
vocabSet = vocabSet | set(document) # Create a union of two sets Cross out repeated words
return list(vocabSet)
# Process the sample output in vector form
def setOfWords2Vec(vocaList , inputSet):
returnVec = [0]*len(vocaList)# Create a file in which all elements are 0 Instead of text
for word in inputSet:
if word in vocaList:
returnVec[vocaList.index(word)] = 1
else:
print("the word:%s is not in my Vocabulary!"" % word")
return returnVec
The first function creates some experimental samples , The second function creates a non repeating list of all documents that appear , The third function input parameter is the vocabulary and a document , The output is the document vector , Each element of a vector is 1 or 0, Indicates whether the words in the vocabulary appear in the input document .
Can check whether the function is working properly :
myVocabList=createVocabList(listOPosts)
print(myVocabList)
print(setOfWords2Vec(myVocabList,listOPosts[0]))
print(setOfWords2Vec(myVocabList,listOPosts[3]))

The pseudo code for this function is as follows :
 According to the basic theory of the former part, we first get P(w|ci), Calculate again P(ci).
According to the basic theory of the former part, we first get P(w|ci), Calculate again P(ci).
Naive Bayes Classifier training function :
numTrainDocs = len(trainMatrix)# Text matrix
numWords = len(trainMatrix[0])
pAbusive = sum(trainCategory)/float(numWords)
p0Num = zeros(numWords);p1Num = zeros(numWords)# Create two lists of the same length as the entry vector , Smoothing : The initial value is set to 1
p0Denom = 0.000001;p1Denom = 0.000001
for i in range (numTrainDocs):
if trainCategory[i] ==1:
p1Num += trainMatrix[i]
p1Denom += sum(trainMatrix[i])
else:
p0Num += trainMatrix[i]
p0Denom += sum(trainMatrix[i])
p1Vect = p1Num/p1Denom # utilize Numpy Array calculation p(wi/c1), Namely class 1 The probability of the occurrence of each entry under the condition
p0Vect = p0Num/p0Denom # utilize Numpy Array calculation p(wi/c0), To avoid underflow , It will be changed to log()
return p0Vect, p1Vect, pAbusive # return
Because when p0Num It will be reported in time RuntimeWarning: invalid value encountered in true_divide, This is from 0/0 Lead to , So it's setting p0Denom Cannot be set to 0.
First , Calculation documents are insulting documents (class=1) Probability , namely P(1).P(0) May by 1-P(1) obtain .
test :
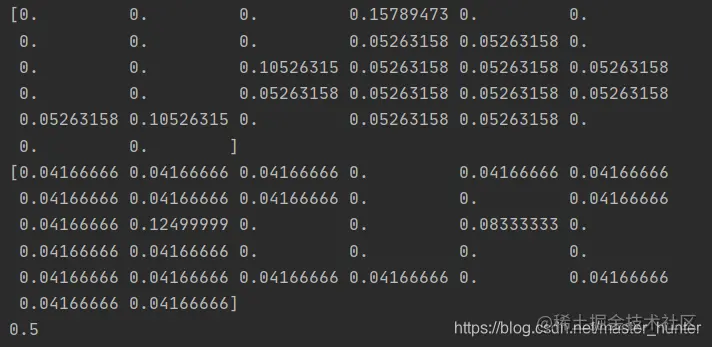 Using Bayes classifier When classifying documents , To multiply multiple probabilities, we can get the probability that the document belongs to a certain category , Computation p(w0|1)p(w1|1)p(w2|1). One of the probabilities is 0, So the final product is also 0. We can initialize the initial values of all the words that appear as 1, And initialize the denominator to 2. modify :
Using Bayes classifier When classifying documents , To multiply multiple probabilities, we can get the probability that the document belongs to a certain category , Computation p(w0|1)p(w1|1)p(w2|1). One of the probabilities is 0, So the final product is also 0. We can initialize the initial values of all the words that appear as 1, And initialize the denominator to 2. modify :
p0Denom = 2.0;p1Denom = 2.0# Smoothing , The initial value is set to 2
Another problem is underflow , This is due to the multiplication of too many very small numbers . When you calculate the product p(w0|ci) * p(w1|ci) * p(w2|ci)... p(wn|ci) when , Because most of the factors are very small , So the program will overflow or get incorrect answers .( use Python Try to multiply many very small numbers , The final round will give you 0). One solution is to take the natural logarithm of the product . In algebra there is ln(a * b) = ln(a) + ln(b), So by logarithms, you can avoid errors caused by underflow or rounding floating-point numbers . meanwhile , There is no loss in the treatment of natural logarithm .
p0Vect = log(p0Num/p0Denom)# utilize Numpy Array calculation p(wi/c0), To avoid underflow , It will be changed to log()
Naive Bayesian classification function :
def classifyNB(vec2Classify,p0Vec,p1Vec,pClass1):# Pay attention to the parameters 2,3 All have log turn
p1 = sum(vec2Classify * p1Vec) + log(pClass1)# P(w|c1) * P(c1) , That's the molecules of Bayesian criteria
p0 = sum(vec2Classify * p0Vec) + log(1.0 - pClass1) # P(w|c0) * P(c0) , That's the molecules of Bayesian criteria
if p1 > p0:
return 1
else:
return 0
"""
Usage algorithm :
# Convert multiplication to addition
Multiplication :P(C|F1F2...Fn) = P(F1F2...Fn|C)P(C)/P(F1F2...Fn)
Add :P(F1|C)*P(F2|C)....P(Fn|C)P(C) -> log(P(F1|C))+log(P(F2|C))+....+log(P(Fn|C))+log(P(C))
:param vec2Classify: Data to be tested [0,1,1,1,1...], That's the vector to classify
:param p0Vec: Category 0, That is, normal documents [log(P(F1|C0)),log(P(F2|C0)),log(P(F3|C0)),log(P(F4|C0)),log(P(F5|C0))....] list
:param p1Vec: Category 1, That's insulting documents [log(P(F1|C1)),log(P(F2|C1)),log(P(F3|C1)),log(P(F4|C1)),log(P(F5|C1))....] list
:param pClass1: Category 1, The probability of the appearance of insulting documents
:return: Category 1 or 0
"""
# Calculation formula log(P(F1|C))+log(P(F2|C))+....+log(P(Fn|C))+log(P(C))
test :
"""
Test naive Bayes algorithm
"""
# 1. Load data set
listPosts,listClasses =loadDataSet()
#2. Create a word set
myVocabList = createVocabList(listPosts)
#3. Calculate whether words appear and create a data matrix
trainMat = []
for postinDoc in listPosts:
trainMat.append(setOfWords2Vec(myVocabList,postinDoc))
#4. Training data
p0V,p1V,pAb = trainNB0(array(trainMat),array(listClasses))
#5. Test data
testEntry = ['love','my','dalmation']
thisDoc = array(setOfWords2Vec(myVocabList,testEntry))
print(testEntry, 'classified as: ', classifyNB(thisDoc, p0V, p1V, pAb))
testEntry = ['stupid', 'garbage']
thisDoc = array(setOfWords2Vec(myVocabList, testEntry))
print(testEntry, 'classified as: ', classifyNB(thisDoc, p0V, p1V, pAb))

Because we take the appearance of each word as a feature , This can be described as a word set model . But words often have multiple meanings , It means that a word that appears in a document may have a different meaning . This method is called the bag of words model .
In the bag of words , Each word can appear more than once , And in the word set , Each word can only appear once . In order to adapt to the bag model , You need to do this for functions setOfWords2Vec With a little modification :
returnVec = [0]*len(vocaList)# Create a file in which all elements are 0 Instead of text
for word in inputSet:
if word in vocaList:
returnVec[vocaList.index(word)] += 1 # Every time I meet a word , Add one accordingly
else:
print("the word:%s is not in my Vocabulary!"" % word")
return returnVec

Using naive Bayes to filter spam data sets
Data set description : There are two folders under the dataset , among spam Under the folder is spam ,ham Folder for non spam .
Dataset format : txt file
English because there are spaces between words , Easy to cut . Chinese has jieba library , Those who are interested can learn about it .
myStr.split()
['This', 'book', 'is', 'the', 'best', 'book', 'on', 'Python.']
But the last word has punctuation , We solve this problem through regular expressions , Regular expression plays an important role in text classification .
regEx = re.compile('\\W*')
listOfTokens = regEx.split(myStr)
listOfTokens
['This', 'book', 'is', 'the', 'best', 'book', 'on', 'Python', '']
 There will be an empty string generated here . We can calculate the length of a string , Only return string length greater than 0 String .
There will be an empty string generated here . We can calculate the length of a string , Only return string length greater than 0 String .
['This', 'book', 'is', 'the', 'best', 'book', 'on', 'Python']
In addition, we consider building a Thesaurus , Don't think about the case of words , All in lowercase
['this', 'book', 'is', 'the', 'best', 'book', 'on', 'python']
In this way, we have completed the simple text segmentation . Of course, some texts have very complicated processing methods , It depends on the content and nature of the text .
import re
listOfTokens = re.split(r'\W*', bigString)
return [tok.lower() for tok in listOfTokens if len(tok) > 2]
def spamTest():
docList = [] # file ( mail ) matrix
classList = [] # Class tag list
for i in range(1, 26):
wordlist = textParse(open('trashclass/spam/{}.txt'.format(str(i))).read())
docList.append(wordlist)
classList.append(1)
wordlist = textParse(open('trashclass/ham/{}.txt'.format(str(i))).read())
docList.append(wordlist)
classList.append(0)
vocabList = bayes.createVocabList(docList) # Vocabulary for all email content
import pickle
file=open('trashclass/vocabList.txt',mode='wb') # Store glossary Binary writing
pickle.dump(vocabList,file)
file.close()
# For emails that need to be tested , According to its vocabulary fileWordList Construct vectors
# Build randomly 40 Training set and 10 Test set
trainingSet = list(range(50))
testSet = []
for i in range(10):
randIndex = int(np.random.uniform(0, len(trainingSet)))
testSet.append(trainingSet[randIndex])
del (trainingSet[randIndex])
trainMat = [] # Training set
trainClasses = [] # List of class tags of vectors in training set
for docIndex in trainingSet:
# The training set is composed of vectors constructed by bag pattern
trainMat.append(bayes.setOfWords2Vec(vocabList, docList[docIndex]))
trainClasses.append(classList[docIndex])
p0v,p1v,pAb=bayes.trainNB0(trainMat,trainClasses)
file=open('trashclass/threeRate.txt',mode='wb') # To store the three probabilities of the classifier Binary writing
pickle.dump([p0v,p1v,pAb],file)
file.close()
errorCount=0
for docIndex in testSet:
wordVector=bayes.setOfWords2Vec(vocabList,docList[docIndex])
if bayes.classifyNB(wordVector,p0v,p1v,pAb)!=classList[docIndex]:
errorCount+=1
return float(errorCount)/len(testSet)
Add serialization to permanently save objects , Save the byte sequence of the object to the local file . In this case, there are 50 email , among 10 Emails were randomly selected as the test set . The document corresponding to the selected number is added to the test set , It's also removed from the training set . This randomly selects part of the data as a training set , The process of remaining parts as test sets is called retained cross validation . Now we only make one iteration , In order to estimate the error rate of classifier more accurately , We should work out the average error rate after many iterations .
Of course you can use it :
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=0.2,
random_state=0)
There are many ways to do it. It's very simple , There is no repetition here .
( By the way, the code above setOfWords2Vec It's actually bagOfWords2VecMN, I just didn't change my name , The content is bagOfWords2VecMN)
Start building classifiers :
import numpy as np
import tkinter as tk
from tkinter import filedialog
def fileClassify(filepath):
import pickle
fileWordList=textParse(open(filepath,mode='r').read())
file=open('trashclass/vocabList.txt',mode='rb')
vocabList=pickle.load(file)
vocabList=vocabList
fileWordVec=bayes.setOfWords2Vec(vocabList,fileWordList) # The vector of the document to be judged
file=open('trashclass/threeRate.txt',mode='rb')
rate=pickle.load(file)
p0v=rate[0];p1v=rate[1];pAb=rate[2]
return bayes.classifyNB(fileWordVec,p0v,p1v,pAb)
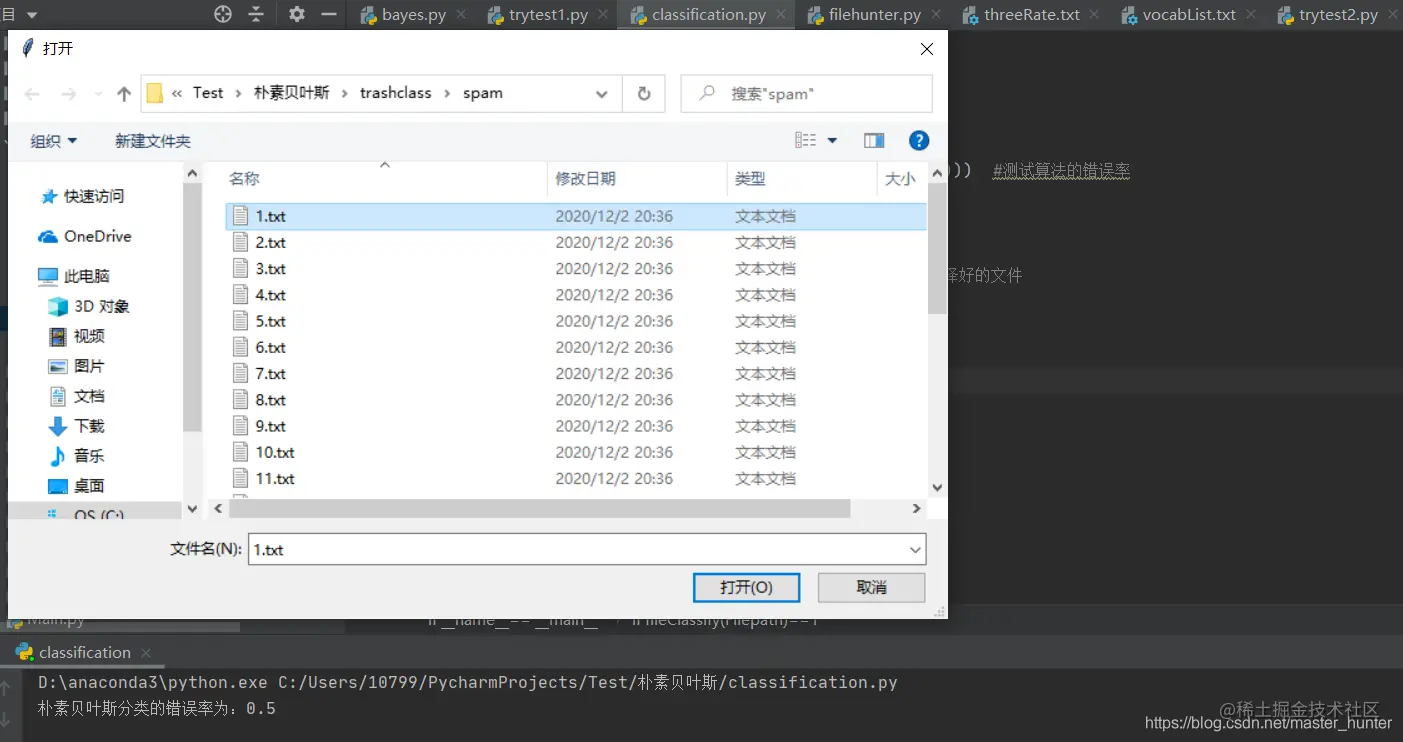
if __name__=='__main__':
print(' The error rate of naive Bayes classification is :{}'.format(spamTest())) # Test the error rate of the algorithm
# filepath=input(' Enter the email path to be judged ')
root = tk.Tk()
root.withdraw()
Filepath = filedialog.askopenfilename() # Get the selected file
print(Filepath)
# Judge whether the mail under a certain path is spam
if fileClassify(Filepath)==1:
print(' spam ')
else:
print(' non-spam ')
I use... Directly here Tk I'm too lazy to take a direct route QWQ

That's what this issue is all about . I am a fanstuck , If you have any questions, please leave a message for discussion , See you next time .






