Recently in use python When receiving network data , There is always a coding problem when outputting , It's all settled , But deeply realize that you are right python There is no clear understanding of the coding of , That's why I met such a problem . To sum up today , So as not to have long dreams in the future .
First , Let's talk about character coding . Let's first look at how computers represent numbers , Computers use binary ( Why? ?), The first computers were designed with 8 A bit (bit) As a byte (byte), therefore , The number of digits a byte can represent is 256 individual , such as 0~255( Binary system 11111111 = Decimal system 255), To represent a larger number , You have to use more bytes . in other words , In fact, the final existence of numbers in the computer is logical 0 and 1 The combination of , Different storage media have different physical performance , For example, in the disk, the magnetic representation of each magnetic unit is bit information . The representation of numbers is like this , What about the characters ? The reason why we have a more intuitive understanding of digital storage as binary , Because the concept of binary had existed long before the advent of computers , This is a mathematical concept , However, it is relatively simple for us to convert decimal numbers into binary numbers . But when it comes to characters , We don't know how to do it . It's also very simple , Since computers can store numbers , That must be able to save characters , As long as we match the characters with the numbers , This requires a set of unified rules to correspond to , So that users can reach a consensus .
The computer was invented by the Americans , So the earliest character encoding is also what they stipulated , Only 127 Characters are encoded into the computer , It can be used to represent some letters 、 Numbers and other symbols , This is it. ASCII code .
At that time , That's enough . But if you want to deal with Chinese , This is obviously not enough , So China has formulated GB2312 code . Empathy , Other countries also have codes from other countries , Because different languages are used . It's easy to think , There will be a problem , When there are multiple languages in a text , How to code ?
therefore ,Unicode To solve this problem , Unify all languages into one code , So there won't be a problem . Unicode Most of the characters in are represented by two bytes ( Except for some rare characters ), Modern operating systems and most programming languages directly support Unicode.
such as in The word is ascii The corresponding code cannot be found in , And in the unicode The corresponding decimal number in is 20013, Expressed in binary is 01001110 00101101.
Obviously ,unicode Than ascii It takes up more space , If the text is in Chinese or mixed with other non English languages , It's inevitable , After all, you have to encode more characters , You have to use more space . But if the text is in English , use unicode Storage will be better than ascii Double the space , This is obviously what you don't want to see . Some people may think that you can use Huffman code , The length of each character is determined according to the frequency of the character , This is also a way , But there are so many characters in the world , How to make statistics ? Which texts are used as the basis for Statistics ? And the frequency of characters used in different regions is also different . But to solve this problem , A new coding method has been proposed , That's it utf-8, This coding adopts a more flexible variable length method , Put one Unicode Characters are encoded into... According to different number sizes 1-6 Bytes make the original ascii Encode characters that can be represented , Still proceed according to the original coding , Chinese characters are usually 3 Bytes , Only rare characters are encoded as 4-6 Bytes . Take a chestnut :
character
ASCII
Unicode
UTF-8
A
01000001
00000000 01000001
01000001
in
x
01001110 00101101
11100100 10111000 10101101
There's another advantage to this , Namely utf-8 The encoding is compatible with previous use ascii Encoded text , Solve some problems left over by history .
Now the common character coding mode of computer system : In computer memory , Unified use Unicode code , When you need to save to a hard disk or need to transfer , Just switch to UTF-8 code . When browsing the web , The server will dynamically generate Unicode Content to UTF-8 Then transfer to browser .
Clarify the context of character coding , Let's see python Encoding of strings in .
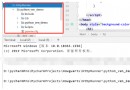
First ,python The source code of is a text file , Therefore, it is saved and read according to a certain code . When saving, the coding is performed according to the saving code specified by the editor , that python What format does the interpreter read the source code in ? With python2.7 For example , Run the following code :
# chinese you 're right , This is just a comment , In fact, no matter where Chinese appears , It's all the same , Because at this time, it is only treated as text processing . The following error will be reported after running : SyntaxError: Non-ASCII character '\xe4' in file F:/projects/pycharm/test/coding_test.py on line 2, but no encoding declared; see http://python.org/dev/peps/pep-0263/ for details
It is said that there are non - ascii character , And no code is specified , So the interpreter doesn't recognize this character , Click in That link , You can see the details . There is a saying in it :
Python will default to ASCII as standard encoding if no other encoding hints are given. If there are no other coding tips ,python By default ASCII As standard code .
It is saved according to utf-8 Code to save , So string chinese The representation in storage is '\xe4\xb8\xad\xe6\x96\x87'( It's actually binary , This hexadecimal representation is for the convenience of discussion , Byte 11100100 Expressed as \xe4). However, the code is not specified , therefore python The interpreter defaults to ASCII Code for reading , encounter \xe4 Such non ASCII Characters are naturally powerless . So we need to specify the code manually , To ensure that it is consistent with the code at the time of saving . The specified method is to specify in the first or second line of the source file , The specified string must satisfy the following regular expression : ^[ \t\f]*#.*?coding[:=][ \t]*([-_.a-zA-Z0-9]+)
The common way is :
# -*- coding: utf-8 -*-Add this line , The code will run normally .
python 3 and python 2 The character encoding of is slightly different , Here we use 2.7 For example , Understand this , Let's see python 3 In fact, it is easy to understand , It's all similar . Note that the following discussion is in python 2.7 In the .
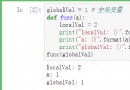
python 2.7 in , There are two types of strings , One is str, One is unicode, The difference is this :
str is text representation in bytes, unicode is text representation in unicode characters(or unicode bytes).
It means ,unicode The character encoding type of is unicode, Give a unicode character string , I will press unicode The way to decode , That is to say, the character he represents is also determined ; but str That's not the truth , It's just a few bytes , If you don't know the encoding format , Then I don't know how to deal with , Only the original typewriter can decode through the appropriate encoding set . and python stay print One str The default is to follow utf-8 To decode , So when printing the following characters , There will be garbled code :
s = '\xd6\xd0\xce\xc4'
print s The reason is that the above bytes are actually strings chinese according to gbk The result of coding , By default utf-8 When decoding for printing , Naturally, there is garbled code , To display normally , You can specify to use gbk The way to decode :
s = '\xd6\xd0\xce\xc4'
print s.decode('gbk') In this way, you can print out chinese Two words .
When we declare a string literal in quotation marks , It means str type , such as :
# -*- coding: utf-8 -*-
d = ' chinese '
print type(d)
print repr(d)repr Return object's canonical string( Standard strings ) form , When it comes to str Type , If the character is in ascii Within the code range , The character itself is displayed , otherwise , With \xXX Formal representation of , among XX Is its hexadecimal representation . The output is zero :
<type 'str'>'\xe4\xb8\xad\xe6\x96\x87'
The bytecode result here is utf-8 Coded , But this is not necessarily , It depends on the current editor settings . For example, if you run the above... From the command line python In words , The result is '\xd6\xd0\xce\xc4', This is because the environment is gbk code . So when we deal with strings , You can't see the characters on the surface , Otherwise it's easy to make mistakes , What we see chinese It may be different in different circumstances .
If you want to declare a unicode What about strings ? All you need to do is precede the quotation marks of the string with u that will do :
d = u' chinese '
print type(d)
print repr(d) Output is : <type 'unicode'>u'\u4e2d\u6587'
str and unicode Can be converted between , have access to encode and decode Method .
encode encode The input of must be unicode type , It must be a str type , That is to say unicode The string is encoded as specified , Turn into str. Output is :
decode decode The input of must be str type , It must be a unicode type , That is to say unicode The string is decoded according to the specified encoding , Turn into unicode. Output is :
Above said encode The input of must be unicode type ,decode The input of must be str type , So if it's not the corresponding type , What will happen? ? Have a try. :
d = u' chinese aa'
print d.decode('utf-8') And then it's wrong : UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1: ordinal not in range(128) That's right ascii Unable to position 0-1 Encode the characters of , Why are there codes ? I'm decoding it ? After thinking , I have a reasonable guess : If decode Input is not str type , Then it will be converted into str, in other words , Will call encode, And at this time, the code is not specified , So the default is ascii Encoding , If you encounter Chinese, you will report an error . You can do an experiment :
d = u'cc chinese aa'
d.encode() Sure enough, the mistakes reported are the same : UnicodeEncodeError: 'ascii' codec can't encode characters in position 2-3: ordinal not in range(128)
Take a look at the following code :
d = u'hello'
# print repr(d)
print repr(d.decode('utf-8'))
print repr(d.encode())No report error , The output is :
u'hello'
'hello'So it looks like , The above speculation is reasonable .
That's right python Summary of coding , While looking up information, while thinking while writing , There's a sense of openness . If there are any mistakes , Welcome to comment in the comments area .
Besides , In writing this article , Yes encode(‘base64’) and ‘unicode-escape’ I haven't fully figured it out yet , I will summarize it later .
Reference resources : [1] Liao Xuefeng python course : String and encoding [2] 0 and 1 [3] Python encode and decode
Add : about encode The input must be unicode The problem of , Here we add the following ,encode(‘base64’) The exception is , Its input is str. The experiment is as follows :
s = u'hhe Ha eh'
print type(s.encode('base64')) Report errors : UnicodeEncodeError: 'ascii' codec can't encode character u'\u54c8' in position 3: ordinal not in range(128)
From the results , Program pair s the ascii code , I can only guess that it was right first s Did it once encode, And the default is ascii code , Try again :
s = u'hhe Ha eh'
print type(s.encode().encode('base64')) The errors reported are the same : UnicodeEncodeError: 'ascii' codec can't encode character u'\u54c8' in position 3: ordinal not in range(128) Change it to :
s = u'hhe Ha eh'
print s.encode('utf-8').encode('base64')
print type(s.encode('utf-8').encode('base64'))Output :
aGhl5ZOIZWg=
<type 'str'>so encode(‘base64’) The input is str It can work normally , But for unicode It will be carried out once first encode To str( By default ascii, If not ascii Characters will report errors ), Therefore, it can be inferred that the input should be str.
In fact, just run the following code to understand :
print 'aGhl5ZOIZWg='.decode('base64')
print type('aGhl5ZOIZWg='.decode('base64'))Output :
print 'aGhl5ZOIZWg='.decode('base64')
print type('aGhl5ZOIZWg='.decode('base64')) so decode The result is not necessarily unicode, In the use of base64 When decoding , Its value is still str. The reason base64 The input and output of encoding and decoding are str, Possible and base64 The encoding rules of .
Related articles :Unicode(UTF-8, UTF-16) Confusing concepts