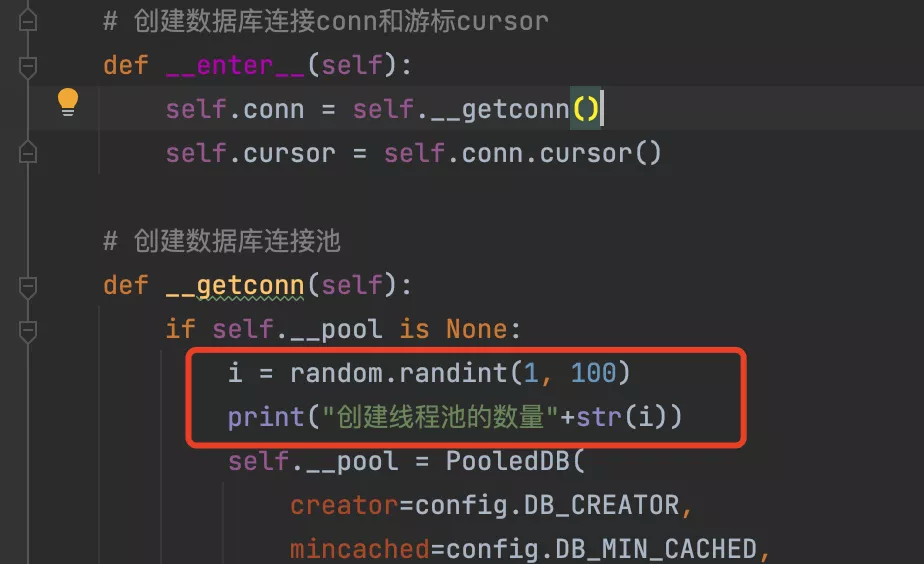
python的xlwings模塊報錯:pywintypes.com_error: (-2147352567, '發生意外。', (0, None, None, None, 0, -2147024809), None)
import pandas as pd
import xlwings as xw
app = xw.App(visible=False, add_book=False) # 啟動excel程序
hlb = app.books.open('匯率表.xls') # 打開讀取匯率簿
hlb_b = hlb.sheets[0] # 讀取工作表
bz = hlb_b.range('A1').expand('down').value # 讀取第一列幣種形成列表
hl = hlb_b.range('B1').expand('down').value # 讀取第二列匯率形成列表
hlb.close() # 關閉工作簿
print(f'第一階段{bz, hl}') # 輸出第一階段監測點ok
bz_hl = dict(zip(bz, hl)) # 組成幣種:匯率的字典
wb = app.books.open('fnd_gfm_930958.xls')
ws = wb.sheets[0]
sj = ws.range(1, 1).expand('right').value # 讀取第一行字段列表
hs = ws.range(1, 1).expand('down').rows.count
print(f'第三階段{sj, hs}') # 輸出第三階段監測點ok
hb = ['開證單位', '承付銀行', '承付幣種'] # 定義需要識別的兩個字段
a = sj.index(hb[0])+1 # 了解對應字段在工作表的列數
b = sj.index(hb[1])+1 # 承付銀行字段
c = sj.index(hb[2])+1 # 承付幣種字段
print(f'第四階段{a, b, c}') # 輸出第四階段監測點ok ** 這裡會停頓一會兒**
lst = [] # 列空表
lst_bz = [] # 幣種空列表
for i in range(1, hs): # 遍歷兩列字段做合並
sc1 = ws.range(i+1, a).value # 獲取對應單元格值
sc2 = ws.range(i+1, b).value
sc3 = ws.range(i+1, c).value
sc = r'{}-{}'.format(sc1, sc2) # 合並字段:開證單位-承付銀行
lst += [sc] # 組成列表【開證單位-承付銀行】
lst_bz += [sc3] # 組成幣種列表
print(f'第五階段{lst}') # 輸出第五階段監測點ok
jg = list(set(lst)) # 篩選掉重復值,形成無重復列表
jg_bz = list(set(lst_bz))
jg_bz = sorted(jg_bz) # 將幣種按照字母順序排列
print(f'第六階段{jg_bz}') # 輸出第六階段監測點ok
jg_gs = len(jg) # 列表個數
jg_bz_gs = len(jg_bz)
print(f'第七階段{jg_gs}') # 輸出第七階段監測點ok
ws2 = wb.sheets.add(name='輸出結果', after=ws)
ws2.range(2, 1).value = ['開證單位', '承付銀行', '折合人民幣金額'] # 編寫正常文字
ws2.range(1, 2).value = '承付幣種'
for j in range(jg_gs): # 遍歷列表【開證單位-承付銀行】
sr = jg[j].split('-') # 拆分列表字段:開征單位 承付銀行 兩個列表
print(f'第八階段{sr}') # 輸出第八階段監測點ok 然後後面的就運行不了出現報錯
ws2.range(j+3, 0).value = sr[0] # 工作表輸入字段1
ws2.range(j+3, 1).value = sr[1]
for j in range(jg_bz_gs): # 遍歷幣種列表
ws2.range(1, j+4).value = jg_bz[j] # 輸入字段
ws2.autofit('c') # 自動調整列寬
data = pd.read_excel('fnd_gfm_930958.xls') # 利用pandas模塊讀取excel數據
print(data['承付金額'].sum())
for x in jg_bz: # 遍歷幣種列表
shuzi = jg_bz.index(x) # 找到幣種列表的位數
try:
dy_hl = bz_hl[x] # 在幣種-匯率字典找到對應幣種的匯率值
ws2.range(2, shuzi+4).value = dy_hl # 書寫在第二行
except KeyError:
ws2.range(2, shuzi+4).value = ' ' #填寫第二行幣種
lst2 = []
for x in range(jg_gs): # 遍歷列表【開證單位-承付銀行】對應書寫行數
for y in range(jg_bz_gs): # 遍歷幣種列表對應書寫列數
d = jg[x].split('-')
e = data[(data['開證單位'] == d[0]) & (data['承付銀行'] == d[1]) & (data['承付幣種'] == jg_bz[y])
& (data['已拒付'] == 'N') & (data['財務備注'].str.contains('購匯'))] # 利用篩選條件篩選數據
f = e['承付金額'].sum() # 篩選數據簡單求和
g = e['申請使用外匯金額'].sum() # 篩選出使用外匯金額
lst2 += [f-g]
# print(f)
ws2.range(x+3, y+40).value = f-g
wb.save("結果文件.xls") # 保存工作簿
wb.close()
app.quit()
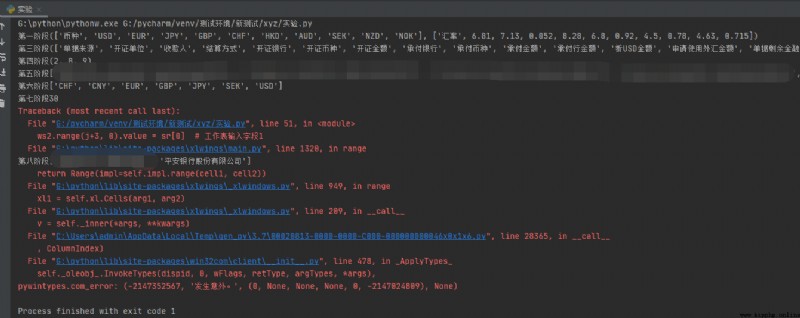
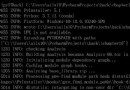
百度過,說是之前的文檔還打開著才會出現這種報錯,但是我這是在一個excel裡操作,為啥也會