I cleaned it up a few days ago and found that there are only two points to pay attention to
First, remember to use a belt cookie The way to visit , That's instantiation requests.session()
The second is to transform the crawling url, Access crawled url Get back Location value , This value is the real address ( If you're not going to climb url When I didn't say )
Knowing these two points, you can try it first , It's not as hard as you think , I can't crawl out to see the code
No cookie visit , Direct use requests.get() visit , You can see that you can only successfully visit once . Other status codes are 200 But it should trigger the anti crawl mechanism and return other pages to you
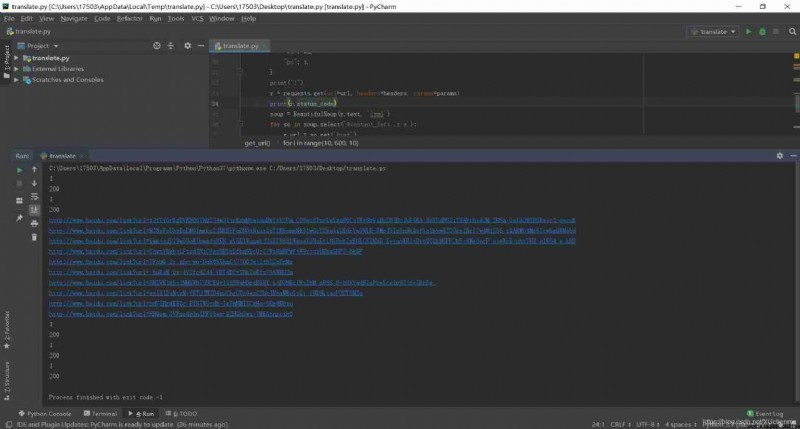
belt cookie visit , Basically succeeded
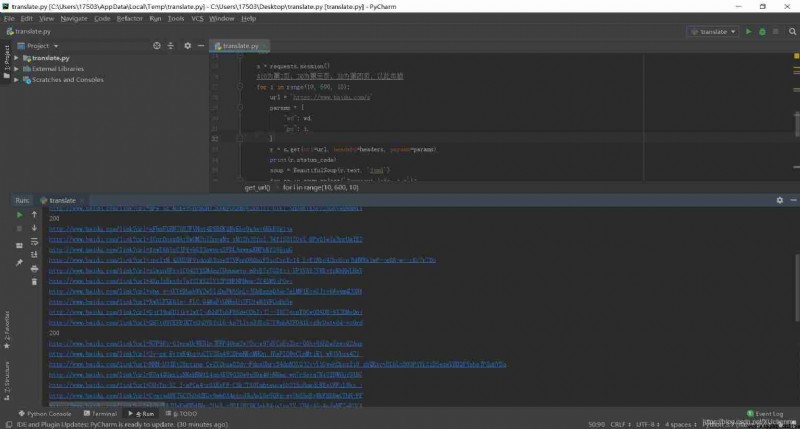
Convert it to url, To get the final url
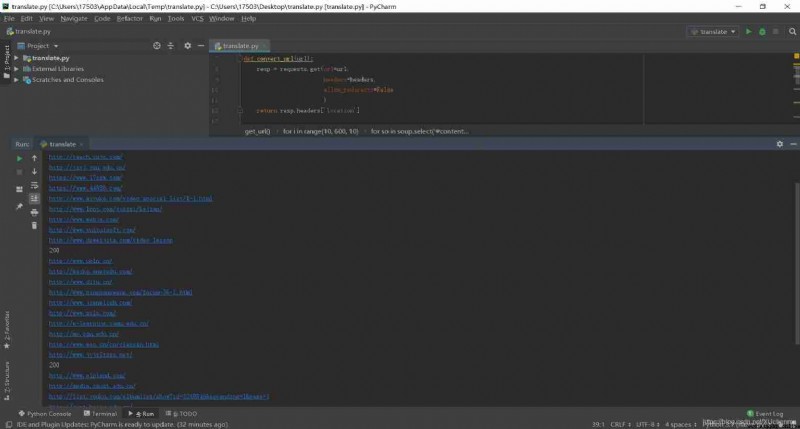
import requests
from bs4 import BeautifulSoup
import time
# Will Baidu's url Turn into real url
def convert_url(url):
resp = requests.get(url=url,
headers=headers,
allow_redirects=False
)
return resp.headers['Location']
# obtain url
def get_url(wd):
s = requests.session()
#10 For the first time 2 page ,20 It's page three ,30 Page 4 , And so on
for i in range(10, 600, 10):
url = 'https://www.baidu.com/s'
params = {
"wd": wd,
"pn": i,
}
r = s.get(url=url, headers=headers, params=params)
print(r.status_code)
soup = BeautifulSoup(r.text, 'lxml')
for so in soup.select('#content_left .t a'):
g_url = so.get('href')
print(convert_url(g_url))
time.sleep(1 + (i / 10))
if __name__ == '__main__':
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:73.0) Gecko/20100101 Firefox/73.0",
"Host": "www.baidu.com",
}
wd = input(" Enter search keywords :")
get_url(wd)