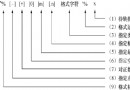
DataFrame.drop_duplicates(self, subset=None, keep='first', inplace=False)[source]
There are three parameters ,subset、keep and inplace
subset : column label or sequence of labels, optional
Only consider certain columns for identifying duplicates, by default use all of the columns
subset Parameter is used to set which column repetition is used as the repetition standard , Parameters are column labels , If the value is not set , The default is to use all columns as the repeated judgment condition .
keep : {
‘first’, ‘last’, False}, default ‘first’
first : Drop duplicates except for the first occurrence.
last : Drop duplicates except for the last occurrence.
False : Drop all duplicates.
keep It can be set to three parameters , The default is first
first It means to keep the record of the first occurrence
last It means to keep the record of the last occurrence
False Delete all duplicates
inplace : boolean, default False
Whether to drop duplicates in place or to return a copy
inplace It can be set to True or False, The default is False
True It means to remove the weight in place , Will change dataframe
False Indicates that a new... Will be returned dataframe, It won't change the original variable
import pandas as pd
data = pd.DataFrame([[1, 'Wang', 20], [2, 'Li', 20], [1, 'Wang', 21], [1, 'Wang', 20]], columns=['id', 'name', 'age'])
The data is
id name age
0 1 Wang 20
1 2 Li 20
2 1 Wang 21
3 1 Wang 20
Obviously No 0 Article and paragraph 3 Duplicate records , Use the default usage to remove
print(data.drop_duplicates())
The result is
id name age
0 1 Wang 20
1 2 Li 20
2 1 Wang 21
It is obvious that the first 0 Bar record , And go except for the first 3 Bar record , By setting keep Parameter is last Make it keep the last parameter
print(data.drop_duplicates(keep='last'))
The result is
id name age
1 2 Li 20
2 1 Wang 21
3 1 Wang 20
And for datasets
id name age
0 1 Wang 20
1 2 Li 20
2 1 Wang 21
3 1 Wang 20
Think id and name The same is repetition , have access to
print(data.drop_duplicates(['id', 'name']))
obtain
id name age
0 1 Wang 20
1 2 Li 20
If you want to delete all duplicate data , Then use
print(data.drop_duplicates(['id', 'name'], keep=False))
obtain
id name age
1 2 Li 20