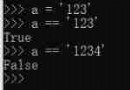目錄
1.import 和 from … import 模塊的變量、方法引用差異
2.python中出現' 'int' object is not callable'的錯誤
3.seaborn.heatmap(參數介紹)
4. pd.date_range()
5.pd.Series()
6.ARIMA建模的步驟
7.python 中with 用法
8.Python包中__init__.py作用
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple --user tensorflow==1.15
安裝各個包的方法,上面的鏡像是清華大學的, --user不加有時候會報錯
這個是python小白記錄的,本人才開始學這個,如果大神有什麼疑義,請批評指正
from pandas import DataFrame from…import // 直接使用函數名使用就可以了
import pandas as pd import //模塊.函數
a.import…as
import:導入一個模塊;注:相當於導入的是一個文件夾,是個相對路徑
import A as B:給予工具庫 A 一個簡單的別稱 B ,可以幫助記憶。例:import torch.nn as nn;import torch as t
b.from…import
from…import:導入了一個模塊中的一個函數;注:相當於導入的是一個文件夾中的文件,是個絕對路徑。
例:如 from A import b,相當於
import A
b = A.b
import //模塊.函數,導入模塊,每次使用模塊中的函數都要是定是哪個模塊。
from…import // 直接使用函數名使用就可以了
from…import* // 是把一個模塊中所有函數都導入進來; 注:相當於:相當於導入的是一個文件夾中所有文件,所有函數都是絕對路徑。
示例:
模塊 support.py:
def print_func( par ):
print "Hello : ", par
return# 導入模塊
import support
# 現在可以調用模塊裡包含的函數了
support.print_func("Runoob")
不能直接使用 print_func() 實現調用,必須將引入的模塊名稱當作一個對象,調用這個模塊對象下的方法 print_func,這時才能實現調用
====================================================
# 導入模塊
from support import *
# 現在可以調用模塊裡包含的函數了
print_func("Runoob")
可以直接使用 print_func() 實現調用一般來說,推薦使用 import 語句,避免使用 from … import,因為這樣可以使你的程序更加易讀,也可以避免名稱沖突。
https://blog.csdn.net/yucicheung/article/details/79445350
=======================================================================
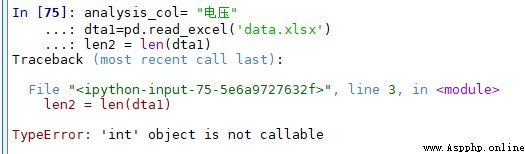
在用spyder寫python時,在某一行使用了len函數處提示’int’ object is not callable的錯誤。
原因是在Variable explorer中存在了一個名為len的變量,這個len變量是在運行別的腳本時定義的,把這個變量清空以後,程序便可正常運行。
所以以後在運行程序時,要養成先把Variable explorer中的變量先清空再運行的習慣。
=======================================================================
import seaborn as sns
fig, ax = plt.subplots(figsize=(9, 9))
sns.heatmap(pd.DataFrame(res),
annot=True, vmax=1, vmin=0, xticklabels=True, yticklabels=True, square=True, cmap="YlGnBu")
ax.set_title('test', fontsize=18)
plt.show()
import seaborn as sns
import numpy as np
data = np.array([[1,2,3],[4,5,6],[7,8,9]])
sns.heatmap(data,annot=True)seaborn.heatmap(data, vmin=None, vmax=None, cmap=None, center=None, robust=False, annot=None, fmt='.2g', annot_kws=None, linewidths=0, linecolor='white', cbar=True, cbar_kws=None, cbar_ax=None, square=False, xticklabels='auto', yticklabels='auto', mask=None, ax=None, **kwargs)
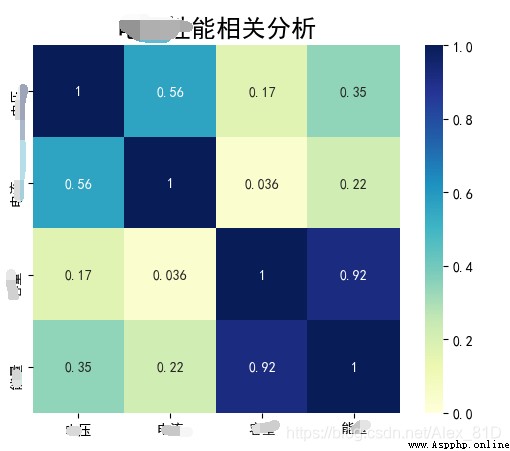
不如先用最簡單的,其實也是最核心的,這裡的data是最復雜的參數了,其他的只是用來裝飾熱力圖的,那麼這個熱力圖是用來干嘛的,
就是可視化一下已經有的數字,得到的 res = data.corr(method='spearman') 有很強的可視化效果
那麼各個參數具體是什麼意思
data:為核心參數,矩形數據集,顯示主題圖,其他都是裝飾:
annot: 默認為False,為True的話,會在格子上顯示數字
vmax, vmin: 熱力圖顏色取值的最大值,最小值,默認會從data中推導
cmap:matplotlib 顏色條名稱或者對象,或者是顏色列表,可選參數。從數據值到顏色空間的映射。 如果沒有提供,默認值將取決於是否設置了“center” ,cmap="YlGnBu"
xticklabels, yticklabels:“auto”,布爾值,類列表值,或者整形數值,可選參數。如果是True,則繪制dataframe的列名。如果是False,則不繪制列名,默認為True
返回值:ax:matplotlib Axes
熱力圖的軸對象
square:布爾值,可選參數。如果為 True,則將坐標軸方向設置為“equal”,以使每個單元格為方形,默認為False
還有很多參數可參考這篇文章:https://blog.csdn.net/hongguihuang/article/details/105711115
這裡說一個bug,有時候畫的圖是半個顯示,最上面的和最下面只有半個,據說是所用版本matplotlib的bug
解決辦法如下:
ax = sns.heatmap(...);
#把這個直接加入到代碼下面就可以了
bottom, top = ax.get_ylim()
ax.set_ylim(bottom + 0.5, top - 0.5)
=======================================================================
pd.date_range('1900-1-1', freq="D", periods=len4)
語法:pandas.date_range(start=None, end=None, periods=None, freq='D', tz=None, normalize=False, name=None, closed=None, **kwargs)
該函數主要用於生成一個固定頻率的時間索引,在調用構造方法時,必須指定start、end、periods中的兩個參數值,否則報錯。
主要參數說明:
periods:固定時期,取值為整數或None
freq:日期偏移量,取值為string或DateOffset,默認為'D' (天)
normalize:若參數為True表示將start、end參數值正則化到午夜時間戳
name:生成時間索引對象的名稱,取值為string或None
eg: a1 = pd.date_range('1900-1-1', freq="D", periods=10)
DatetimeIndex(['1900-01-01', '1900-01-02', '1900-01-03', '1900-01-04',
'1900-01-05', '1900-01-06', '1900-01-07', '1900-01-08',
'1900-01-09', '1900-01-10'],
dtype='datetime64[ns]', freq='D')
=======================================================================
series是一個一維數組,是基於NumPy的ndarray結構。Pandas會默然用0到n-1來作為series的index,但也可以自己指定index(可以把index理解為dict裡面的key)
Series([data, index, dtype, name, copy, …])
pd.Series([list],index=[list])
import pandas as pd
index = ['a','b','c','f','e']
s=pd.Series([1,2,3,4,5],index)
print(s)a 1
b 2
c 3
f 4
e 5
dtype: int64
=======================================================================
誤差是白噪音的時候,model就ok了,就可以預測了
=======================================================================
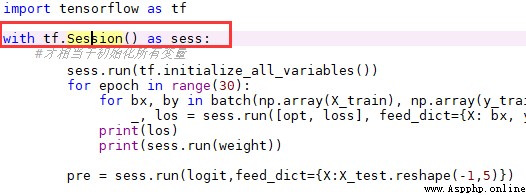
在Python中,如果一個對象有__enter__和__exit__方法,就可以在with語句中使用它。
with塊結束時會調用相應的__exit__中的代碼.因此,我們不需要再寫相應的代碼去close,無論是因為什麼原因結束with.
with open(...) as f:
print(f.readall())等價於 ||
f = open(...)
print(f.readal())
f.close()如果不使用with,考慮到f2可能會打開失敗或者後續的操作會出錯,我們可以需要這樣去寫:
f1 = open(...)
try:
f2 = open(...)
...
catch:
pass
else:
f2.close()
f1.close()這樣寫出來太不優雅了,你得自己去捕獲異常,手動關閉流、session等這些資源。
同時,我們還可以在一個with 語句中包括多個對象:
with open(...) as f1, open(...) as f2:
...
總結:
__init__.py的主要作用是:
1. Python中package的標識,不能刪除
2. 定義__all__用來模糊導入
3. 編寫Python代碼(不建議在__init__中寫python模塊,可以在包中在創建另外的模塊來寫,盡量保證__init__.py簡單)
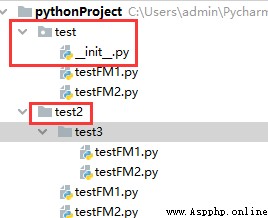
https://blog.csdn.net/yucicheung/article/details/79445350
https://www.cnblogs.com/AlwinXu/p/5598543.html
loc函數:通過行索引 “Index” 中的具體值來取行數據(如取"Index"為"A"的行)
iloc函數:通過行號來取行數據(如取第二行的數據)
df.iloc["1", :] : 第一行的所有數據
df.loc['a'] :取索引為'a'的行
from gensim import corpora
from collections import defaultdict
import jieba
from gensim.corpora import Dictionary
wordslist = ["我在玉龍雪山","我喜歡玉龍雪山","我還要去玉龍雪山"]
# 切詞
textTest = [[word for word in jieba.cut(words)] for words in wordslist]
# 生成字典
dictionary = Dictionary(textTest,prune_at=2000000)
for key in dictionary.iterkeys():
print (key,dictionary.get(key),dictionary.dfs[key])
dictionary.filter_extremes(no_below=5, no_above=0.5, keep_n=1000)
for key in dictionary.iterkeys():
print (key,dictionary.get(key),dictionary.dfs[key])
關鍵API講解
dictionary.filter_n_most_frequent(N)
過濾掉出現頻率最高的N個單詞
dictionary.filter_extremes(no_below=5, no_above=0.5, keep_n=100000)
1.去掉出現次數低於no_below的
2.去掉出現次數高於no_above的。注意這個小數指的是百分數
3.在1和2的基礎上,保留出現頻率前keep_n的單詞
dictionary.filter_tokens(bad_ids=None, good_ids=None)
有兩種用法,一種是去掉bad_id對應的詞,另一種是保留good_id對應的詞而去掉其他詞。注意這裡bad_ids和good_ids都是列表形式
dictionary.compacity()
在執行完前面的過濾操作以後,可能會造成單詞的序號之間有空隙,這時就可以使用該函數來對詞典來進行重新排序,去掉這些空隙。
corpora.Dictionary 對象
可以理解為python中的字典對象, 其Key是字典中的詞,其Val是詞對應的唯一數值型ID
構造方法 Dictionary(documents=None, prune_at=2000000)
prune_at參數 起到控制向量的維數的作用
https://blog.csdn.net/qq_19707521/article/details/79174533
https://blog.csdn.net/kylin_learn/article/details/83047880
https://blog.csdn.net/xuxiuning/article/details/47720337
http://www.voidcn.com/article/p-mjlmvwmn-pq.html
vector_a = np.mat(emb)
vector_b = np.mat(tp_emb)
num = float(vector_a * vector_b.T)
denom = np.linalg.norm(vector_a) * np.linalg.norm(vector_b)
cos = num / denom
sim = 0.5 + 0.5 * cos#方法一:
import numpy as np
def cos_sim(vector_a, vector_b):
"""
計算兩個向量之間的余弦相似度
:param vector_a: 向量 a
:param vector_b: 向量 b
:return: sim
"""
vector_a = np.mat(vector_a)
vector_b = np.mat(vector_b)
num = float(vector_a * vector_b.T)
denom = np.linalg.norm(vector_a) * np.linalg.norm(vector_b)
cos = num / denom
sim = 0.5 + 0.5 * cos
return sim#方法二:
def cosine_similarity(x, y, norm=False):
""" 計算兩個向量x和y的余弦相似度 """
# method 1
res = np.array([[x[i] * y[i], x[i] * x[i], y[i] * y[i]] for i in range(len(x))])
cos = sum(res[:, 0]) / (np.sqrt(sum(res[:, 1])) * np.sqrt(sum(res[:, 2])))
return 0.5 * cos + 0.5 if norm else cos # 歸一化到[0, 1]區間內https://www.jianshu.com/p/0c33c17770a0
https://blog.csdn.net/hereiskxm/article/details/52526842
https://blog.csdn.net/zhuzuwei/article/details/80777623