利用python爬取網站數據非常便捷,效率非常高,但是常用的一般都是使用BeautifSoup、requests搭配組合抓取靜態頁面(即網頁上顯示的數據都可以在html源碼中找到,而不是網站通過js或者ajax異步加載的),這種類型的網站數據爬取起來較簡單。但是有些網站上的數據是通過執行js代碼來更新的,這時傳統的方法就不是那麼適用了。這種情況下有如下幾種方法:
清空網頁上的network信息,更新頁面,觀察網頁發送的請求,有些網站可以通過這種方法構造參數,從而簡化爬蟲。但是適用范圍不夠廣泛。
使用selenium模擬浏覽器行為更新網頁獲取更新後的數據。本文接下來著重講述這種方法。
模擬浏覽器需要用到兩個工具:
1.selenium,可直接通過pip install selenium進行安裝。
2.PhantomJS,這是一個無界面的,可腳本編程的WebKit浏覽器引擎,百度進行搜索,在其官網下進行下載,下載後無需安裝,放到指定路徑下,在使用時只需指定文件所在路徑即可。
本文爬取網站示例為:http://datacenter.mep.gov.cn:8099/ths-report/report!list.action?xmlname=1465594312346(最新測試發現網站已無法打開,2021年5月25日)
學習示例時請不要爬取太多頁面,走一遍流程了解怎麼抓就行。
打開網站後,可以看到需要爬取的數據為一個規則的表格,但是有很多頁。
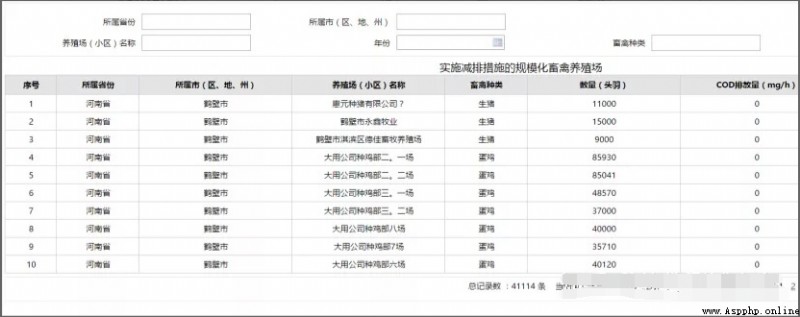
在這個網站中,點擊下一頁頁面的url不發生變化,是通過執行一段js代碼更新頁面的。因此本文思想就是利用selenium模擬浏覽器進行點擊,點擊“下一頁”後頁面數據進行更新,獲取更新後的頁面數據即可。下面是完整代碼:
# -*- coding:utf-8 -*- import requests from bs4 import BeautifulSoup import json import time from selenium import webdriver import sys reload(sys) sys.setdefaultencoding( "utf-8" ) curpath=sys.path[0] print curpath def getData(url): # 使用下載好的phantomjs,網上也有人用firefox,chrome,但是我沒有成功,用這個也挺方便 driver =webdriver.PhantomJS(executable_path="C:/phantomjs.exe") driver.set_page_load_timeout(30) time.sleep(3) html=driver.get(url[0]) # 使用get方法請求url,因為是模擬浏覽器,所以不需要headers信息 for page in range(3): html=driver.page_source # 獲取網頁的html數據 soup=BeautifulSoup(html,'lxml') # 對html進行解析,如果提示lxml未安裝,直接pip install lxml即可 table=soup.find('table',class_="report-table") name=[] for th in table.find_all('tr')[0].find_all('th'): name.append(th.get_text()) # 獲取表格的字段名稱作為字典的鍵 flag=0 # 標記,當爬取字段數據是為0,否則為1 for tr in table.find_all('tr'): # 第一行為表格字段數據,因此跳過第一行 if flag==1: dic={
}
i=0
for td in tr.find_all('td'):
dic[name[i]]=td.get_text()
i+=1
jsonDump(dic,url[1])#保存數據
flag=1
# 利用find_element_by_link_text方法得到下一頁所在的位置並點擊,點擊後頁面會自動更新,只需要重新獲取driver.page_source即可
driver.find_element_by_link_text(u"下一頁").click()
def jsonDump(_json,name):
"""store json data"""
with open(curpath+'/'+name+'.json','a') as outfile:
json.dump(_json,outfile,ensure_ascii=False)
with open(curpath+'/'+name+'.json','a') as outfile:
outfile.write(',\n')
if __name__ == '__main__':
url=['http://datacenter.mep.gov.cn:8099/ths-report/report!list.action?xmlname=1465594312346','yzc'] # yzc為文件名,此處輸入中文會報錯,前面加u也不行,只好保存後手動改文件名……
getData(url) # 調用函數
本文中獲取下一頁的位置是通過driver.find_element_by_link_text方法來實現的,這是因為在此網頁中,這個標簽沒有唯一可標識的id,也沒有class,如果通過xpath定位的話,第一頁和其他頁的xpath路徑又不完全相同,需要加個if進行判斷。因此直接通過link的text參數進行定位。click()函數模擬在浏覽器中的點擊操作。
selenium的功能非常強大,用在爬蟲上能夠解決很多一般爬蟲解決不了的問題,它可以模擬點擊、鼠標移動,可以提交表單(應用如:登陸郵箱賬號、登陸wifi等,網上有很多實例,本人暫時還沒有嘗試過),當你遇到一些非常規的網站數據爬取起來非常棘手時,不妨嘗試一下selenium+phantomjs。
最後感謝每一個認真閱讀我文章的人,下面這個網盤鏈接也是我費了幾天時間整理的非常全面的,希望也能幫助到有需要的你!
這些資料,對於想轉行做【軟件測試】的朋友來說應該是最全面最完整的備戰倉庫,這個倉庫也陪伴我走過了最艱難的路程,希望也能幫助到你!凡事要趁早,特別是技術行業,一定要提升技術功底。希望對大家有所幫助……
如果你不想一個人野蠻生長,找不到系統的資料,問題得不到幫助,堅持幾天便放棄的感受的話,可以點擊下方小卡片加入我們群,大家可以一起討論交流,裡面會有各種軟件測試資料和技術交流。
點擊文末小卡片領取敲字不易,如果此文章對你有幫助的話,點個贊收個藏來個關注,給作者一個鼓勵。也方便你下次能夠快速查找。
零基礎轉行軟件測試:25天從零基礎轉行到入職軟件測試崗,今天學完,明天就業。【包括功能/接口/自動化/python自動化測試/性能/測試開發】
自動化測試進階:2022B站首推超詳細python自動化軟件測試實戰教程,備戰金三銀四跳槽季,進階學完暴漲20K