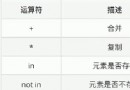
Call the instance :
import scipy
import scipy.cluster.hierarchy as sch
from scipy.cluster.vq import vq,kmeans,whiten
import numpy as np
import matplotlib.pylab as plt
points=scipy.randn(20,4)
#1. Hierarchical clustering
# Generate a distance matrix between points , The Euclidean distance used here :
disMat = sch.distance.pdist(points,'euclidean')
# Hierarchical clustering :
Z=sch.linkage(disMat,method='average')
# The hierarchical clustering results are represented in a tree view and saved as plot_dendrogram.png
P=sch.dendrogram(Z)
plt.savefig('plot_dendrogram.png')
# according to linkage matrix Z Get the clustering results :
cluster= sch.fcluster(Z, t=1, 'inconsistent')
print "Original cluster by hierarchy clustering:\n",clusterThe parameter list is as follows :
def fcluster(Z, t, criterion='inconsistent', depth=2, R=None, monocrit=None):Z Represents the use of “ correlation function ” Related data .
For example, the above call example uses the Euclidean distance to generate the distance matrix , And the distance of the matrix is averaged
Different distance formulas can be used here
t This parameter is used to distinguish the thresholds of different clusters , In different criterion The parameters set under different conditions are different .
For example, when criterion by ’inconsistent’ when ,t The value should be in 0-1 between ,t The closer the 1 Represents the greater the correlation between the two data ,t More and more 0 It indicates that the correlation between the two data is smaller . This correlation can be used to compare the correlation between two vectors , It can be used for clustering in high dimensional space
depth Represents a process of inconsistency (‘inconsistent’) The maximum depth at the time of calculation , It doesn't make sense for other parameters , The default is 2
criterion This parameter represents the decision condition , Here, the meaning of each parameter is explained in detail :
1. When criterion by ’inconsistent’ when ,t The value should be in 0-1 between ,t The closer the 1 Represents the greater the correlation between the two data ,t More and more 0 It indicates that the correlation between the two data is smaller . This correlation can be used to compare the correlation between two vectors , It can be used for clustering in high dimensional space
2. When criterion by ’distance’ when ,t The value represents the absolute difference , If it is less than this difference , The two data will be merged , When greater than this difference , The two data will be separated .
3. When criterion by ’maxclust’ when ,t Represents the maximum number of clusters , Set up 4 Then the maximum number of clusters is 4 class , When clustering meets 4 Class time , Iteration stop
4. When criterion by ’monocrit’ when ,t Your choice is not fixed , But according to a function monocrit[j] To make sure . For example , The threshold of the maximum average distance is in the inconsistency matrix r Calculate the threshold in 0.8, It can be written like this ,
MR = maxRstat(Z, R, 3)
cluster(Z, t=0.8, criterion='monocrit', monocrit=MR)MI = maxinconsts(Z, R)
cluster(Z, t=3, criterion='maxclust_monocrit', monocrit=MI)