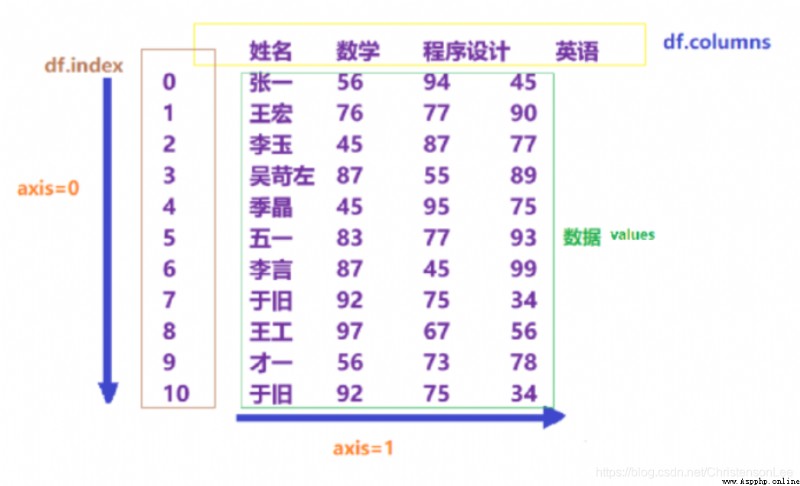
1.格式:pandas.DataFrame(data[,index[,columns]])
2.隨機數生成DataFrame對象,使用默認索引。
import numpy as np
import pandas as pd
#設置輸出結果列對齊
pd.set_option('display.unicode.ambiguous_as_wide', True)
pd.set_option('display.unicode.east_asian_width', True)
#在[1,20]區間上生成5行3列15個隨機數
#使用index參數指定索引(默認從0開始),columns參數指定每列標題
df = pd.DataFrame(np.random.randint(1, 20, (5,3)),
index=range(5),
columns=('A', 'B', 'C'))
#print(df,df.values,df.index,df.columns,sep='\n\n')
3.隨機數生成DataFrame對象,使用時間序列作為索引
# 模擬2020年7月15日某超市熟食、化妝品、日用品每小時的銷量
# 使用時間序列作為索引
df = pd.DataFrame(np.random.randint(5, 15, (10, 3)),
index=pd.date_range(start='202007150900',
end='202007151800',
freq='H'),
columns=['熟食', '化妝品', '日用品'])
#print(df,df.values,df.index,df.columns,sep='\n\n')
4.用字典創建DataFrame對象 使用姓名字符串做索引
df = pd.DataFrame({
'語文':[87,79,67,92],
'數學':[93,89,80,77],
'英語':[90,80,70,75]},
index=['張三', '李四', '王五', '趙六'])
#print(df,df.values,df.index,df.columns,sep='\n\n')
5.嵌套字典創建DataFrame對象.
外部的鍵生成列名稱,內部的鍵生成索引標簽。
df = pd.DataFrame({
'張三':{
'數學':67,'程序設計':78},
'楊下':{
'物理':78,'程序設計':99},
'冒瞳':{
'數學':56,'實習':67}})
print(df,df.values,df.index,df.columns,sep='\n\n')
運行結果:
張三 楊下 冒瞳
數學 67.0 NaN 56.0
程序設計 78.0 99.0 NaN
物理 NaN 78.0 NaN
實習 NaN NaN 67.0
[[67. nan 56.]
[78. 99. nan]
[nan 78. nan]
[nan nan 67.]]
Index(['數學', '程序設計', '物理', '實習'], dtype='object')
Index(['張三', '楊下', '冒瞳'], dtype='object')
6.用由Series組成的字典生成DataFrame對象
df = pd.DataFrame({
'product':pd.Series(['電視機','手機','空調']),
'price':pd.Series([6500,3400,7899]),
'count':[23,45,28]})
df1 = pd.DataFrame({
'product':['電視機','手機','空調'],
'price':[6500,3400,7899],
'count':[23,45,28]})
print(df,df1,sep='\n\n')
#可以對字典進行部分選擇,生成DataFrame對象
dt = {
'product':['電視機','手機','空調'],
'price':[6500,3400,7899],
'count':[23,45,28]}
#生成由'product'與'count'為列的DataFrame對象
df1 = pd.DataFrame(dt,columns=['product','count'])
print('\n',df1)
運行結果:
product price count
0 電視機 6500 23
1 手機 3400 45
2 空調 7899 28
product price count
0 電視機 6500 23
1 手機 3400 45
2 空調 7899 28
product count
0 電視機 23
1 手機 45
2 空調 28
1.查看前n行、後n行數據 : 函數head()與tail()的使用
df = pd.DataFrame({
'語文':[87,79,67,92,67,87,54],
'數學':[93,89,80,77,56,78,69],
'英語':[90,80,70,75,75,34,85]},
index=['張三', '李四', '王五', '趙六','王冠','張一','吳玉'])
print('查看全部數據'.center(20,'='))
#print(df,'\n')
#查看前n行、後n行數據 : 函數head()與tail()的使用
print('查看前5行的數據'.center(20,'='))
#print(df.head(5),df.head(),sep='\n\n') #不帶參數,默認為 5
print('查看後3行的數據'.center(20,'='))
#print(df.tail(3),df.tail(),sep='\n\n') #不帶參數,默認為 5
2.利用列名訪問一列的數據
#利用列名訪問一列的數據
print('\n',df)
print('利用[列名]訪問整列的數據'.center(20,'='))
print(df['語文'].head(2))
print("df.列名 與 df['列名'] 訪問相同".center(30,'='))
print(df['語文'],df.語文,sep='\n')
#利用[列名,列名,...]訪問多列的數據
print('利用[列名,列名,...]訪問多列的數據'.center(26,'='))
print(df[ ['語文','英語'] ].tail(6))
運行結果:
語文 數學 英語
張三 87 93 90
李四 79 89 80
王五 67 80 70
趙六 92 77 75
王冠 67 56 75
張一 87 78 34
吳玉 54 69 85
===利用[列名]訪問整列的數據====
張三 87
李四 79
Name: 語文, dtype: int64
====df.列名 與 df['列名'] 訪問相同=====
張三 87
李四 79
王五 67
趙六 92
王冠 67
張一 87
吳玉 54
Name: 語文, dtype: int64
===利用[列名,列名,...]訪問多列的數據===
語文 英語
李四 79 80
王五 67 70
趙六 92 75
王冠 67 75
張一 87 34
吳玉 54 85
3.訪問指定信息
#訪問指定信息的所有信息,如顯示"吳玉"的所有成績
# 條件查詢,通過行索引訪問。
print('顯示吳玉的所有成績'.center(30,'='))
print(df[df.index=='吳玉'])
print('顯示王冠的所有成績'.center(30,'='))
print(df[df.index=='王冠'])
print('顯示趙六的所有成績'.center(30,'='))
print(df[df.index=='趙六'])
4.新增或修改一條列數據
# 新增一條列數據,新增數據需與原數據的行個數匹配。否則會ValueError拋出異常
df['python'] = [78,54,89,76,56,45,87] #若索引不存在,新增一條數據
df['語文'] = [100,100,100,100,100,100,100] #若索引存在,修改數據
print(df)
5.新增或修改一條行數據
# 用loc函數(查詢),直接插入一行
print('新增 於一 的所有的成績'.center(29,'='))
df.loc['於一'] = [66,45,88,99] #若索引不存在,新增一條數據
df.loc['趙六'] = [99,99,99,99] #若索引存在,修改數據
print(df)
運行結果:
==========顯示吳玉的所有成績===========
語文 數學 英語
吳玉 54 69 85
==========顯示王冠的所有成績===========
語文 數學 英語
王冠 67 56 75
==========顯示趙六的所有成績===========
語文 數學 英語
趙六 92 77 75
語文 數學 英語 python
張三 100 93 90 78
李四 100 89 80 54
王五 100 80 70 89
趙六 100 77 75 76
王冠 100 56 75 56
張一 100 78 34 45
吳玉 100 69 85 87
=========新增 於一 的所有的成績========
語文 數學 英語 python
張三 100 93 90 78
李四 100 89 80 54
王五 100 80 70 89
趙六 99 99 99 99
王冠 100 56 75 56
張一 100 78 34 45
吳玉 100 69 85 87
於一 66 45 88 99
6.利用切片訪問一行或多行的數據
#利用切片訪問一行或多行的數據
print('利用切片訪問一行或多行的數據'.center(26,'='))
print(df[:1],df[3:6],sep='\n\n')
#利用索引訪問指定的元素
print(df['數學'][6])
運行結果:
======利用切片訪問一行或多行的數據======
語文 數學 英語 python
張三 100 93 90 78
語文 數學 英語 python
趙六 99 99 99 99
王冠 100 56 75 56
張一 100 78 34 45
69
7.利用切片訪問多行多列數據
print('利用切片訪問多行多列數據'.center(26,'='))
#print(df[ ['語文','python','數學'] ][2:5])
#print(df[2:5][ ['語文','python','數學'] ])
運行結果:
=======利用切片訪問多行多列數據=======
語文 python 數學
王五 100 89 80
趙六 99 99 99
王冠 100 56 56
語文 python 數學
王五 100 89 80
趙六 99 99 99
王冠 100 56 56
8.利用 loc,iloc 進行訪問或修改指定信息
''' loc[行索引名稱或條件,列索引名稱] iloc[行索引位置,列索引位置] 或 iloc[行索引位置] 即 iloc使用數字做索引 '''
print(df)
print('索引為5的行 iloc[5]'.center(40,'='))
print(df.iloc[5])
print('索引為[3:5]的行 iloc[3:5]'.center(40, '='))
print(df.iloc[3:5])
print('索引為[3:5]的行且列為0:2的所有數據'.center(40, '='))
print(df.iloc[3:5,0:2])
print('訪問指定行(0,3,5)指定列(0,2)的數據'.center(40, '='))
print(df.iloc[[0,3,5],[0,2]])
print('訪問"於一"的語文與python成績'.center(40, '='))
print(df)
print('修改行索引為5的值 iloc[5]'.center(40,'='))
df.iloc[5]=[100,65,99,99] #修改行索引為5的值
print(df.iloc[5])
print('修改索引為[3:5]的行的數據 iloc[3:5]'.center(40, '='))
df.iloc[3:5]=100 #索引為[3:5]所有數據都被修改為100
print(df.iloc[3:5])
print('將python成績乘以0.7'.center(40, '='))
df.語文 =df.語文*0.7
print(df)
print('將"吳玉"成績都加10'.center(40, '='))
df.loc['吳玉'] =df.loc['吳玉']+10
運行結果:
語文 數學 英語 python
張三 100 93 90 78
李四 100 89 80 54
王五 100 80 70 89
趙六 99 99 99 99
王冠 100 56 75 56
張一 100 78 34 45
吳玉 100 69 85 87
於一 66 45 88 99
=============索引為5的行 iloc[5]=============
語文 100
數學 78
英語 34
python 45
Name: 張一, dtype: int64
==========索引為[3:5]的行 iloc[3:5]==========
語文 數學 英語 python
趙六 99 99 99 99
王冠 100 56 75 56
=========索引為[3:5]的行且列為0:2的所有數據==========
語文 數學
趙六 99 99
王冠 100 56
========訪問指定行(0,3,5)指定列(0,2)的數據=========
語文 英語
張三 100 90
趙六 99 99
張一 100 34
===========訪問"於一"的語文與python成績===========
語文 數學 英語 python
張三 100 93 90 78
李四 100 89 80 54
王五 100 80 70 89
趙六 99 99 99 99
王冠 100 56 75 56
張一 100 78 34 45
吳玉 100 69 85 87
於一 66 45 88 99
===========修改行索引為5的值 iloc[5]============
語文 100
數學 65
英語 99
python 99
Name: 張一, dtype: int64
=======修改索引為[3:5]的行的數據 iloc[3:5]========
語文 數學 英語 python
趙六 100 100 100 100
王冠 100 100 100 100
=============將python成績乘以0.7=============
語文 數學 英語 python
張三 70.0 93 90 78
李四 70.0 89 80 54
王五 70.0 80 70 89
趙六 70.0 100 100 100
王冠 70.0 100 100 100
張一 70.0 65 99 99
吳玉 70.0 69 85 87
於一 46.2 45 88 99
==============將"吳玉"成績都加10===============
語文 數學 英語 python
張三 70.0 93.0 90.0 78.0
李四 70.0 89.0 80.0 54.0
王五 70.0 80.0 70.0 89.0
趙六 70.0 100.0 100.0 100.0
王冠 70.0 100.0 100.0 100.0
張一 70.0 65.0 99.0 99.0
吳玉 80.0 79.0 95.0 97.0
於一 46.2 45.0 88.0 99.0
9.篩選符合條件的數據
# 篩選語文低於60的成績
df1 = df[df.語文<60]
df11 = df[df['語文']<60]
print(df1,df11,sep='\n\n')
# 篩選語文和python都低於60的信息
df2 = df[(df.語文<60) & (df.python<60)]
print(df2)
運行結果:
語文 數學 英語 python
於一 46.2 45.0 88.0 99.0
語文 數學 英語 python
於一 46.2 45.0 88.0 99.0
Empty DataFrame
Columns: [語文, 數學, 英語, python]
Index: []
10.插入數據的操作方法
import pandas as pd
#利用列表生成DataFrame對象
df1 = pd.DataFrame([['張一','男',20],
['五十','男',22],
['吳下','男',18],
['劉苛玉','女',19]],
columns=['姓名','性別','年齡'])
print("在最後新增一列".center(30,'='))
print("在數據框最後加上 ‘籍貫’一列")
# 增加列的元素個數要跟原數據列的個數一樣
df1['籍貫']=['江蘇','河南','江蘇','浙江']
print(df1)
#在指定的位置增加一列 用insert()
print("在指定位置新增列:用insert()".center(30,'='))
# 如在’性別‘之後增加一列’班級‘。可以用insert的方法
# 語法格式:列表.insert(index, obj)
# index :對象 obj 需要插入的索引位置。
# obj : 要插入列表中的對象(列名)
df1.insert(2,'班級',['英才1901']*4)
print(df1)
運行結果:
===========在最後新增一列============
在數據框最後加上 ‘籍貫’一列
姓名 性別 年齡 籍貫
0 張一 男 20 江蘇
1 五十 男 22 河南
2 吳下 男 18 江蘇
3 劉苛玉 女 19 浙江
=====在指定位置新增列:用insert()=====
姓名 性別 班級 年齡 籍貫
0 張一 男 英才1901 20 江蘇
1 五十 男 英才1901 22 河南
2 吳下 男 英才1901 18 江蘇
3 劉苛玉 女 英才1901 19 浙江
大家伙學會了嗎?記得一鍵三連哦~
三克斯~ O(∩_∩)O哈哈~