本文首先介紹一下Java虛擬機的生存周期,然後大致介紹JVM的體系結構,最後對體系結構中的各個部分進行詳細介紹。
( 首先這裡澄清兩個概念:JVM實例和JVM執行引擎實例,JVM實例對應了一個獨立運行的Java程序,而JVM執行引擎實例則對應了屬於用戶運行程序的線程;也就是JVM實例是進程級別,而執行引擎是線程級別的。)
一、 JVM的生命周期
JVM實例的誕生:當啟動一個Java程序時,一個JVM實例就產生了,任何一個擁有public static void main(String[] args)函數的class都可以作為JVM實例運行的起點,既然如此,那麼JVM如何知道是運行class A的main而不是運行class B的main呢?這就需要顯式的告訴JVM類名,也就是我們平時運行java程序命令的由來,如java classA hello world,這裡java是告訴os運行Sun java 2 SDK的Java虛擬機,而classA則指出了運行JVM所需要的類名。
JVM實例的運行:main()作為該程序初始線程的起點,任何其他線程均由該線程啟動。JVM內部有兩種線程:守護線程和非守護線程,main()屬於非守護線程,守護線程通常由JVM自己使用,Java程序也可以標明自己創建的線程是守護線程。
JVM實例的消亡:當程序中的所有非守護線程都終止時,JVM才退出;若安全管理器允許,程序也可以使用Runtime類或者System.exit()來退出。
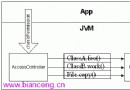
二、JVM的體系結構
粗略分來,JVM的內部體系結構分為三部分,分別是:類裝載器(ClassLoader)子系統,運行時數據區,和執行引擎。
下面將先介紹類裝載器,然後是執行引擎,最後是運行時數據區
1,類裝載器,顧名思義,就是用來裝載.class文件的。JVM的兩種類裝載器包括:啟動類裝載器和用戶自定義類裝載器,啟動類裝載器是JVM實現的一部分,用戶自定義類裝載器則是Java程序的一部分,必須是ClassLoader類的子類。(下面所述情況是針對Sun JDK1.2)
動類裝載器:只在系統類(Java API的類文件)的安裝路徑查找要裝入的類
用戶自定義類裝載器:
系統類裝載器:在JVM啟動時創建,用來在CLASSPATH目錄下查找要裝入的類
其他用戶自定義類裝載器:這裡有必要先說一下ClassLoader類的幾個方法,了解它們對於了解自定義類裝載器如何裝載.class文件至關重要。
protected final Class defineClass(String name, byte data[], int offset, int length)
protected final Class defineClass(String name, byte data[], int offset, int length, ProtectionDomain protectionDomain);
protected final Class findSystemClass(String name)
protected final void resolveClass(Class c)
defineClass用來將二進制class文件(新類型)導入到方法區,也就是這裡指的類是用戶自定義的類(也就是負責裝載類)
findSystemClass通過類型的全限定名,先通過系統類裝載器或者啟動類裝載器來裝載,並返回Class對象。
ResolveClass: 讓類裝載器進行連接動作(包括驗證,分配內存初始化,將類型中的符號引用解析為直接引用),這裡涉及到Java命名空間的問題,JVM保證被一個類裝載器裝載的類所引用的所有類都被這個類裝載器裝載,同一個類裝載器裝載的類之間可以相互訪問,但是不同類裝載器裝載的類看不見對方,從而實現了有效的屏蔽。
2, 執行引擎:它或者在執行字節碼,或者執行本地方法
要說執行引擎,就不得不的指令集,每一條指令包含一個單字節的操作碼,後面跟0個或者多個操作數。(一)指令集以棧為設計中心,而非以寄存器為中心
這種指令集設計如何滿足Java體系的要求:
平台無關性:以棧為中心使得在只有很少register的機器上實現Java更便利
compiler一般采用stack向連接優化器傳遞編譯的中間結果,若指令集以stack為基礎,則有利於運行時進行的優化工作與執行即時編譯或者自適應優化的執行引擎結合,通俗的說就是使編譯和運行用的數據結構統一,更有利於優化的開展。
網絡移動性:class文件的緊湊性。
安全性:指令集中絕大部分操作碼都指明了操作的類型。(在裝載的時候使用數據流分析期進行一次性驗證,而非在執行每條指令的時候進行驗證,有利於提高執行速度)。
(二)執行技術
主要的執行技術有:解釋,即時編譯,自適應優化、芯片級直接執行
其中解釋屬於第一代JVM,即時編譯JIT屬於第二代JVM,自適應優化(目前Sun的HotspotJVM采用這種技術)則吸取第一代JVM和第二代JVM的經驗,采用兩者結合的方式
自適應優化:開始對所有的代碼都采取解釋執行的方式,並監視代碼執行情況,然後對那些經常調用的方法啟動一個後台線程,將其編譯為本地代碼,並進行仔細優化。若方法不再頻繁使用,則取消編譯過的代碼,仍對其進行解釋執行。
3,運行時數據區:主要包括:方法區,堆,Java棧,PC寄存器,本地方法棧
(1)方法區和堆由所有線程共享
堆:存放所有程序在運行時創建的對象
方法區:當JVM的類裝載器加載.class文件,並進行解析,把解析的類型信息放入方法區。
(2)Java棧和PC寄存器由線程獨享,在新線程創建時間裡
(3)本地方法棧: 存儲本地方法調用的狀態
上邊總體介紹了運行時數據區的主要內容,下邊進行詳細介紹,要介紹數據區,就不得不說明JVM中的數據類型。
JVM中的數據類型:JVM中基本的數據單元是word,而Word的長度由JVM具體的實現者來決定
數據類型包括基本類型和引用類型,
(1) 基本類型包括:數值類型(包括除boolean外的所有的Java基本數據類型),boolean(在JVM中使用int來表示,0表示false,其他int值均表示true)和returnAddress(JVM的內部類型,用來實現finally子句)。
(2) 引用類型包括:數組類型,類類型,接口類型
前邊講述了JVM中數據的表示,下面讓我們輸入到JVM的數據區
首先來看方法區:
上邊已經提到,方法區主要用來存儲JVM從class文件中提取的類型信息,那麼類型信息是如何存儲的呢?眾所周知,Java使用的是大端序(big—endian:即低字節的數據存儲在高位內存上,如對於1234,12是高位數據,34為低位數據,則Java中的存儲格式應該為12存在內存的低地址,34存在內存的高地址,x86中的存儲格式與之相反)來存儲數據,這實際上是在class文件中數據的存儲格式,但是當數據倒入到方法區中時,JVM可以以任何方式來存儲它。
類型信息:包括class的全限定名,class的直接父類,類類型還是接口類型,類的修飾符(public,等),所有直接父接口的列表,Class對象提供了訪問這些信息的窗口(可通過Class.forName(“”)或instance.getClass()獲得),下面是Class的方法,相信大家看了會恍然大悟,(原來如此J)
getName(), getSuperClass(), isInterface(), getInterfaces(), getClassLoader();
static變量作為類型信息的一部分保存
指向ClassLoader類的引用:在動態連接時裝載該類中引用的其他類
指向Class類的引用:必然的,上邊已述
該類型的常量池:包括直接常量(String,integer和float point常量)以及對其他類型、字段和方法的符號引用(注意:這裡的常量池並不是普通意義上的存儲常量的地方,這些符號引用可能是我們在編程中所接觸到的變量),由於這些符號引用,使得常量池成為Java程序動態連接中至關重要的部分
字段信息:普通意義上的類型中聲明的字段
方法信息:類型中各個方法的信息
編譯期常量:指用final聲明或者用編譯時已知的值初始化的類變量
class將所有的常量復制至其常量池或者其字節碼流中。
方法表:一個數組,包括所有它的實例可能調用的實例方法的直接引用(包括從父類中繼承來的)
除此之外,若某個類不是抽象和本地的,還要保存方法的字節碼,操作數棧和該方法的棧幀,異常表。
舉例:
class Lava{
private int speed = 5;
void flow(){}
}
class Volcano{
public static void main(String[] args){
Lava lava = new Lava();
lava.flow();
}
}
運行命令Java Volcano;
(1) JVM找到Volcano.class倒入,並提取相應的類型信息到方法區。通過執行方法區中的字節碼,JVM執行main()方法,(執行時會一直保存指向Vocano類的常量池的指針)
(2) Main()中第一條指令告訴JVM需為列在常量池第一項的類分配內存(此處再次說明了常量池並非只存儲常量信息),然後JVM找到常量池的第一項,發現是對Lava類的符號引用,則檢查方法區,看Lava類是否裝載,結果是還未裝載,則查找“Lava.class”,將類型信息寫入方法區,並將方法區Lava類信息的指針來替換Volcano原常量池中的符號引用,即用直接引用來替換符號引用。
(3) JVM看到new關鍵字,准備為Lava分配內存,根據Volcano的常量池的第一項找到Lava在方法區的位置,並分析需要多少對空間,確定後,在堆上分配空間,並將speed變量初始為0,並將lava對象的引用壓到棧中
(4) 調用lava的flow()方法
好了,大致了解了方法區的內容後,讓我們來看看堆
Java對象的堆實現:
Java對象主要由實例變量(包括自己所屬的類和其父類聲明的)以及指向方法區中類數據的指針,指向方法表的指針,對象鎖(非必需), 等待集合(非必需),GC相關的數據(非必需)(主要視GC算法而定,如對於標記並清除算法,需要標記對象是否被引用,以及是否已調用finalize()方法)。
那麼為什麼Java對象中要有指向類數據的指針呢?我們從幾個方面來考慮
首先:當程序中將一個對象引用轉為另一個類型時,如何檢查轉換是否允許?需用到類數據
其次:動態綁定時,並不是需要引用類型,而是需要運行時類型,
這裡的迷惑是:為什麼類數據中保存的是實際類型,而非引用類型?這個問題先留下來,我想在後續的讀書筆記中應該能明白
指向方法表的指針:這裡和C++的VTBL是類似的,有利於提高方法調用的效率
對象鎖:用來實現多個線程對共享數據的互斥訪問
等待集合:用來讓多個線程為完成共同目標而協調功過。(注意Object類中的wait(),notify(),notifyAll()方法)。
Java數組的堆實現:數組也擁有一個和他們的類相關聯的Class實例,具有相同dimension和type的數組是同一個類的實例。數組類名的表示:如[[LJava/lang/Object 表示Object[][],[I表示int[],[[[B表示byte[][][]
至此,堆已大致介紹完畢,下面來介紹程序計數器和Java棧
程序計數器:為每個線程獨有,在線程啟動時創建,
若thread執行Java方法,則PC保存下一條執行指令的地址。
若thread執行native方法,則Pc的值為undefined
Java棧:java棧以幀為單位保存線程的運行狀態,Java棧只有兩種操作,幀的壓棧和出棧。
每個幀代表一個方法,Java方法有兩種返回方式,return和拋出異常,兩種方式都會導致該方法對應的幀出棧和釋放內存。
幀的組成:局部變量區(包括方法參數和局部變量,對於instance方法,還要首先保存this類型,其中方法參數按照聲明順序嚴格放置,局部變量可以任意放置),操作數棧,幀數據區(用來幫助支持常量池的解析,正常方法返回和異常處理)。
本地方法棧:依賴於本地方法的實現,如某個JVM實現的本地方法借口使用C連接模型,則本地方法棧就是C棧,可以說某線程在調用本地方法時,就進入了一個不受JVM限制的領域,也就是JVM可以利用本地方法來動態擴展本身。
好!至此,JVM的大致介紹完畢,其他關於JVM的內部實現我將陸續補充,歡迎大家和我探討問題!