自己動手寫一個搜索引擎,想想這有多 cool:在界面上輸入關鍵詞,點擊搜索,得到自己想要的結果;那麼它還可以做什麼呢?也許是自己的網站需要一個站內搜索功能,抑或是對於硬盤中文檔的搜索 —— 最重要的是,是不是覺得眾多 IT 公司都在向你招手呢?如果你心動了,那麼,Let's Go!
這裡首先要說明使用 Java 語言而不是 C/C++ 等其它語言的原因,因為 Java 中提供了對於網絡編程眾多的基礎包和類,比如 URL 類、InetAddress 類、正則表達式,這為我們的搜索引擎實現提供了良好的基礎,使我們可以專注於搜索引擎本身的實現,而不需要因為這些基礎類的實現而分心。
這個分三部分的系列將逐步說明如何設計和實現一個搜索引擎。在第一部分中,您將首先學習搜索引擎的工作原理,同時了解其體系結構,之後將講解如何實現搜索引擎的第一部分,網絡爬蟲模塊,即完成網頁搜集功能。在系列的第二部分中,將介紹預處理模塊,即如何處理收集來的網頁,整理、分詞以及索引的建立都在這部分之中。在系列的第三部分中,將介紹信息查詢服務的實現,主要是查詢界面的建立、查詢結果的返回以及快照的實現。
dySE 的整體結構
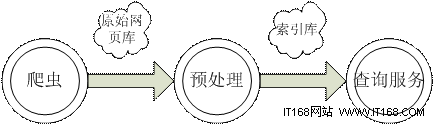
在開始學習搜索引擎的模塊實現之前,您需要了解 dySE 的整體結構以及數據傳輸的流程。事實上,搜索引擎的三個部分是相互獨立的,三個部分分別工作,主要的關系體現在前一部分得到的數據結果為後一部分提供原始數據。三者的關系如下圖所示:
圖 1. 搜索引擎三段式工作流程
在介紹搜索引擎的整體結構之前,我們借鑒《計算機網絡——自頂向下的方法描述因特網特色》一書的敘事方法,從普通用戶使用搜索引擎的角度來介紹搜索引擎的具體工作流程。
自頂向下的方法描述搜索引擎執行過程:
用戶通過浏覽器提交查詢的詞或者短語 P,搜索引擎根據用戶的查詢返回匹配的網頁信息列表 L;
上述過程涉及到兩個問題,如何匹配用戶的查詢以及網頁信息列表從何而來,根據什麼而排序?用戶的查詢 P 經過分詞器被切割成小詞組 並被剔除停用詞 ( 的、了、啊等字 ),根據系統維護的一個倒排索引可以查詢某個詞 pi 在哪些網頁中出現過,匹配那些 都出現的網頁集即可作為初始結果,更進一步,返回的初始網頁集通過計算與查詢詞的相關度從而得到網頁排名,即 Page Rank,按照網頁的排名順序即可得到最終的網頁列表;
假設分詞器和網頁排名的計算公式都是既定的,那麼倒排索引以及原始網頁集從何而來?原始網頁集在之前的數據流程的介紹中,可以得知是由爬蟲 spider 爬取網頁並且保存在本地的,而倒排索引,即詞組到網頁的映射表是建立在正排索引的基礎上的,後者是分析了網頁的內容並對其內容進行分詞後,得到的網頁到詞組的映射表,將正排索引倒置即可得到倒排索引;
網頁的分析具體做什麼呢?由於爬蟲收集來的原始網頁中包含很多信息,比如 Html 表單以及一些垃圾信息比如廣告,網頁分析去除這些信息,並抽取其中的正文信息作為後續的基礎數據。
在有了上述的分析之後,我們可以得到搜索引擎的整體結構如下圖:
圖 2. 搜索引擎整體結構
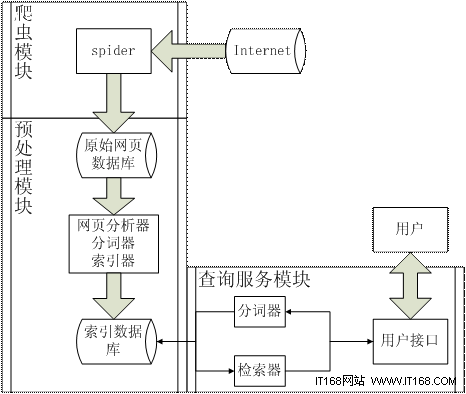
爬蟲從 Internet 中爬取眾多的網頁作為原始網頁庫存儲於本地,然後網頁分析器抽取網頁中的主題內容交給分詞器進行分詞,得到的結果用索引器建立正排和倒排索引,這樣就得到了索引數據庫,用戶查詢時,在通過分詞器切割輸入的查詢詞組並通過檢索器在索引數據庫中進行查詢,得到的結果返回給用戶。
無論搜索引擎的規模大小,其主要結構都是由這幾部分構成的,並沒有大的差別,搜索引擎的好壞主要是決定於各部分的內部實現。
有了上述的對與搜索引擎的整體了解,我們來學習 dySE 中爬蟲模塊的具體設計和實現。
Spider 的設計
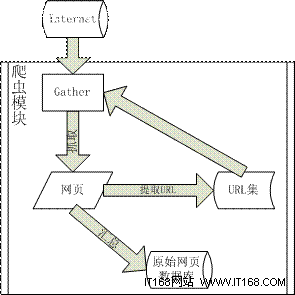
網頁收集的過程如同圖的遍歷,其中網頁就作為圖中的節點,而網頁中的超鏈接則作為圖中的邊,通過某網頁的超鏈接 得到其他網頁的地址,從而可以進一步的進行網頁收集;圖的遍歷分為廣度優先和深度優先兩種方法,網頁的收集過程也是如此。綜上,Spider 收集網頁的過程如下:從初始 URL 集合獲得目標網頁地址,通過網絡連接接收網頁數據,將獲得的網頁數據添加到網頁庫中並且分析該網頁中的其他 URL 鏈接,放入未訪問 URL 集合用於網頁收集。下圖表示了這個過程:
圖 3. Spider 工作流程
Spider 的具體實現
網頁收集器 Gather
網頁收集器通過一個 URL 來獲取該 URL 對應的網頁數據,其實現主要是利用 Java 中的 URLConnection 類來打開 URL 對應頁面的網絡連接,然後通過 I/O 流讀取其中的數據,BufferedReader 提供讀取數據的緩沖區提高數據讀取的效率以及其下定義的 readLine() 行讀取函數。代碼如下 ( 省略了異常處理部分 ):
清單 1. 網頁數據抓取
使用 Java 語言的好處是不需要自己處理底層的連接操作,喜歡或者精通 Java 網絡編程的讀者也可以不用上述的方法,自己實現 URL 類及相關操作,這也是一種很好的鍛煉。
網頁處理
收集到的單個網頁,需要進行兩種不同的處理,一種是放入網頁庫,作為後續處理的原始數據;另一種是被分析之後,抽取其中的 URL 連接,放入 URL 池等待對應網頁的收集。
網頁的保存需要按照一定的格式,以便以後數據的批量處理。這裡介紹一種存儲數據格式,該格式從北大天網的存儲格式簡化而來:
網頁庫由若干記錄組成,每個記錄包含一條網頁數據信息,記錄的存放為順序添加;
一條記錄由數據頭、數據、空行組成,順序為:頭部 + 空行 + 數據 + 空行;
頭部由若干屬性組成,有:版本號,日期,IP 地址,數據長度,按照屬性名和屬性值的方式排列,中間加冒號,每個屬性占用一行;
數據即為網頁數據。
需要說明的是,添加數據收集日期的原因,由於許多網站的內容都是動態變化的,比如一些大型門戶網站的首頁內容,這就意味著如果不是當天爬取的網頁數據,很可能發生數據過期的問題,所以需要添加日期信息加以識別。
URL 的提取分為兩步,第一步是 URL 識別,第二步再進行 URL 的整理,分兩步走主要是因為有些網站的鏈接是采用相對路徑,如果不整理會產生錯誤。URL 的識別主要是通過正則表達式來匹配,過程首先設定一個字符串作為匹配的字符串模式,然後在 Pattern 中編譯後即可使用 Matcher 類來進行相應字符串的匹配。實現代碼如下:
清單 2. URL 識別
按照“<[a|A]\\s+href=([^>]*\\s*>)”這個正則表達式可以匹配出 URL 所在的整個標簽,形如“”,所以在循環獲得整個標簽之後,需要進一步提取出真正的 URL,我們可以通過截取標簽中前兩個引號中間的內容來獲得這段內容。如此之後,我們可以得到一個初步的屬於該網頁的 URL 集合。
接下來我們進行第二步操作,URL 的整理,即對之前獲得的整個頁面中 URL 集合進行篩選和整合。整合主要是針對網頁地址是相對鏈接的部分,由於我們可以很容易的獲得當前網頁的 URL,所以,相對鏈接只需要在當前網頁的 URL 上添加相對鏈接的字段即可組成完整的 URL,從而完成整合。另一方面,在頁面中包含的全面 URL 中,有一些網頁比如廣告網頁是我們不想爬取的,或者不重要的,這裡我們主要針對於頁面中的廣告進行一個簡單處理。一般網站的廣告連接都有相應的顯示表達,比如連接中含有“ad”等表達時,可以將該鏈接的優先級降低,這樣就可以一定程度的避免廣告鏈接的爬取。
經過這兩步操作時候,可以把該網頁的收集到的 URL 放入 URL 池中,接下來我們處理爬蟲的 URL 的派分問題。
Dispatcher分配器
分配器管理 URL,負責保存著 URL 池並且在 Gather 取得某一個網頁之後派分新的 URL,還要避免網頁的重復收集。分配器采用設計模式中的單例模式編碼,負責提供給 Gather 新的 URL,因為涉及到之後的多線程改寫,所以單例模式顯得尤為重要。
重復收集是指物理上存在的一個網頁,在沒有更新的前提下,被 Gather 重復訪問,造成資源的浪費,主要原因是沒有清楚的記錄已經訪問的 URL 而無法辨別。所以,Dispatcher 維護兩個列表 ,“已訪問表”,和“未訪問表”。每個 URL 對應的頁面被抓取之後,該 URL 放入已訪問表中,而從該頁面提取出來的 URL 則放入未訪問表中;當 Gather 向 Dispatcher 請求 URL 的時候,先驗證該 URL 是否在已訪問表中,然後再給 Gather 進行作業。
Spider 啟動多個 Gather 線程
現在 Internet 中的網頁數量數以億計,而單獨的一個 Gather 來進行網頁收集顯然效率不足,所以我們需要利用多線程的方法來提高效率。Gather 的功能是收集網頁,我們可以通過 Spider 類來開啟多個 Gather 線程,從而達到多線程的目的。代碼如下:
在開啟線程之後,網頁收集器開始作業的運作,並在一個作業完成之後,向 Dispatcher 申請下一個作業,因為有了多線程的 Gather,為了避免線程不安全,需要對 Dispatcher 進行互斥訪問,在其函數之中添加 synchronized 關鍵詞,從而達到線程的安全訪問。
小結
Spider 是整個搜索引擎的基礎,為後續的操作提供原始網頁資料,所以了解 Spider 的編寫以及網頁庫的組成結構為後續預處理模塊打下基礎。同時 Spider 稍加修改之後也可以單獨用於某類具體信息的搜集,比如某個網站的圖片爬取等。