前面已經介紹了ivy主要的術語和概念,現在是時候說明ivy如何工作的了。
不同位置下模塊的通常周期
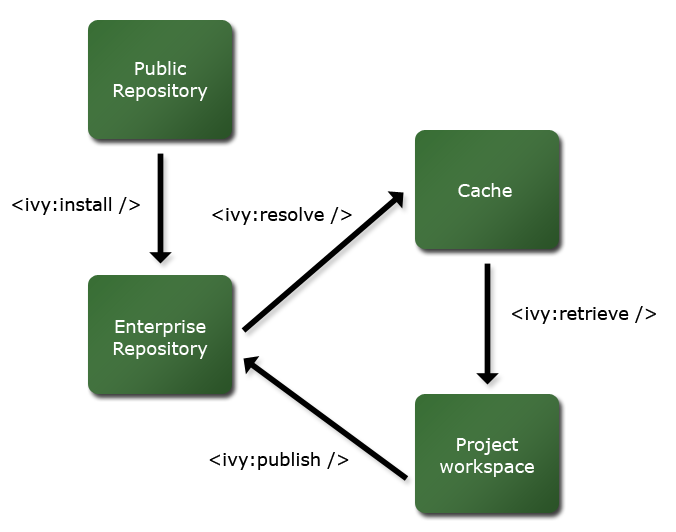
更多細節請查考ant任務。
一. 配置
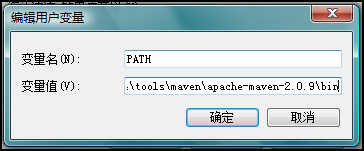
ivy需要配置以便能夠解析依賴。這個配置通常是通過配置文件來完成的,配置文件定義了一系列的依賴解析器。每個解析器能夠發現 ivy文件和/或制品,提供簡單信息諸如組織,模塊,修訂版本,制品名字,制品類型和制品擴展名。
配置通常負責支出哪個解析器應該用於解析哪個模塊。這個配置僅僅取決於你的環境,例如,在哪裡可以找到模塊和制品。
當沒有給出任何配置時將使用默認配置。這個配置實用ivyrep來解析所有模塊。
二. 解析
解析的時間是當ivy實際解析一個模塊的依賴的時刻。它第一次需要訪問模塊的ivy文件來解析依賴。
然後,在這個文件中定義的每個依賴,它將請求適當的解析器(根據配置)來查找模塊(例如,可能是一個ivy文件,或者如果沒有找到 ivy文件則是它的制品)。它同樣使用基於緩存的文件系統以避免請求一個已經存在在緩存中的依賴。
如果解析器是組合而成的(例如鏈式或者雙重解析器),為了查找模塊可能實際調用多個解析器。
當找到依賴模塊,它的ivy文件被下載到ivy緩存。然後ivy檢查它是否有它自己的依賴,在這種情況下循環游歷依賴圖。
在整個游歷過程中,盡可能快的進行沖突管理來阻止對模塊的訪問。
當ivy游歷完整個圖形,它請求解析器去下載每個依賴相應的不在緩存中並且不被沖突管理器排斥的制品。所有的下載都將加入到ivy緩 存中。
最後,在緩存中將生成一個xml報告,讓ivy可以容易的得知模塊有哪些依賴而不必在此游歷整個圖型。
在這個解析步驟之後,可能有兩個主要步驟:要不創建一個帶有緩存中制品的路徑,要不復制他們到另外一個目錄結構。
三. 獲取
在ivy中被稱為獲取的是從緩存中復制制品到另外的目錄結構的行為。這個行為是通過使用模式來實現,模式為ivy指明這些文件可以從 哪裡復制。
為此,ivy使用緩存中它將獲取的模塊對應的xml報告來獲知哪些制品應該被復制。
為了達到最佳性能它也檢查文件是否沒有被復制。
四. 從緩存中生成路徑
在某些情況下,直接使用緩存中的制品更加合適。ivy能夠使用在解析時生成的xml報告來生成一個包含所有需要的制品的路徑。
當為IDE生成插件時這個方式特別有效。
五. 報告
ivy也可以生成方便閱讀的依賴解析的報告描述。
這個是通過使用一個簡單的xsl轉換在解析時生成的xml報告來實現的。
六. 發布
最後,ivy可以被用於發布一個模塊的特別的修訂版本,以便這個版本在未來的解析中可以得到。這個任務通常被手工或者被一個持續 集成服務器調用。