引言
很多人在使用搜索引擎的時候,會出於各種原因,拼錯想要搜索的關鍵字,比如鍵盤有問題(某個按 鍵壞了)、不熟悉國際名稱(弗洛伊德的全名 Sigmund Freud)、不小心寫錯字母(Sinpsons)或多寫了 一個字母(Frusciaante)。許多用戶都很熟悉Google搜索引擎攜帶的“您是不是要找”功能。這個功能 在檢測到搜索關鍵字有可能拼寫錯了的時候會提供一些備選建議。
文本搜索在電子商務網站等各類應用中都很常見。電子商務網站通常提供文本搜索功能,用戶因此可 以自行查找符合關鍵字的產品目錄。一旦用戶拼錯關鍵字,很可能就直接導致銷售損失。舉例來說,假如 你運營一個銷售DVD的在線商店。阿諾德·施瓦辛格(Arnold Schwarzenegger)的影迷想在你的網店購買 施瓦辛格主演的所有DVD。他首先做的就是在搜索欄鍵入施瓦辛格的名字,可是如果他把名字拼錯了,拼 成了“Arnold Swuazeneger”,假如你的網店沒有返回任何相關的結果,那他就會去另一家網店購買。
解決這個問題的其中一個方案就是利用內置的領域知識來實現“您是不是要找”的功能,向用戶提供 “您是不是要找Arnold Schwarzenegger”的建議。本文將要探討的就是如何用Java來實現這個功能。
編輯距離算法
在信息論和計算機科學領域,兩個字符串之間的編輯距離是指將其中一個字符串用另一個字符來替換 所需要的操作次數。定義編輯距離的方式有好幾種,使用這些定 義計算編輯距離值的算法也有很多。主 要的算法有Levenshtein、Jaro-Winkler和n-gram。Jaro-Winkler是Jaro距離度量的一個延伸,主要應用 於記錄連接領域(重復檢測)。Levenshtein算法中,兩個字符串之間的距離定 義為將一個字符串轉換為 另一字符串所需的最少編輯次數,允許的編輯操作有插入、刪除、單個字符的替換。該算法由Vladimir Levenshtein在1965年提出,並以作者名來命名。n-gram是一個概率模型,按順序預測下一個編輯項,這 一模型廣泛用於統計自然 語言處理和基因序列分析的各個領域。
本文並非要研究如何從頭實現這些算法,我們要關注的是如何借助Apache Lucene中已有的實現—— SpellChecker項目來應用這些算法。
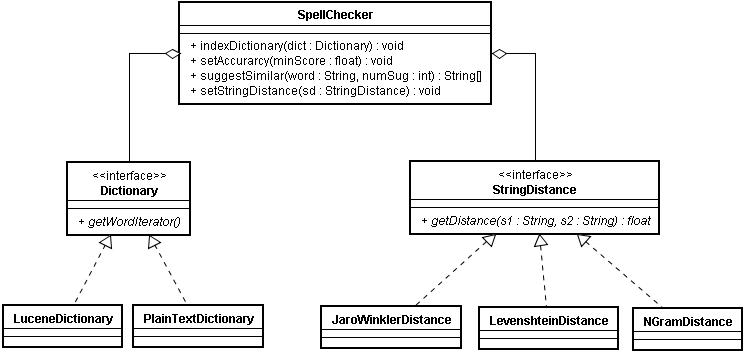
簡單來說,Lucene SpellChecker實現包括主類SpellChecker,主類SpellChecker用到了Directory、 Dictionary、以及三個StringDistance算法之一。SpellChecker類使用策略模式(GoF)選擇 StringDistance算法,內置的StringDistance算法實現有JaroWinklerDistance、 LevenshteinDistance 、NGramDistance,缺省為LevenshteinDistance。你還可以調整精度,精度的取值范圍在0到1之間,缺省 為0.5。精度的設置對結果有很大影響,也許你會覺得精度應當設置得比缺省值要高一些,但也許你會發 現設置得過高時算法卻不會返回任何結果。拿我的詞典來說,精度取0.749時得到的結果最好。 Dictionary接口有兩個直接實現,你也可以編寫自己的實現。
對我們的“您是不是要找”實現來說,我們在詞典中搜索關鍵字的子集,根據選定的字符串距離算法 查找“相近”的關鍵字,而且距離要與預先設置的精度相匹配。圖1是Lucene SpellChecker的類圖概覽。
示例
下面是一個簡單的代碼示例。運行這個例子需要Java 5或更新版本、lucene-core-3.0.0.jar、 lucene-spellchecker-3.0.0.jar,以及一個名為 dictionary.txt的平面文件(一行一個關鍵字的簡單文 本文件,後面有一個例子)。
//創建詞典
//實例化拼寫檢查器
final SpellChecker sp = new SpellChecker(directory);
//對詞典進行索引
sp.indexDictionary(new PlainTextDictionary(new File("dictionary.txt")));
//“錯誤”的搜索
String search = "Arnold Swuazeneger";
//建議個數
final int suggestionNumber = 5;
//獲取建議的關鍵字
String[] suggestions = sp.suggestSimilar(search, suggestionNumber);
//顯示結果
System.out.println("Your Term:" + search);
for (String word : suggestions) {
System.out.println("Did you mean:" + word);
}
//再創建一個拼寫錯誤的搜索
search = "bava";
suggestions = sp.suggestSimilar(search, suggestionNumber);
System.out.println("Your Term:" + search);
for (String word : suggestions) {
System.out.println("Did you mean:" + word);
}
給定的dictionary.txt文件如下所示:
Seth MacFarlane
Arnold Schwarzenegger
Scarlett Johansson
Rodrigo Santoro
java
lava
bullet
程序的輸出為:
Your Term: arnold swuazeneger
Did you mean: Arnold Schwarzenegger
Your Term: bava
Did you mean: java
Did you mean: lava
Did you mean: bullet
Benchmarking測試
為了對性能有所了解,我們在具備以下配置的機器上將示例運行了十五次,取其平均值:
操作系統:Windows XP Professional SP3
處理器:Intel Core 2 Duo E6550 @2.33GHz
內存:1.96GB
測試
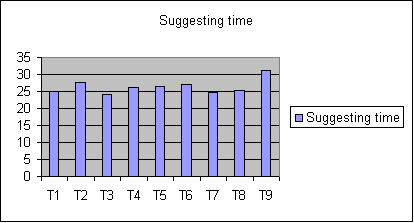
測試編號 關鍵字長度 詞典大小 精度 算法 索引時間 獲得建議的時間 T1 17 5 0,5 Levenshtein 73,0136214 25,036049 T2 17 81000 0,5 Levenshtein 3402,293693 27,7293112 T3 17 5 0,5 JaroWinkler 69,53269 24,232477 T4 17 81000 0,5 JaroWinkler 3356,016059 26,287849 T5 17 81000 0,5 NGram 3353,633583 26,580123 T6 17 81000 0,9 Levenshtein 3325,310027 26,96378 T7 17 81000 0,3 Levenshtein 3408,072786 24,723142 T8 4 81000 0,67 Levenshtein 3328,584784 25,363586 T9 28 81000 0,67 Levenshtein 3354,5943 31,284672圖表
其中:
關鍵字長度是關鍵字包含的字母個數。
詞典大小是文件行數。
精度由setAccuracy方法設置。
根據測試結果,我們可以得出這樣的結論:精度對時間的影響不大,關鍵字長度對時間卻有很大影響 ——包含四個字符的關鍵字大約2ms就能獲得結果。測試的三種算法中,NGramDistance略快於另外兩個。 在測試中我還發現,JaroWinkler距離算法所得到的准確結果最少。
結論
正如你看到的,利用已有的算法使得“您是不是要找”的實現細節出奇的簡單。但在現實場景中,要 創建支持應用、適用於領域特定關鍵字的詞典則需要花費更多的力氣。