當並發用戶數明顯的開始增長,你可能會不滿意一台機器所能提供的性能,或 者由於單個JVM實例gc的限制,你沒法擴展你的java應用,在這樣的情況下你可以 做的另外的選擇是在多個JVM實例或多台服務器上運行你的系統,我們把這種方法 稱為水平擴展。
請注意,我們相信能夠在一台機器的多個JVM上運行系統的擴展方式是水平擴 展方式,而非垂直擴展方式。JVM實例之間的IPC機制是有限的,兩個JVM實例之間 無法通過管道、共享內存、信號量或指令來進行通訊,不同的JVM進程之間最有效 的通訊方式是socket。簡而言之,如果Java EE應用如果擴展到多個JVM實例中運 行,那麼大多數情況下它也可以擴展到多台服務器上運行。
隨著計算機越來越便宜,性能越來越高,通過將低成本的機器群組裝為集群可 以獲得超過那些昂貴的超級計算機所具備的計算能力。不過,大量的計算機也意 味著增加了管理的復雜性以及更為復雜的編程模型,就像服務器節點之間的吞吐 量和延時等問題。
Java EE集群是一種成熟的技術,我在TSS上寫了一篇名為“Uncover the Hood of J2EE Clustering”的文章來描述它的內部機制。
從失敗的項目中吸取的教訓
采用無共享的集群架構(SNA)
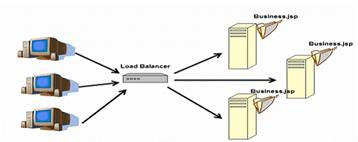
Figure 3: share nothing cluster
最具備擴展性的架構當屬無共享的集群架構。在這樣的集群中,每個節點具備 完全相同的功能,並且不需要知道其他節點存在與否。負載均衡器(Load Balancer)來完成如何將請求分發給這些後台的服務器實例。由於負載均衡器只是 做一些簡單的工作,例如分派請求、健康檢查和保持session,因此負載均衡器很 少會成為瓶頸。如果後端的數據庫系統或其他的信息系統足夠的強大,那麼通過 增加更多的節點,集群的計算能力可以得到線性的增長。
幾乎所有的Java EE提供商在他們的集群產品中都實現了HttpSession的 failover功能,這樣即使在某些服務器節點不可用的情況下也仍然能夠保證客戶 端的請求中的session信息不丟失,但這點其實是打破了無共享原則的。為了實現 failover,同樣的session數據將會被兩個或多個節點共享,在我之前的文章中, 我曾經推薦除非是萬不得已,不要使用session failover。就像我文章中提到的 ,當失敗發生時,session failover功能並不能完全避免錯誤,而且同時還會對 性能和可擴展性帶來損失。
使用可擴展的session復制機制
為了讓用戶獲得更友好的體驗,有些時候可能必須使用session failover功能 ,這裡最重要的在於選擇可擴展的復制型產品或機制。不同的廠商會提供不同的 復制方案 - 有些采用數據庫持久,有些采用中央集中的狀態服務器,而有些則采 用節點間內存復制的方式。最具可擴展性的是成對節點的復制(paired node replication),這也是現在大部分廠商采用的方案,包括BEA Weblogic、JBoss和 IBM Websphere,Sun在Glassfish V2以及以上版本也實現了成對節點的復制。最 不可取的方案是數據庫持久session的方式。在我們實驗室中曾經測試過一個采用 數據庫持久來實現 session復制的項目,測試結果表明如果session對象頻繁更新 的話,節點在三到四個時就會導致數據庫崩潰。
采用collocated部署方式來取代分布式
Java EE技術,尤其是EJB,天生就是用來做分布式計算的。解耦業務功能和重 用遠程的組件使得多層的應用模型得以流行。但對於可擴展性而言,減少分布式 的層次可能是一個好的選擇。
在我們實驗室曾經以一個政府的項目測試過這兩種方式在同樣的服務器數量上 的部署 - 一種是分布式的,一種是collocated方式的,如下圖所示:
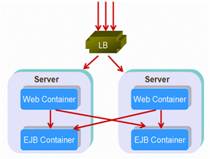
Figure 4: distributed structure
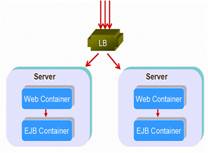
Figure 5: collocated structure
結果表明collocated式的部署方式比分布式的方式更具備可擴展性。假設你應 用中的一個方法調用了一堆的EJB,如果每個EJB的調用都需要load balance,那 麼有可能會因為需要分散到不同的服務器上進行調用導致你的應用崩潰,這樣的 結果就是,你可能做了很多次無謂的跨服務器的調用。來看更糟糕的情況,如果 你的方法是需要事務的,那麼這個事務就必須跨越多個服務器,而這對於性能是 會產生很大的損害的。
共享資源和服務
對於用於支撐並發請求的Java EE集群系統而言,其擴展後的性能取決於對於 那些不支持線性擴展的共享資源的操作。數據庫服務器、JNDI樹、LDAP服務器以 及外部的文件系統都有可能被集群中的節點共享。
盡管Java EE規范中並不推薦,但為了實現各種目標,通常都會采用外部的I/O 操作。例如,在我們實驗室測試的應用中有用文件系統來保存用戶上傳的文件的 應用,或動態的創建xml配置文件的應用。在集群內,應用服務器節點必須想辦法 來復制這些文件到其他的節點,但這樣做是不利於擴展的。隨著越來越多節點的 加入,節點間的文件復制會占用所有的網絡帶寬和消耗大量的CPU資源。在集群中 要達到這樣的目標,可以采用數據庫來替代外部文件,或采用SAN作為文件的集中 存儲,另外一個可選的方案是采用高效的分布式文件系統,例如Hadoop DFS (http://wiki.apache.org/hadoop/)。
在集群環境中共享服務很常見,這些服務不會部署到集群的每個節點,而是部 署在專門的服務器節點上,例如分布式的日志服務或時間服務。分布式鎖管理器 (DLM)來管理集群中的應用對這些共享服務的同步訪問,即使在網絡延時和系統處 理失敗的情況下,鎖管理器也必須正常操作。舉例來說,在我們的實驗室中測試 的一個ERP系統就碰到了這樣的問題,他們寫了自己的DLM系統,最終發現當集群 中持有鎖的節點失敗時,他們的lock system將會永遠的持有鎖。
分布式緩存
我所碰到過的幾乎所有的Java EE項目都采用了對象緩存來提升性能,同樣所 有流行的應用服務器也都提供了不同級別的緩存來加速應用。但有些緩存是為單 一運行的環境而設計的,並且只能在單JVM實例中正常的運行。由於有些對象的創 建需要耗費大量的資源,我們需要緩存,因此我們維護對象池來緩存對象的實例 。如果獲取維護緩存較之創建對象而言更劃算,那麼我們就提升了系統的性能。 在集群環境中,每個jvm實例維護著自己的緩存,為了保持集群中所有服務器狀態 的一致,這些緩存對象需要進行同步。有些時候這樣的同步機制有可能會比不采 用緩存的性能還差,對於整個集群的擴展能力而言,一個可擴展的分布式緩存系 統是非常重要的。
如今很多分布式緩存相關的開源java產品已經非常流行,在我們實驗室中有如 下的一些測試:
1個基於JBoss Cache的項目的測試;
3個基於Terracotta的項目的測試;
9個基於memcached的項目的測試;
測試結果表明Terracotta可以很好的擴展到10個節點,並且在不超過5個節點 時擁有很高的性能,但memcached則在超過20個服務器節點時會擴展的非常好。
Memcached
Memcached是一個高性能的分布式對象緩存系統,經常被用於降低數據庫load ,同時提升動態web應用的速度。Memcached的奇妙之處在於它的兩階段hash的方 法,它通過一個巨大的hash表來查找key = value對,給它一個key,就可以set或 get數據了。當進行一次memcached查詢時,首先客戶端將會根據整個服務器的列 表來對key進行 hash,在找到一台服務器後,客戶端就發送請求,服務器端在接 收到請求後通過對key再做一次內部的hash,從而查找到實際的數據項。當處理巨 大的系統時,最大的好處就是memcached所具備的良好的水平擴展能力。由於客戶 端做了一層hashing,這使得增加N多的節點到集群變得非常的容易,並不會因為 節點的互連造成負載的增高,也不會因為多播協議而造成網絡的洪水效應。
實際上Memcached並不是一款java產品,但它提供了Java client API,這也就 意味著如果你需要在Java EE應用中使用memcached的話,並不需要做多大的改動 就可以從cache中通過get獲取值,或通過put將值放入cache中。使用 memcached 是非常簡單的,不過同時也得注意一些事情避免對擴展性和性能造成損失:
不要緩存寫頻繁的對象。Memcached是用來減少對數據庫的讀操作的,而非寫 操作,在使用Memcached前,應先關注對象的讀/寫比率,如果這個比率比較高, 那麼采用緩存才有意義。
盡量避免讓運行的memcached的節點互相調用,對於memcached而言這是災難性 的。
盡量避免行方式的緩存,在這樣的情況下可采用復雜的對象來進行緩存,這對 於memcached來說會更為有效。
選 擇合適的hashing算法。在默認的算法下,增加或減少服務器會導致所有的 cache全部失效。由於服務器的列表hash值被改變,可能會造成大部分的 key都要 hash到和之前不同的服務器上去,這種情況下,可以考慮采用持續的hashing算法 (http://weblogs.java.net /blog/tomwhite/archive/2007/11/consistent_hash.html) 來增加和減少服務器 ,這樣做可以保證你大部分緩存的對象仍然是有效的。
Terracotta
Terracotta(http://www.terracottatech.com/)是一個企業級的、開源的、 JVM級別的集群解決方案。JVM級的集群方案意味著可以支撐將企業級的Java應用 部署部署到多JVM上,而且就像是運行在同一個JVM中。 Terracotta擴展了JVM的 內存模型,各虛擬機上的線程通過集群來與其他虛擬機上的線程進行交互 (Terracotta extends the Java Memory Model of a single JVM to include a cluster of virtual machines such that threads on one virtual machine can interact with threads on another virtual machine as if they were all on the same virtual machine with an unlimited amount of heap.)。
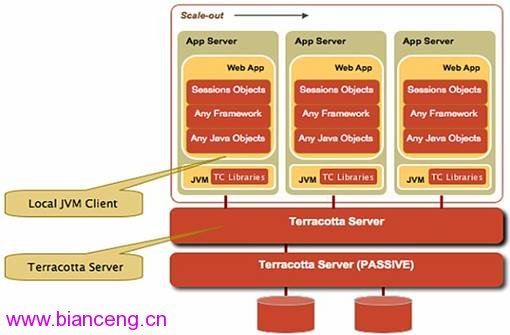
Figure 6: Terracotta JVM clustering
采用Terracotta來實現集群應用的編程方式和編寫單機應用基本沒有什麼差別 ,Terrocotta並沒有特別的提供開發者的API,Terracotta采用字節碼織入的方式 (很多AOP軟件開發框架中采用的技術,例如AspectJ和AspectWerkz)來將集群方 式的代碼插入到已有的java語言中。
我猜想Terrocotta是通過某種互連的方式或多播協議的方式來實現服務器和客 戶端JVM實例的通訊的,可能是這個原因導致了在我們實驗室測試時的效果:當超 過20個節點時Terracotta擴展的並不是很好。(注:這個測試結果僅為在我們實 驗室的測試結果,你的結果可能會不同。)
並行處理
我之前說過,單線程的任務會成為系統可擴展性的瓶頸。但有些單線程的工作 (例如處理或生成巨大的數據集)不僅需要多線程或多進程的運行,還會有擴展 到多節點運行的需求。例如,在我們實驗室測試的一個Java EE項目有一個場景是 這樣的:根據他們站點的日志文件分析URL的訪問規則,每周產生的這些日志文件 通常會超過120GB,當采用單線程的Java應用去分析時需要耗費四個小時,客戶改 為采用Hadoop Map-Reduce使其能夠水平擴展從而解決了這個問題,如今這個分析 URL訪問規則的程序不僅運行在多進程模式下,同時還並行的在超過10個節點上運 行,而完成所有的工作也只需要7分鐘了。
有很多的框架和工具可以幫助Java EE開發人員來讓應用支持水平擴展。除了 Hadoop,很多MPI的Java實現也可以用來將單線程的任務水平的擴展到多個節點上 並行運行。
MapReduce
MapReduce由Google的Jeffrey Dean和Sanjay Ghemawat提出,是一種用於在大 型集群環境下處理巨量數據的分布式編程模型。MapReduce由兩個步驟來實現 - Map:對集合中所有的對象進行操作並基於處理返回一系列的結果,Reduce:通過 多線程、進程或獨立系統並行的從兩個或多個Map中整理和獲取結果。Map()和 Reduce()都是可以並行運行的,不過通常來說沒必要在同樣的系統同樣的時間這 麼來做。
Hadoop是一個開源的、點對點的、純Java實現的MapReduce。它是一個用於將 分布式應用部署到大型廉價集群上運行的Lucene-derived框架,得到了全世界范 圍開源人士的支持以及廣泛的應用,Yahoo的Search Webmap、Amazon EC2/S3服務 以及Sun的網格引擎都可運行在Hadoop上。
簡單來說,通過使用“Hadoop Map-Reduce”,"URL訪問規則分析"程序可以首 先將日志文件分解為多個128M的小文件,然後由Hadoop將這些小文件分配到不同 的Map()上去執行。Map()會分析分配給它的小文件並產生臨時的結果,Map()產生 的所有的臨時結果會被排序並分配給不同的Reduce(),Reduce()合並所有的臨時 結果產生最終的結果,這些Map和Reduce操作都可以由Hadoop框架控制來並行的運 行在集群中所有的節點上。
MapReduce對於很多應用而言都是非常有用的,包括分布式檢索、分布式排序 、web link-graph reversal、term-vector per host、web訪問日志分析、索引 重建、文檔集群、機器智能學習、statistical machine translation和其他領域 。
MPI
MPI是一種語言無關、用於實現並行運行計算機間交互的通訊協議,目前已經 有很多Java版本的MPI標准的實現,mpiJava和MPJ是其中的典型。mpiJava 基於 JNI綁定native的MPI庫來實現,MPJ是100%純java的MPI標准的實現。mpiJava和 MPJ和MPI Fortran和C版本提供的API都基本一致,例如它們都對外提供了具備同 樣方法名和參數的Comm class來實現MPI的信息傳遞。
CCJ是一個類似MPI通訊操作的java庫。CCJ提供了barrier、broadcast、 scatter、 gather、all-gather、reduce和all-reduce操作的支持(但不提供點 對點的操作,例如send、receive和send- receive)。在底層的通訊協議方面, CCJ並沒有自己實現,而是采用了Java RMI,這也就使得CCJ可以用來傳遞復雜的 序列化對象,而不僅僅是MPI中的原始數據類型。進一步看,CCJ還可以從一組並 行的processes中獲取到復雜的集合對象,例如實現了CCJ的DividableDataObject 接口的集合。
采用不同的方法來獲取高擴展能力
有很多的書會教我們如何以OO的方式來設計靈活架構的系統,如何來使服務透 明的被客戶端使用以便維護,如何采用正常的模式來設計數據庫schema以便集成 。但有些時候為了獲取高擴展性,需要采用一些不同的方法。
Google設計了自己的高可擴展的分布式文件系統(GFS),它並不是基於POSIX API來實現的,不過GFS對於用戶來說並不完全透明。為了使用GFS,你必須采用 GFS的API包。Google也設計了自己的高可擴展的分布式數據庫系統(Bigtable) ,但它並不遵循ANSI SQL標准,而且其中的概念和結構和傳統的關系數據庫幾乎 完全不同,但最重要的是GFS和Bigtable能夠滿足Google的存儲要求、良好的擴展 性要求,並且已經被Google的廣泛的作為其存儲平台而使用。
傳統方式下,我們通過使用更大型的、更快和更貴的機器或企業級的集群數據 庫(例如RAC)來將數據庫擴展到多節點運行,但我有一個我們實驗室中測試的 social networking的網站采用了不同的方式,這個應用允許用戶在網站上創建 profiles、blogs,和朋友共享照片和音樂,此應用基於Java EE編寫,運行在 Tomcat和Mysql上,但不同於我們實驗室中測試的其他應用,它只是希望在20多台 便宜的PC Server上進行測試,其數據模型結構如下:
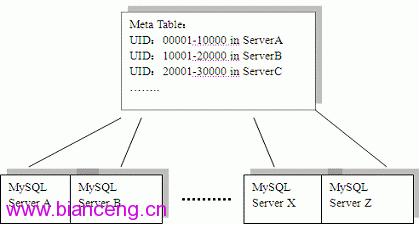
Figure 7: Users data partitions
這裡比較特殊的地方子礙於不同的用戶數據(例如profile、blog)可能會存 儲在不同的數據庫實例上,例如,用戶 00001存儲在服務器A上,而用戶20001存 儲在服務器C上,分庫的規則以一張元信息的表的方式存儲在專門的數據庫上。當 部署在Tomcat的 Java EE應用希望獲取或更新用戶信息時,首先它會從這張元信 息的表中獲取到需要去哪台服務器上獲取這個用戶,然後再連到實際的服務器上 去執行查詢或更新操作。
用戶數據分區和這種兩步時的動作方式可以帶來如下的一些好處:
擴展了寫的帶寬:對於這類應用而言,blogging、ranking和BBS將會使得寫帶 寬成為網站的主要瓶頸。分 布式的緩存對於數據庫的寫操作只能帶來很小的提升 。采用數據分區的方式,可以並行的進行寫,同樣也就意味著提升了寫的吞吐量 。要支持更多的注冊用戶,只需 要通過增加更多的數據庫節點,然後修改元信息 表來匹配到新的服務器上。
高可用性:如果一台數據庫服務器down了,那麼只會有部分用戶被影響,而其 他大部分的用戶可以仍然正常使用;
同時也會帶來一些缺點:
由於數據庫節點可以動態的增加,這對於在Tomcat中的Java EE應用而言要使 用數據庫連接池就比較難了;
由於操作用戶的數據是兩步式的,這也就意味著很難使用ORMapping的工具去 實現;
當要執行一個復雜的搜索或合並數據時,需要從多台數據庫服務器上獲取很多 不同的數據。
這個系統的架構師這麼說:“我們已經知道這些缺點,並且准備好了應對它, 我們甚至准備好了應對當元信息表的服務器成為瓶頸的狀況,如果出現那樣的狀 況我們將會把元信息表再次劃分,並創建出一個更高級別的元信息表來指向眾多 的二級元信息表服務器實例。