通常,Java I/O 框架用途極其廣泛。同一個框架支持文件存取、網絡訪問、 字符轉換、壓縮和加密等等。不過,有時它不是十分靈活。例如,壓縮流允許您 將數據寫成壓縮格式,但它們不能讓您讀取壓縮格式的數據。同樣地,某些第三 方模塊被構建成寫出數據,而沒有考慮應用程序需要讀取數據的情形。本文是兩 部分系列文章的第一部分,Java 密碼專家和作家 Merlin Hughes 介紹了使應用 程序從僅支持將數據寫至輸出流的源中有效讀取數據的框架。
自早期基於浏覽器的 applet 和簡單應用程序以來,Java 平台已有了巨大的 發展。現在,我們有多個平台和概要及許多新的 API,並且還在制作的差不多有 數百種之多。盡管 Java 語言的復雜程度在不斷增加,但它對於日常的編程任務 而言仍是一個出色的工具。雖然有時您會陷入那些日復一日的編程問題中,但偶 爾您也能夠回過頭去,發現一個很棒的解決方案來處理您以前曾多次遇到過的問 題。
就在前幾天,我想要壓縮一些通過網絡連接讀取的數據(我以壓縮格式將 TCP 數據中繼到一個 UDP 套接字)。記得 Java 平台自版本 1.1 開始就支持壓 縮,所以我直接求助於 java.util.zip 包,希望能找到一個適合於我的解決方 案。然而,我發現一個問題:構造的類都適用於常規情況,即在讀取時對數據解 壓縮而在寫入時壓縮它們,沒有其它變通方法。雖然繞過 I/O 類是可能的,但 我希望構建一個基於流的解決方案,而不想偷懶直接使用壓縮程序。
不久以前,我在另一種情況下也遇到過完全相同的問題。我有一個 base-64 轉碼庫,與使用壓縮包一樣,它支持對從流中讀取的數據進行譯碼,並對寫入流 中的數據進行編碼。然而,我需要的是一個在我從流中讀取數據的同時可以進行 編碼的庫。
在我著手解決該問題時,我認識到我在另一種情況下也遇到過該問題:當序 列化 XML 文檔時,通常會循環遍歷整個文檔,將節點寫入流中。然而,我遇到 的情況是需要讀取序列化格式的文檔,以便將子集重新解析成一個新文檔。
回過頭想一下,我意識到這些孤立事件表示了一個共性的問題:如果有一個 遞增地將數據寫入輸出流的數據源,那麼我需要一個輸入流使我能夠讀取這些數 據,每當需要更多數據時,都能透明地訪問數據源。
在本文中,我們將研究對這一問題的三種可能的解決方案,同時決定一個實 現最佳解決方案的新框架。然後,我們將針對上面列出的每個問題,檢驗該框架 。我們將扼要地談及性能方面的問題,而把對此的大量討論留到下一篇文章中。
I/O 流基礎知識
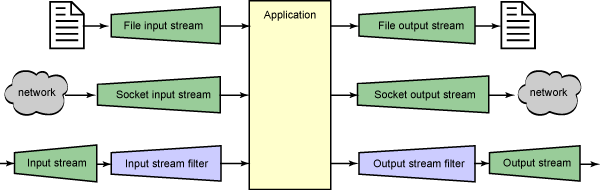
首先,讓我們簡單回顧一下 Java 平台的基本流類,如圖 1 所示。 OutputStream 表示對其寫入數據的流。通常,該流將直接連接至諸如文件或網 絡連接之類的設備,或連接至另一個輸出流(在這種情況下,它稱為 過濾器 (filter))。通常,輸出流過濾器在轉換了寫入其中的數據之後,才將轉換後 產生的數據寫入相連的流中。 InputStream 表示可以從中讀取數據的流。同樣 ,該流也直接連接至設備或其它流。輸入流過濾器從相連的流中讀取數據,轉換 該數據,然後允許從中讀取轉換後的數據。
圖 1. I/O 流基礎知識
就我最初的問題看, GZIPOutputStream 類是一個輸出流過濾器,它壓縮寫 入其中的數據,然後將該壓縮數據寫入相連的流。我需要的輸入流過濾器應該能 從流中讀取數據,壓縮數據,然後讓我讀取結果。
Java 平台,版本 1.4 已引入了一個新的 I/O 框架 java.nio 。不過,該框 架在很大程度上與提供對操作系統 I/O 資源的有效訪問有關;而且,雖然它確 實為一些傳統的 java.io 類提供了類似功能,並可以表示同時支持輸入和輸出 的雙重用途的資源,但它並不能完全替代標准流類,並且不能直接處理我需要解 決的問題。
蠻力解決方案
在著手尋找解決我問題的工程方案前,我根據標准 Java API 類的精致和有 效性,研究了基於這些類的解決方案。
該問題的蠻力解決方案就是簡單地從輸入源中讀取所有數據,然後通過轉換 程序(即,壓縮流、編碼流或 XML 序列化器)將它們推進內存緩沖區中。然後 ,我可以從該內存緩沖區中打開要讀取的流,這樣我就解決了問題。
首先,我需要一個通用的 I/O 方法。清單 1 中的方法利用一個小緩沖區將 InputStream 中的所有數據復制到 OutputStream 。當到達輸入的結尾( read () 函數的返回值小於零)時,該方法就返回,但不關閉這兩個流。
清單 1. 通用的 I/O 方法
public static void io (InputStream in, OutputStream out)
throws IOException {
byte[] buffer = new byte[8192];
int amount;
while ((amount = in.read (buffer)) >= 0)
out.write (buffer, 0, amount);
}
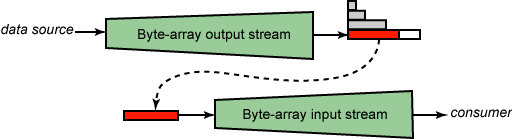
清單 2 顯示蠻力解決方案如何使我讀取壓縮格式的輸入流。我打開寫入內存 緩沖區的 GZIPOutputStream (使用 ByteArrayOutputStream )。接著,將輸 入流復制到壓縮流中,這樣將壓縮數據填入內存緩沖區中。然後,我返回 ByteArrayInputStream ,它讓我從輸入流中讀取,如圖 2 所示。
圖 2. 蠻力解決方案
清單 2. 蠻力解決方案
public static InputStream bruteForceCompress (InputStream in)
throws IOException {
ByteArrayOutputStream sink = new ByteArrayOutputStream ():
OutputStream out = new GZIPOutputStream (sink);
io (in, out);
out.close ();
byte[] buffer = sink.toByteArray ();
return new ByteArrayInputStream (buffer);
}
這個解決方案有一個明顯的缺點,它將整個壓縮文檔都存儲在內存中。如果 文檔很大,那麼這種方法將不必要地浪費系統資源。使用流的主要特性之一是它 們允許您操作比所用系統內存要大的數據:您可以在讀取數據時處理它們,或在 寫入數據時生成數據,而無需始終將所有數據保存在內存中。
從效率上,讓我們對在緩沖區之間復制數據進行更深入研究。
通過 io() 方法,將數據從輸入源讀入至一個緩沖區中。然後,將數據從緩 沖區寫入 ByteArrayOutputStream 中的緩沖區(通過我忽略的壓縮過程)。然 而, ByteArrayOutputStream 類對擴展的內部緩沖區進行操作;每當緩沖區變 滿時,就會分配一個大小是原來兩倍的新緩沖區,接著將現有的數據復制到該緩 沖區中。平均下來,這一過程每個字節復制兩次。(算術計算很簡單:當進入 ByteArrayOutputStream 時,對數據平均復制兩次;所有數據至少復制一次;有 一半數據至少復制兩次;四分之一的數據至少復制三次,依次類推。)然後,將 數據從該緩沖區復制到 ByteArrayInputStream 的一個新緩沖區中。現在,應用 程序可以讀取數據了。總之,這個解決方案將通過四個緩沖區寫數據。這對於估 計其它技術的效率是一個有用的基准。
管道式流解決方案
管道式流 PipedOutputStream 和 PipedInputStream 在 Java 虛擬機的線程 之間提供了基於流的連接。一個線程將數據寫入 PipedOutputStream 中的同時 ,另一個線程可以從相關聯的 PipedInputStream 中讀取該數據。
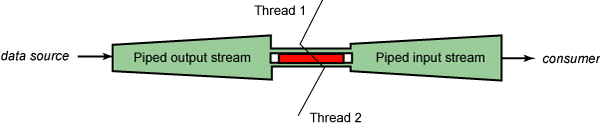
就這樣,這些類提供了一個針對我問題的解決方案。清單 3 顯示了使用一個 線程通過 GZIPOutputStream 將數據從輸入流復制到 PipedOutputStream 的代 碼。然後,相關聯的 PipedInputStream 將提供對來自另一個線程的壓縮數據的 讀取權,如圖 3 所示:
圖 3. 管道式流解決方案
清單 3. 管道式流解決方案
private static InputStream pipedCompress (final InputStream in)
throws IOException {
PipedInputStream source = new PipedInputStream ();
final OutputStream out =
new GZIPOutputStream (new PipedOutputStream (source));
new Thread () {
public void run () {
try {
Streams.io (in, out);
out.close ();
} catch (IOException ex) {
ex.printStackTrace ();
}
}
}.start ();
return source;
}
理論上,這可能是個好技術:通過使用線程(一個執行壓縮,另一個處理產 生的數據),應用程序可以從硬件 SMP(對稱多處理)或 SMT(對稱多線程)中 受益。另外,這一解決方案僅涉及兩個緩沖區寫操作:I/O 循環將數據從輸入流 讀入緩沖區,然後通過壓縮流寫入 PipedOutputStream 。接著,輸出流將數據 存儲在內部緩沖區中,與 PipedInputStream 共享緩沖區以供應用程序讀取。而 且,因為數據通過固定緩沖區流動,所以從不需要將它們完全讀入內存中。事實 上,在任何給定時刻,緩沖區都只存儲小部分的工作集。
不過,實際上,它的性能很糟糕。管道式流需要利用同步,從而引起兩個線 程之間激烈爭奪同步。它們的內部緩沖區太小,無法有效地處理大量數據或隱藏 鎖爭用。其次,持久共享緩沖區會阻礙許多簡單的高速緩存策略共享 SMP 機器 上的工作負載。最後,線程的使用使得異常處理極其困難:沒有辦法將可能出現 的任何 IOException 下推到管道中以便閱讀器處理。總之,這一解決方案太難 處理,根本不實際。
工程解決方案
現在,我們將研究另一種解決該問題的工程方案。這種解決方案提供了一個 特地為解決這類問題而設計的框架,該框架提供了對數據的 InputStream 訪問 ,這些數據是從遞增地向 OutputStream 寫入數據的源中產生的。遞增地寫入數 據這一事實很重要。如果源在單個原子操作中將所有數據都寫入 OutputStream ,而且如果不使用線程,則我們基本上又回到了蠻力技術的老路上。不過,如果 可以訪問源以遞增地寫入其數據,則我們就實現了在蠻力和管道式流解決方案之 間的良好平衡。該解決方案不僅提供了在任何時候只在內存中保存少量數據的管 道式優點,同時也提供了避免線程的蠻力技術的優點。
圖 4 演示了完整的解決方案。我們將在本文的剩余部分研究 該解決方案的 源代碼。
圖 4. 工程解決方案
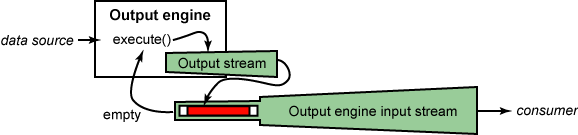
輸出引擎
清單 4 提供了一個描述數據源的接口 OutputEngine 。正如我所說的,這些 源遞增地將數據寫入輸出流:
清單 4. 輸出引擎
package org.merlin.io;
import java.io.*;
/**
* An incremental data source that writes data to an OutputStream.
*
* @author Copyright (c) 2002 Merlin Hughes <merlin@merlin.org>
*
* This program is free software; you can redistribute
* it and/or modify it under the terms of the GNU
* General Public License as published by the Free
* Software Foundation; either version 2
* of the License, or (at your option) any later version.
*/
public interface OutputEngine {
public void initialize (OutputStream out) throws IOException;
public void execute () throws IOException;
public void finish () throws IOException;
}
initialize() 方法向該引擎提供一個流,應該向這個流寫入數據。然後,重 復調用 execute() 方法將數據寫入該流中。當數據寫完時,引擎會關閉該流。 最後,當引擎應該關閉時,將調用 finish() 。這會發生在引擎關閉其輸出流的 前後。
I/O 流引擎
輸出引擎解決了讓我費力處理的問題,它是一個通過輸出流過濾器將數據從 輸入流復制到目標輸出流的引擎。這滿足了遞增性的特性,因為它可以一次讀寫 單個緩沖區。
清單 5 到 10 中的代碼實現了這樣的一個引擎。通過輸入流和輸入流工廠來 構造它。清單 11 是一個生成過濾後的輸出流的工廠;例如,它會返回包裝了目 標輸出流的 GZIPOutputStream 。
清單 5. I/O 流引擎
package org.merlin.io;
import java.io.*;
/**
* An output engine that copies data from an InputStream through
* a FilterOutputStream to the target OutputStream.
*
* @author Copyright (c) 2002 Merlin Hughes <merlin@merlin.org>
*
* This program is free software; you can redistribute it and/or
* modify it under the terms of the GNU General Public License
* as published by the Free Software Foundation; either version 2
* of the License, or (at your option) any later version.
*/
public class IOStreamEngine implements OutputEngine {
private static final int DEFAULT_BUFFER_SIZE = 8192;
private InputStream in;
private OutputStreamFactory factory;
private byte[] buffer;
private OutputStream out;
該類的構造器只初始化各種變量和將用於傳輸數據的緩沖區。
清單 6. 構造器
public IOStreamEngine (InputStream in, OutputStreamFactory factory) {
this (in, factory, DEFAULT_BUFFER_SIZE);
}
public IOStreamEngine
(InputStream in, OutputStreamFactory factory, int bufferSize) {
this.in = in;
this.factory = factory;
buffer = new byte[bufferSize];
}
在 initialize() 方法中,該引擎調用其工廠來封裝與其一起提供的 OutputStream 。該工廠通常將一個過濾器連接至 OutputStream 。
清單 7. initialize() 方法
public void initialize (OutputStream out) throws IOException {
if (this.out != null) {
throw new IOException ("Already initialised");
} else {
this.out = factory.getOutputStream (out);
}
}
在 execute() 方法中,引擎從 InputStream 中讀取一個緩沖區的數據,然 後將它們寫入已封裝的 OutputStream ;或者,如果輸入結束,它會關閉 OutputStream 。
清單 8. execute() 方法
public void execute () throws IOException {
if (out == null) {
throw new IOException ("Not yet initialised");
} else {
int amount = in.read (buffer);
if (amount < 0) {
out.close ();
} else {
out.write (buffer, 0, amount);
}
}
}
最後,當關閉引擎時,它就關閉其 InputStream 。
清單 9. 關閉 InputStream
public void finish () throws IOException {
in.close ();
}
內部 OutputStreamFactory 接口(下面清單 10 中所示)描述可以返回過濾 後的 OutputStream 的類。
清單 10. 內部輸出流工廠接口
public static interface OutputStreamFactory {
public OutputStream getOutputStream (OutputStream out)
throws IOException;
}
}
清單 11 顯示將提供的流封裝到 GZIPOutputStream 中的一個示例工廠:
清單 11. GZIP 輸出流工廠
public class GZIPOutputStreamFactory
implements IOStreamEngine.OutputStreamFactory {
public OutputStream getOutputStream (OutputStream out)
throws IOException {
return new GZIPOutputStream (out);
}
}
該 I/O 流引擎及其輸出流工廠框架通常足以支持大多數的輸出流過濾需要。
輸出引擎輸入流
最後,我們還需要一小段代碼來完成這個解決方案。清單 12 到 16 中的代 碼提供了讀取由輸出引擎所寫數據的輸入流。事實上,這段代碼有兩個部分:主 類是一個從內部緩沖區讀取數據的輸入流。與此緊密耦合的是一個輸出流(如清 單 17 所示),它把輸出引擎所寫的數據填充到內部讀緩沖區。
主輸入流類將用其內部輸出流來初始化輸出引擎。然後,每當它的緩沖區為 空時,它會自動執行該引擎來接收更多數據。輸出引擎將數據寫入其輸出流中, 這將重新填充輸入流的內部緩沖區,以允許需要內部緩沖區數據的應用程序高效 地讀取數據。
清單 12. 輸出引擎輸入流
package org.merlin.io;
import java.io.*;
/**
* An input stream that reads data from an OutputEngine.
*
* @author Copyright (c) 2002 Merlin Hughes <merlin@merlin.org>
*
* This program is free software; you can redistribute it and/or
* modify it under the terms of the GNU General Public License
* as published by the Free Software Foundation; either version 2
* of the License, or (at your option) any later version.
*/
public class OutputEngineInputStream extends InputStream {
private static final int DEFAULT_INITIAL_BUFFER_SIZE = 8192;
private OutputEngine engine;
private byte[] buffer;
private int index, limit, capacity;
private boolean closed, eof;
該輸入流的構造器獲取一個輸出引擎以從中讀取數據和一個可選的緩沖區大 小。該流首先初始化其本身,然後初始化輸出引擎。
清單 13. 構造器
public OutputEngineInputStream (OutputEngine engine) throws IOException {
this (engine, DEFAULT_INITIAL_BUFFER_SIZE);
}
public OutputEngineInputStream (OutputEngine engine, int initialBufferSize)
throws IOException {
this.engine = engine;
capacity = initialBufferSize;
buffer = new byte[capacity];
engine.initialize (new OutputStreamImpl ());
}
代碼的主要讀部分是一個相對簡單的基於字節數組的輸入流,與 ByteArrayInputStream 類非常相似。然而,每當需要數據而該流為空時,它都 會調用輸出引擎的 execute() 方法來重新填寫讀緩沖區。然後,將這些新數據 返回給調用程序。因而,這個類將對輸出引擎所寫的數據反復讀取,直到它讀完 為止,此時將設置 eof 標志並且該流將返回已到達文件末尾的信息。
清單 14. 讀取數據
private byte[] one = new byte[1];
public int read () throws IOException {
int amount = read (one, 0, 1);
return (amount < 0) ? -1 : one[0] & 0xff;
}
public int read (byte data[], int offset, int length)
throws IOException {
if (data == null) {
throw new NullPointerException ();
} else if
((offset < 0) || (length < 0) || (offset + length > data.length)) {
throw new IndexOutOfBoundsException ();
} else if (closed) {
throw new IOException ("Stream closed");
} else {
while (index >= limit) {
if (eof)
return -1;
engine.execute ();
}
if (limit - index < length)
length = limit - index;
System.arraycopy (buffer, index, data, offset, length);
index += length;
return length;
}
}
public long skip (long amount) throws IOException {
if (closed) {
throw new IOException ("Stream closed");
} else if (amount <= 0) {
return 0;
} else {
while (index >= limit) {
if (eof)
return 0;
engine.execute ();
}
if (limit - index < amount)
amount = limit - index;
index += (int) amount;
return amount;
}
}
public int available () throws IOException {
if (closed) {
throw new IOException ("Stream closed");
} else {
return limit - index;
}
}
當操作數據的應用程序關閉該流時,它調用輸出引擎的 finish() 方法,以 便可以釋放其正在使用的任何資源。
清單 15. 釋放資源
public void close () throws IOException {
if (!closed) {
closed = true;
engine.finish ();
}
}
當輸出引擎將數據寫入其輸出流時,調用 writeImpl() 方法。它將這些數據 復制到讀緩沖區,並更新讀限制索引;這將使新數據可自動地用於讀方法。
在單次循環中,如果輸出引擎寫入的數據比緩沖區中可以保存的數據多,則 緩沖區的容量會翻倍。然而,這不能頻繁發生;緩沖區應該快速擴展到足夠的大 小,以便進行狀態穩定的操作。
清單 16. writeImpl() 方法
private void writeImpl (byte[] data, int offset, int length) {
if (index >= limit)
index = limit = 0;
if (limit + length > capacity) {
capacity = capacity * 2 + length;
byte[] tmp = new byte[capacity];
System.arraycopy (buffer, index, tmp, 0, limit - index);
buffer = tmp;
limit -= index;
index = 0;
}
System.arraycopy (data, offset, buffer, limit, length);
limit += length;
}
下面清單 17 中顯示的內部輸出流實現表示了一個流將數據寫入內部輸出流 緩沖區。該代碼驗證參數都是可接受的,並且如果是這樣的話,它調用 writeImpl() 方法。
清單 17. 內部輸出流實現
private class OutputStreamImpl extends OutputStream {
public void write (int datum) throws IOException {
one[0] = (byte) datum;
write (one, 0, 1);
}
public void write (byte[] data, int offset, int length)
throws IOException {
if (data == null) {
throw new NullPointerException ();
} else if
((offset < 0) || (length < 0) || (offset + length > data.length)) {
throw new IndexOutOfBoundsException ();
} else if (eof) {
throw new IOException ("Stream closed");
} else {
writeImpl (data, offset, length);
}
}
最後,當輸出引擎關閉其輸出流,表明它已寫入了所有的數據時,該輸出流 設置輸入流的 eof 標志,表明已經讀取了所有的數據。
清單 18. 設置輸入流的 eof 標志
public void close () {
eof = true;
}
}
}
敏感的讀者可能注意到我應該將 writeImpl() 方法的主體直接放在輸出流實 現中:內部類有權訪問所有包含類的私有成員。然而,對這些字段的內部類訪問 比由包含類的直接方法的訪問在效率方面稍許差一些。所以,考慮到效率以及為 了使類之間的相關性最小化,我使用額外的助手方法。
應用工程解決方案:在讀取期間壓縮數據
清單 19 演示了這個類框架的使用來解決我最初的問題:在我讀取數據時壓 縮它們。該解決方案歸結為創建一個與輸入流相關聯的 IOStreamEngine 和一個 GZIPOutputStreamFactory ,然後將 OutputEngineInputStream 與這個 GZIPOutputStreamFactory 相連。自動執行流的初始化和連接,然後可以直接從 結果流中讀取壓縮數據。當處理完成且關閉流時,輸出引擎自動關閉,並且它關 閉初始輸入流。
清單 19. 應用工程解決方案
private static InputStream engineCompress (InputStream in)
throws IOException {
return new OutputEngineInputStream
(new IOStreamEngine (in, new GZIPOutputStreamFactory ()));
}
雖然為解決這類問題而設計的解決方案應該產生十分清晰的代碼,這一點沒 有什麼可驚奇的,但是通常要充分留意以下教訓:無論問題大小,應用良好的設 計技術都幾乎肯定會產生更為清晰、更便於維護的代碼。
測試性能
從效率看, IOStreamEngine 將數據讀入其內部緩沖區,然後通過壓縮過濾 器將它們寫入 OutputStreamImpl 。這將數據直接寫入 OutputEngineInputStream ,以便它們可供讀取。總共只執行兩次緩沖區復制, 這意味著我應該從管道式流解決方案的緩沖區復制效率和蠻力解決方案的無線程 效率的結合中獲益。
要測試實際的性能,我編寫了一個簡單的測試工具(請參閱所附 資源中的 test.PerformanceTest ),它使用這三個推薦的解決方案,通過使用一個空過 濾器來讀取一塊啞元數據。在運行 Java 2 SDK,版本 1.4.0 的 800 MHz Linux 機器上,達到了下列性能:
管道式流解決方案
15KB:23ms;15MB:22100ms
蠻力解決方案
15KB:0.35ms;15MB:745ms
工程解決方案
15KB:0.16ms;15MB:73ms
該問題的工程解決方案很明顯比基於標准 Java API 的另兩個方法都更有效 。
順便提一下,考慮到如果輸出引擎能夠遵守這樣的約定:在將數據寫入其輸 出流後,它不修改從中寫入數據的數組而返回,那麼我能提供一個只使用一次緩 沖區復制操作的解決方案。可是,輸出引擎很少會遵守這種約定。如果需要,輸 出引擎只要通過實現適當的標記程序接口,就能宣稱它支持這種方式的操作。
應用工程解決方案:讀取編碼的字符數據
任何可以用“提供對將數據反復寫入 OutputStream 的實體的讀訪問權”表 述的問題,都可以用這一框架解決。在這一節和下一節中,我們將研究這樣的問 題示例及其有效的解決方案。
首先,考慮要讀取 UTF-8 編碼格式的字符流的情況: InputStreamReader 類讓您將以二進制編碼的字符數據作為一系列 Unicode 字符讀取;它表示了從 字節輸入流到字符輸入流的關口。 OutputStreamWriter 類讓您將一系列二進制 編碼格式的 Unicode 字符寫入輸出流;它表示從字符輸出流到字節輸入流的關 口。 String 類的 getBytes() 方法將字符串轉換成經編碼的字節數組。然而, 這些類中沒有一個能直接讓您讀取 UTF-8 編碼格式的字符流。
清單 20 到 24 中的代碼演示了以與 IOStreamEngine 類極其相似的方式使 用 OutputEngine 框架的一種解決方案。我們並不是從輸入流讀取和通過輸出流 過濾器進行寫操作,而是從字符流讀取,並通過所選的字符進行編碼的 OutputStreamWriter 進行寫操作。
清單 20. 讀取編碼的字符數據
package org.merlin.io;
import java.io.*;
/**
* An output engine that copies data from a Reader through
* a OutputStreamWriter to the target OutputStream.
*
* @author Copyright (c) 2002 Merlin Hughes <merlin@merlin.org>
*
* This program is free software; you can redistribute it and/or
* modify it under the terms of the GNU General Public License
* as published by the Free Software Foundation; either version 2
* of the License, or (at your option) any later version.
*/
public class ReaderWriterEngine implements OutputEngine {
private static final int DEFAULT_BUFFER_SIZE = 8192;
private Reader reader;
private String encoding;
private char[] buffer;
private Writer writer;
該類的構造器接受要從中讀取的字符流、要使用的編碼以及可選的緩沖區大 小。
清單 21. 構造器
public ReaderWriterEngine (Reader in, String encoding) {
this (in, encoding, DEFAULT_BUFFER_SIZE);
}
public ReaderWriterEngine
(Reader reader, String encoding, int bufferSize) {
this.reader = reader;
this.encoding = encoding;
buffer = new char[bufferSize];
}
當該引擎初始化時,它將以所選編碼格式寫字符的 OutputStreamWriter 連 接至提供的輸出流。
清單 22. 初始化輸出流寫程序
public void initialize (OutputStream out) throws IOException {
if (writer != null) {
throw new IOException ("Already initialised");
} else {
writer = new OutputStreamWriter (out, encoding);
}
}
當執行該引擎時,它從輸入字符流中讀取數據,然後將它們寫入 OutputStreamWriter ,接著 OutputStreamWriter 將它們以所選的編碼格式傳 遞給相連的輸出流。至此,該框架使數據可供讀取。
清單 23. 讀取數據
public void execute () throws IOException {
if (writer == null) {
throw new IOException ("Not yet initialised");
} else {
int amount = reader.read (buffer);
if (amount < 0) {
writer.close ();
} else {
writer.write (buffer, 0, amount);
}
}
}
當引擎執行完時,它關閉其輸入。
清單 24. 關閉輸入
public void finish () throws IOException {
reader.close ();
}
}
在這種與壓縮不同的情況中,Java I/O 包不提供對 OutputStreamWriter 之 下的字符編碼類的低級別訪問。因此,這是在 Java 平台 1.4 之前的發行版上 讀取編碼格式的字符流的唯一有效解決方案。從版本 1.4 開始, java.nio.charset 包確實提供了與流無關的字符編碼和譯碼能力。然而,這個 包不能滿足我們對基於輸入流的解決方案的要求。
應用工程解決方案:讀取序列化的 DOM 文檔
最後,讓我們研究該框架的最後一種用法。清單 25 到 29 中的代碼提供了 一個用來讀取序列化格式的 DOM 文檔或文檔子集的解決方案。這一代碼的潛在 用途可能是對部分 DOM 文檔執行確認性重新解析。
清單 25. 讀取序列化的 DOM 文檔
package org.merlin.io;
import java.io.*;
import java.util.*;
import org.w3c.dom.*;
import org.w3c.dom.traversal.*;
/**
* An output engine that serializes a DOM tree using a specified
* character encoding to the target OutputStream.
*
* @author Copyright (c) 2002 Merlin Hughes <merlin@merlin.org>
*
* This program is free software; you can redistribute it and/or
* modify it under the terms of the GNU General Public License
* as published by the Free Software Foundation; either version 2
* of the License, or (at your option) any later version.
*/
public class DOMSerializerEngine implements OutputEngine {
private NodeIterator iterator;
private String encoding;
private OutputStreamWriter writer;
構造器獲取要在上面進行循環的 DOM 節點,或預先構造的節點迭代器(這是 DOM 2 的一部分),以及一個用於序列化格式的編碼。
清單 26. 構造器
public DOMSerializerEngine (Node root) {
this (root, "UTF-8");
}
public DOMSerializerEngine (Node root, String encoding) {
this (getIterator (root), encoding);
}
private static NodeIterator getIterator (Node node) {
DocumentTraversal dt= (DocumentTraversal)
(node.getNodeType () ==
Node.DOCUMENT_NODE) ? node : node.getOwnerDocument ();
return dt.createNodeIterator (node, NodeFilter.SHOW_ALL, null, false);
}
public DOMSerializerEngine (NodeIterator iterator, String encoding) {
this.iterator = iterator;
this.encoding = encoding;
}
初始化期間,該引擎將適當的 OutputStreamWriter 連接至目標輸出流。
清單 27. initialize() 方法
public void initialize (OutputStream out) throws IOException {
if (writer != null) {
throw new IOException ("Already initialised");
} else {
writer = new OutputStreamWriter (out, encoding);
}
}
在執行階段,該引擎從節點迭代器中獲得下一個節點,然後將其序列化至 OutputStreamWriter 。當獲取了所有節點後,引擎關閉它的流。
清單 28. execute() 方法
public void execute () throws IOException {
if (writer == null) {
throw new IOException ("Not yet initialised");
} else {
Node node = iterator.nextNode ();
closeElements (node);
if (node == null) {
writer.close ();
} else {
writeNode (node);
writer.flush ();
}
}
}
當該引擎關閉時,沒有要釋放的資源。
清單 29. 關閉
public void finish () throws IOException {
}
// private void closeElements (Node node) throws IOException ...
// private void writeNode (Node node) throws IOException ...
}
序列化每個節點的其它內部細節不太有趣;這一過程主要涉及根據節點的類 型和 XML 1.0 規范寫出節點,所以我將在本文中省略這一部分的代碼。請參閱 附帶的 源代碼,獲取完整的詳細信息。
結束語
我所提供的是一個有用的框架,它利用標准輸入流 API 讓您能有效讀取由只 能寫入輸出流的系統產生的數據。它讓我們讀取經壓縮或編碼的數據及序列化文 檔等。雖然可以使用標准 Java API 實現這一功能,但使用這些類的效率根本不 行。應該充分注意到,這種解決方案比最簡單的蠻力解決方案更有效(即使在數 據不大的情況下)。將數據寫入 ByteArrayOutputStream 以便進行後續處理的 任何應用程序都可能從這一框架中受益。
字節數組流的拙劣性能和管道式流難以置信的蹩腳性能,實際上都是我下一 篇文章的主題。在那篇文章中,我將研究重新實現這些類,並比這些類的原創者 更加關注它們的性能。只要 API 約定稍微寬松一點,性能就可能改進一百倍了 。
我討厭洗碗。不過,正如大多數我自認為是較好(雖然常常還是微不足道) 的想法一樣,這些類背後的想法都是在我洗碗時冒出來的。我時常發現撇開實際 代碼,回頭看看並且把問題的范圍考慮得更廣些,可能會得出一個更好的解決方 案,它最終為您提供的方法可能比您找出的容易方法更好。這些解決方案常常會 產生更清晰、更有效而且更可維護的代碼。
我真的擔心我們有了洗碗機的那一天。