概述
本文的目的是向您展示如何在 Eclipse 集成開發環境(IDE)中使用幾種不同的工具,例如 Java Development Tools、IBM? DB2? plug-ins for Eclipse 和 IBM integration plug-in for Derby,以便開發 Apache Derby 應用程序。
本文將介紹一個典型 Derby 應用程序的整個開發周期,從數據庫的創建開始,然後經歷 JDBC 客戶機應用程序的開發,存儲過程和函數的開發,最後是解決方案的開發。本文還將描述必要時如何用 DB2 Universal Database (UDB) 數據庫替代 Apache Derby 數據庫。
本文假設您對 Apache Derby 數據庫、Eclipse 平台和 DB2 plug-ins for Eclipse 有基本的理解。
為了闡明應用程序開發中涉及的各種不同任務,作者 Gilles Roux 將提供關於如何構建一個示例應用程序的具體例子和逐步說明。
在這個例子中,您需要開發一個命令行應用程序來執行一家書店的庫存管理。書店的數據庫存儲了這家書店擁有的各種書籍,以及這些書籍的現有數量。
這個示例應用程序將允許您訪問這些數據,並允許您更改書籍的數量。例如,如果從一個供應商那裡收到一批書,那麼就要使用這個應用程序來添加所收到書籍的數量。如果書籍的數量超過或者低於某個限制,則需要用電子郵件通知管理員,以便其采取必要的行動。
開發環境
工具
Java Development Tools(JDT)是一組內建到 Eclipse 中的插件,為編輯、編譯、調試、執行和部署一般用途的 Java 應用程序提供了一種方法。
DB2 plug-ins for Eclipse 提供了連接到各種數據庫(包括 IBM Cloudscape 和 Apache Derby)的一組功能。這個插件是以下幾個插件的組合。
Connection Wizard:用於創建和連接 DB2、Cloudscape 或 Derby 數據庫。
Database Explorer View:用於浏覽數據庫對象。
SQL Scrapbook:用於編輯和執行單獨的 SQL 語句。
Database Output View:用於對一個表的內容進行抽樣或者查看一條 SQL 語句的執行結果。
Migration Wizard:用於自動地將一個現有 Derby 數據庫遷移到 DB2 UDB。
IBM integration plug-in for Derby 將很多有用的 Derby 工具集成到了 Eclipse 環境中。下面是該工具所提供的主要功能:
Apache Derby Nature:使 Eclipse 項目可以執行 Derby 任務。
Network Server:直接從 Eclipse 項目中配置和啟動 Derby Network Server。
IJ:直接在 Eclipse 控制台中以交互模式或腳本模式啟動 Derby 命令行實用程序。
Sysinfo:顯示與項目相關的 Derby 系統信息。
DB2 plug-ins for Eclipse 和 IBM Integration plug-in for Derby 是兩個獨立的工具,但是它們之間互補性很強,前者提供了一般數據庫連接,而後者則提供了訪問很多特定於 Derby 特性的訪問途徑。
然而,很多任務都可以通過這些工具中的任意一個來執行,效果是一樣的。本文提到了執行一個給定任務的各種不同方法,從而使每個用戶都可以選擇他們所喜愛的工作方式。
安裝工具
首先要下載和安裝 DB2 plug-ins for Eclipse。該產品包括 DB2 插件,並且是基於 Eclipse 3.0 的,後者本身就包括了 JDT。
然後從 Apache.org 下載 Apache Derby plug-in,並在安裝了前面軟件的基礎上安裝此軟件。
最後,下載 IBM Integration plug-in for Derby 並在安裝了 eclipse 的基礎上安裝此軟件。該插件包括 JCC JDBC 驅動程序和 Derby 集成工具。
設置開發環境
如前所述,您將使用幾種不同的工具來開發應用程序:DB2 plug-ins for Eclipse、IBM Integration plug-in for Derby 和 JDT。這些工具都是基於 Eclipse 的,因此它們可以很好地集成到一個單獨的開發環境中。
在開發應用程序時,通常要建立一些到數據庫的連接:
使用 Database Explorer 浏覽數據庫。
使用 Derby ij 命令行實用程序執行 SQL 語句。
在測試時應用程序自己將連接到數據庫。
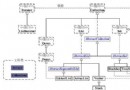
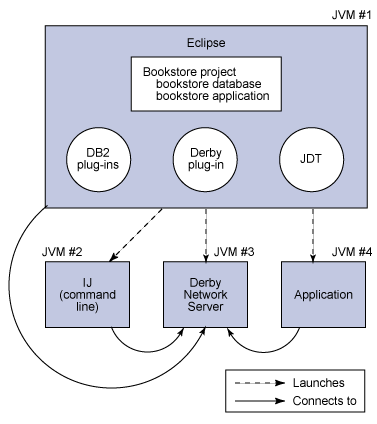
Derby 數據庫引擎可以在多種配置下運行。最簡單的一種是嵌入式配置,但在這裡不適合,因為需要通過運行在不同 Java 虛擬機上的幾種工具建立連接。而且,在生產環境中,可能需要從多個應用程序中訪問數據庫。因此,這裡使用 Network Server 配置。IBM Integration plug-in for Derby 提供了一種選擇,以便可以很容易地從 Eclipse 項目目錄中啟動本地機器上的 Derby Network Server。接著要配置應用程序和其他工具,以連接到該網絡服務器。下圖展示了配置情況。
圖 1. 開發環境配置
設置環境的第一步是創建項目。選擇“File->New->Project->Java Project”並輸入 bookstore 作為項目名稱。這樣就創建了一個 Java 項目,然後切換到 Java perspective(透視圖)中。右擊該項目並選擇“Apache Derby->Add Apache Derby nature”。這樣使您的項目可以使用 Apache Derby 特性,然後設置該 Java 項目的構建路徑,以便應用程序可以訪問 Derby 數據庫和 JDBC 驅動程序。
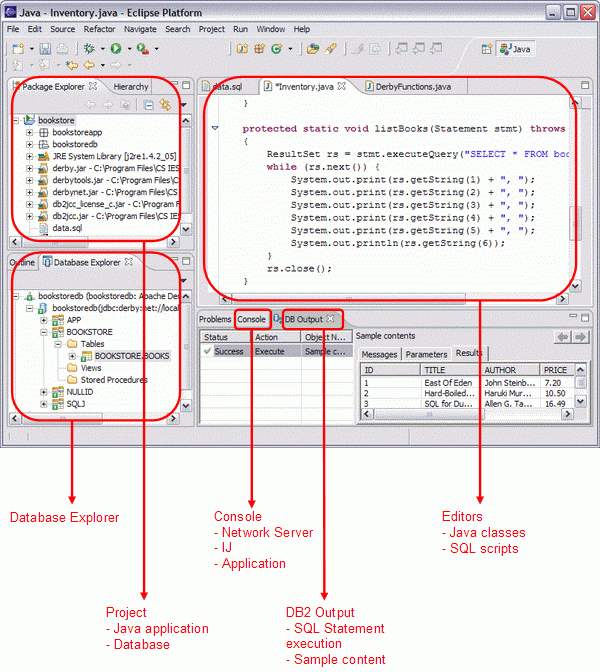
DB2 plug-ins for Eclipse 通常可以從 Data perspective 訪問,並且無需與某個特定的項目相關聯。為了簡化開發過程,避免 Java perspective 和 Data perspective 之間的切換,需要將 DB2 plug-ins 視圖,即 Database Explorer 視圖和 DB Output 視圖,添加到 Java perspective。這可以通過 Show View->Other 菜單來完成。下圖展示了開發環境的外觀。
圖 2. 開發環境布局
創建數據庫
在開始編寫實際的應用程序代碼之前,需要創建應用程序將要用到的數據庫,或者連接到一個已有的數據庫。
首先通過右擊項目並選擇“Apache Derby->Start Derby Network Server”來啟動 Derby Network Server。每次重新啟動 Eclipse 時都需要執行這一步。這時項目圖標上有一個綠色的箭頭,表明服務器正在運行。
創建數據庫
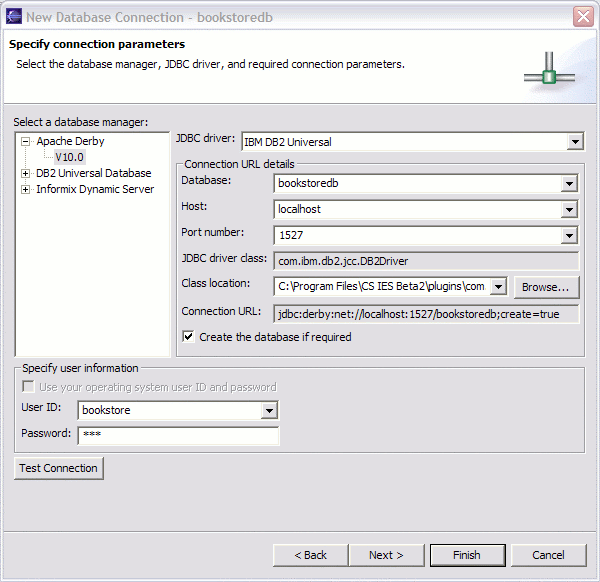
創建一個 Derby 數據庫非常類似於連接到一個已有的數據庫:通過將 create=true 屬性包括在 URL 中,可以指示數據庫引擎在您第一次連接到數據庫時創建該數據庫。這可以通過使用 DB2 plug-ins for Eclipse 的 Connection Wizard 來完成。下面的表展示了在這個向導中應該使用的參數。
表 1. 連接參數
Connection name bookstoredb Database Manager Apache Derby v10.0 JDBC Driver IBM DB2 Universal 需要使用這個參數來連接到網絡服務器 Database bookstoredb 要創建的數據庫的名稱 Host localhost 網絡服務器運行在本地機器上 Port Number 1527 默認端口號 Class Location 比如: C:\eclipse\plugins\ com.ibm.cloudscape.ui_1.0.0\db2jcc_license_c.jar;C:\eclipse\plugins\com.ibm.cloudscape.ui_1.0.0 \db2jcc.jar Create database if required yes 需要使用這個參數在第一次連接時創建數據庫 User ID bookstore 數據庫上的認證沒有被啟用,因此可以使用任何用戶,但是用戶名將定義默認模式 Password aaa 數據庫上的認證沒有被啟用,因此可以使用任何密碼
圖 3. 使用 Connection Wizard 創建數據庫
完成該向導後,便創建了一個數據庫,並且向 Database Explorer View 中添加了一個連接。通過展開連接的節點,就可以浏覽這個數據庫,但是顯然這個時候它是空的。
數據庫被創建在 Derby 網絡服務器的當前目錄中,也就是之前創建 Eclipse 項目時所在的目錄。可以通過右擊項目名並選擇 Refresh 來刷新該項目,這樣將顯示一個新的 bookstoredb/ 目錄,該目錄包含用於數據庫的文件。不要試圖修改這些文件,否則數據庫會受到損壞。
創建數據庫對象
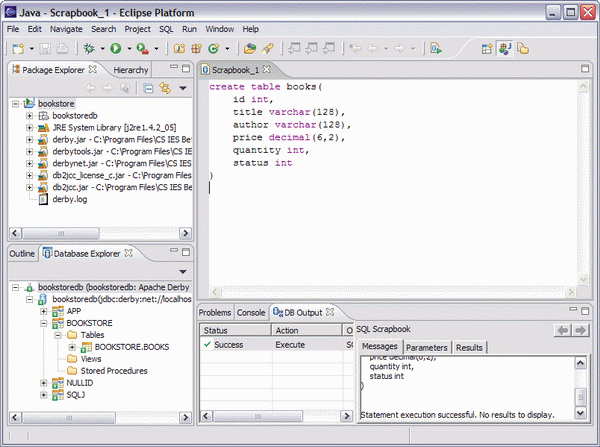
接下來的步驟是創建應用程序將要用到的數據庫對象。在這裡,只需使用 SQL Scrapbook 創建一個表即可。SQL Scrapbook 可以通過右擊連接名並選擇“Open SQL Scrapbook”來調用。這時將打開一個新的編輯器,在這個編輯器中可以輸入要發出的 SQL 語句:
清單 1. CREATE TABLE 語句
create table books(
id int,
title varchar(128),
author varchar(128),
price decimal(6,2),
quantity int,
status int
)
請注意,SQL Scrapbook 只能用於執行單條的 SQL 語句。而且,不要以分號來結束 SQL 語句。然後,可以按下主 Eclipse 按鈕欄中的“Execute SQL statement”按鈕。DB Output 視圖應該顯示結果是成功的。還可以刷新連接,以及驗證數據庫現在是否包含新創建的表。
圖 4. 使用 SQL Scrapbook 創建表
創建測試數據
現在通過執行 INSERT 語句向 books 表填充一些測試數據。這也可以通過 SQL Scrapbook 來實現,但這裡我們使用了 IBM Integration plug-in for Derby 的“Run SQL script using ij”功能。這項功能允許使用 Derby 命令行實用程序執行 SQL 腳本,並在 Eclipse 輸出視圖中查看結果。這種方法的一大優點是:它允許一次執行多條語句。而且,這種方法要求在腳本的開始處包含一條連接語句,因此您可以對連接 URL 有更多的控制。
表 2. SQL Scrapbook 和 IJ 腳本 之間的不同之處
SQL Scrapbook 執行 IJ 腳本 語句存儲在一個文件中 不是 是 一次可以執行多條語句 不是 是 語句終止符 不允許有終止符 分號 編輯功能 語法高亮顯示,內容輔助 沒有 到數據庫的連接 SQL scrapbook 被關聯到一個給定的連接 第一條語句應該是到所需數據庫的一個連接
構建 URL 的一種簡便方法是復制 Connection Wizard 所使用的 URL:在數據庫浏覽器中右擊連接,然後選擇“Edit Connection”並訪問“Connection URL”字段。這裡需要添加用戶名和密碼作為 URL 屬性。
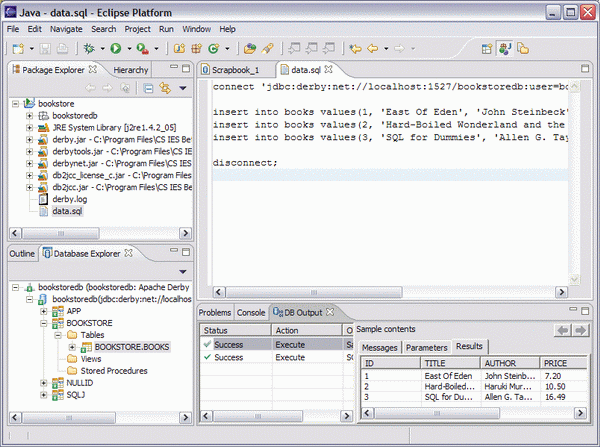
使用 Eclipse 在項目中創建一個名為 data.sql 的文本文件,並鍵入以下命令:
清單 2. INSERT INTO 語句
connect 'jdbc:derby:net://localhost:1527/bookstoredb:user=bookstore;password=aaa;';
insert into books values(1, 'East Of Eden', 'John Steinbeck', 7.20, 3, 0);
insert into books values(2, 'Hard-Boiled Wonderland and the End of the World',
'Haruki Murakami', 10.50, 9, 0);
insert into books values(3, 'SQL for Dummies', 'Allen G. Taylor', 16.49, 6, 0);
disconnect;
然後就可以在 Project Explorer 中右擊該文件並選擇“Apache Derby->Run SQL script using ij”。Eclipse 的控制台輸出視圖將顯示執行的結果,這個結果應該是成功的。然後可以在 Database Explorer 中選擇 books 表,並選擇“Sample Content”,以確信數據真正被插入到這個表中。
圖 5. 執行 SQL 腳本以插入數據
編寫 Derby Client JDBC 應用程序
裝載 JDBC 驅動程序
通過使用 Eclipse JDT 和 Derby JDBC 驅動程序,可以很容易地編寫 JDBC 應用程序。首先使用 JDT Class 向導在 bookstoreapp.clientside 包中創建一個 Inventory 類,並在類中添加一個 main() 方法。由於啟用了 Derby nature,所以包含 JDBC 驅動程序和 Derby 類的 JAR 文件已經位於項目的類路徑中。
在連接到一個 Derby 數據庫之前,需要使用 Class.forName(jdbcDriverClassName) 方法裝載適當的 JDBC 驅動程序。該方法將裝載參數指定的 JDBC Driver 類,並注冊這個類,以便進行下一次 JDBC 連接。
可以使用兩種不同的 JDBC 驅動程序,這取決於 Derby 配置:
表 3. Derby JDBC 驅動程序
配置 Embedded Server Network Server 所需 JAR 文件 derby.jar db2jcc.jar;db2jcc_license_c.jar 類名 org.apache.derby.jdbc.EmbeddedDriver com.ibm.db2.jcc.DB2Driver
由於這個例子是基於一個網絡服務器配置,因此這裡使用 jcc JDBC 驅動程序。如果不確定的話,那麼正確的類名可以通過從 Connection 向導復制獲得:
清單 3. 裝載 jcc JDBC 驅動程序
Class.forName("com.ibm.db2.jcc.DB2Driver");
連接到數據庫
DriverManager.getConnection(url) 方法用於建立到數據庫的連接。它假設一個連接 URL,並返回一個 Connection 對象,這個對象可用於查詢數據庫。
獲得連接 URL 的一種好方法是在 Database Explorer 視圖中編輯 Derby 連接,並復制從各個連接屬性自動構造而成的連接 URL。出於安全的原因,這裡沒有顯示用戶名和密碼,因此在應用程序代碼中需要手動地將它們添加到 URL 的後面。
圖 6. 使用連接向導構建連接 URL

其他選項也可以添加到 URL 的後面。例如,retrieveMessagesFromServerOnGetMessage=true 選項指示 JDBC 驅動程序從 Derby 服務器獲取可讀的錯誤消息,這在調試連接到遠程 Derby 數據庫的應用程序時非常有用。
在本文的例子中,使用下列代碼連接到 Derby 數據庫:
清單 4. 連接到數據庫
String url = "jdbc:derby:net://localhost:1527/bookstoredb";
url += ":user=bookstore;password=aaa;";
url += "retrieveMessagesFromServerOnGetMessage=true;";
Connection con = DriverManager.getConnection(url);
查詢數據庫
一旦建立了連接,便可以通過使用 JDBC API 查詢數據庫。例如,您可以創建一個 Statement 對象,然後使用這個對象來執行對數據庫的 SQL 查詢。查詢返回一個用於迭代查詢結果集的 ResultSet 對象:
清單 5. 執行查詢並迭代結果集
Statement stmt = con.createStatement();
ResultSet rs = stmt.executeQuery("SELECT * FROM bookstore.books");
while (rs.next()) {
System.out.print(rs.getString(1) + ", ");
System.out.print(rs.getString(2) + ", ");
System.out.print(rs.getString(3) + ", ");
System.out.print(rs.getString(4) + ", ");
System.out.print(rs.getString(5) + ", ");
System.out.println(rs.getString(6));
}
rs.close();
stmt.close();
圖 7. 運行 JDBC 應用程序
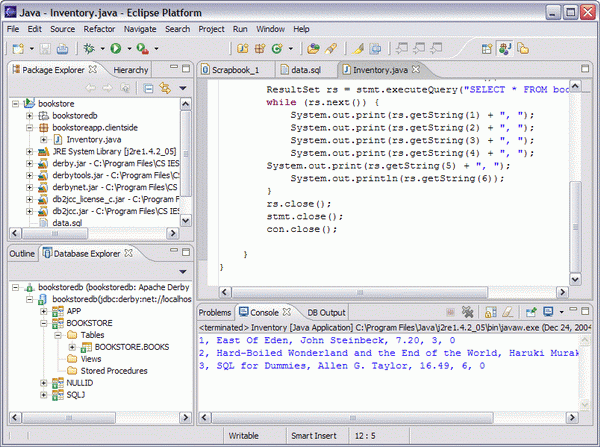
這個類實現了一個簡單的文本界面,用於列出書店中的書籍以及更新書店中給定的某種書籍的數量。
下面是應用程序輸出的一個例子:
圖 8. Inventory 應用程序的示例輸出
編寫 Java 函數和過程
前一節中討論的 JDBC 應用程序對於開發用於用戶的前端應用程序非常有用。然而,在這一層中實現重要的應用程序邏輯不是很妥當,因為應用程序邏輯放置在數據庫之外,這使得數據庫更容易受到損壞。例如,如果另一個 JDBC 應用程序連接到同一個數據庫,那麼就需要確保它實現相同的邏輯。對於這個問題,一種解決辦法是通過使用觸發器、存儲過程和函數,在數據庫中實現數據庫規則。
編寫 Java 代碼
由於 Derby 是一種 Java 數據庫,因此它沒有自己的存儲過程/函數語言,而是使用 Java 語言。可以通過創建一個 Java 方法,然後基於這個 Java 方法聲明一個 Derby 過程或函數,從而創建 Derby 存儲過程或函數(通常稱為例程)。對 Derby 例程的調用將導致這個 Java 方法被調用。
為了讓這種調用獲得成功,重要的是讓 Derby 和 Java 例程的聲明相匹配。下面的表展示了應該使用的 Derby 和 Java 特性的映射。
表 4. 用於編寫 Java 函數和過程的特性映射
Derby Java 過程 沒有返回值的公共靜態方法 函數 有一個返回值的公共靜態方法 輸入參數(過程或函數) 方法參數 輸出參數(過程) 單入口數組參數 輸入/輸出參數(過程) 單入口數組參數 返回值(函數) 返回值 返回的結果集 附加的單入口 java.sql.ResultSet[] 參數
表 5. 用於編寫 Java 函數和過程的類型映射
Derby Java SMALLINT short INTEGER int BIGINT long DECIMAL(p,s) java.math.BigDecimal REAL float DOUBLE PRECISION double CHAR(n) String VARCHAR(n) String LONG VARCHAR *unsupported* CHAR(n) FOR BIT DATA byte[] VARCHAR(n) FOR BIT DATA byte[] LONG VARCHAR FOR BIT DATA *unsupported* CLOB(n) *unsupported* BLOB(n) *unsupported* DATE java.sql.Date TIME java.sql.Time TIMESTAMP java.sql.Timestamp
對於 Java 方法本身的內容沒有約束,因此任何合法的 Java 代碼都可以作為 Derby 過程或函數來調用。一種有趣的應用是使用標准 derby:default:connection URL 建立到 Derby 數據庫的 JDBC 連接,以便查詢發出調用的數據庫。還可以使用完整 JDBC URL 連接到另一個數據庫。
對於本文的應用程序,需要在 bookstoreapp.serverside 包中創建一個 DerbyFunctions 類,用於容納數據庫服務器將要運行的所有 Java 方法。然後可以創建一個 updateQuantity 方法,當更新一種書籍的數量時,將調用該方法。調用該方法時需要提供這種書籍的 ID、title 和 author,以及舊的數量和新的 quantity。這個方法將返回一個整數值,用於表明是否到達數量限制。
因此,這個 Java 方法的聲明如下:
清單 6. Java 方法的聲明
public static int updateQuantity(int id, String title, String author,
int oldQuantity, int newQuantity)
這個函數的作用是:當書的數量達到一個下界或上界時,就發送一封電子郵件。因此,可以聲明 LOW_LIMIT 和 HIGH_LIMIT 常量,並測試舊的數量是否低於下界,新的數量是否高於上界或低於下界。如果條件符合,那麼可以調用另一個負責發送電子郵件的 Java 方法。在這個例子中,只是輸出一條調試消息,而不發送真正的電子郵件。
下面是完整的代碼:
清單 7. DerbyFunctions 類
package bookstoreapp.serverside;
public class DerbyFunctions
{
public static final int LOW_LIMIT = 2;
public static final int HIGH_LIMIT = 10;
public static int updateQuantity(int id, String title, String author,
int oldQuantity, int newQuantity)
{
if ( oldQuantity<HIGH_LIMIT && newQuantity>=HIGH_LIMIT )
sendEMailAlert("High limit reached", "title: "+title+", author: "+author);
else if ( oldQuantity>LOW_LIMIT && newQuantity<=LOW_LIMIT )
sendEMailAlert("Low limit reached", "title: "+title+", author: "+author);
if (newQuantity>=HIGH_LIMIT)
return +1;
else if (newQuantity<=LOW_LIMIT)
return -1;
else
return 0;
}
public static void sendEMailAlert(String subject, String msg)
{
System.out.println("Sending email: " + subject);
System.out.println(msg);
}
}
從 main 方法中調用這個 Java 方法,以便對其進行測試,這通常是一種很好的做法。
創建 Derby 函數
創建 Derby 存儲過程或函數比較容易,只需指定名稱、參數、返回值和相應 Java 方法的全限定名稱即可。Derby 例程的標簽必須與 Java 方法的標簽相匹配,以便數據庫可以成功地調用 Java 代碼。
可以很容易地從 SQL Scrapbook 發出 CREATE 語句,但是在這個例子中,最好使用 ij 實用程序。如果使用 ij 實用程序,便可以顯式地指定連接 URL,從而允許我們包括 retrieveMessagesFromServerOnGetMessage=true 屬性。該選項導致 JDBC 驅動程序從服務器獲取完整的錯誤消息,當語句執行失敗時,這一點很有幫助。
下面是在 ij 中發出的命令:
清單 8. 在 Derby 中創建 Java 函數
connect 'jdbc:derby:net://localhost:1527/bookstoredb
:user=bookstore;password=aaa;retrieveMessagesFromServerOnGetMessage=true;';
create function updateQuantity(id int, title varchar(128), author varchar(128),
oldQuantity int, newQuantity int) returns int
PARAMETER STYLE JAVA NO SQL LANGUAGE JAVA
EXTERNAL NAME 'bookstoreapp.serverside.DerbyFunctions.updateQuantity';
Derby 函數的創建應該可以成功,但有時候我們很難一開始就能保證語句完全正確。下面是可能發生的一些常見錯誤:
ERROR 42962: Long column type column or parameter 'I' not permitted in declared global temporary tables or procedure definitions. 如果使用一種不受支持的參數類型聲明一個 Derby 過程,就會發生這種錯誤。
ERROR 42X50: No method was found to be able to match method call pack.A.p(int), even tried all combinations of object and primitive types and any possible type conversion for any parameters the method call may have. It may be that the method exists, but it is not public and/or static, or that the parameter types are not method invocation convertible. 當調用一個過程/函數時,如果 Derby 不能找到與過程/函數聲明相匹配的 Java 方法,就會發生這種錯誤。錯誤消息給出了不能找到的 Java 方法的標簽。
請注意,如果更改了方法的 Java 代碼,那麼就需要停止並重新啟動 Derby 網絡服務器,以便數據庫引擎的類裝載器裝載新的代碼。
成功地創建了 Derby 例程之後,就可以通過 ij 命令行調用這個例程,以便對其進行測試。可以通過使用 CALL 語句來調用 derby 過程,但在這裡因為需要測試一個函數,因此發出以下命令:
清單 9. 調用 Derby 中的 Java 方法
values(updateQuantity(1, 'title', 'author', 5, 15));
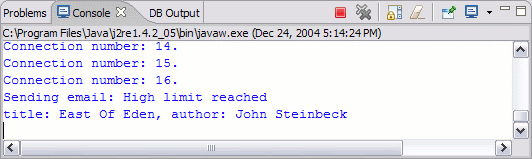
IJ 顯示返回值,在這裡,這個返回值為 1,因為數量到達了上界。由於這個 Java 方法是在 Derby 服務器 JVM 中運行的,因此調試消息將被輸出到服務器的標准輸出中。使用 eclipse 控制台視圖切換到 Derby 網絡服務器控制台,您應該可以看到一條 Sending email... 消息。
還可以嘗試使用以下代碼從 JDBC 應用程序中調用 Derby 函數:
清單 10. 從客戶機應用程序中調用 Java 方法
stmt.executeQuery("values(updateQuantity(1, 'title', 'author', 5, 15)); ");
結果應該與前面測試中的結果一致。
從 Derby 觸發器中調用函數
本節最後一步是配置 Derby,以便每次更新某種書籍的數量時,調用之前定義的函數。這可以用一個觸發器來實現。
derby 觸發器包含關於要執行的動作以及何時執行動作的信息。
表 6. CREATE TRIGGER 語句的子句
INSERT、DELETE 或 UPDATE UPDATE REFERENCING 子句 OLD AS OLD, NEW AS NEW。為了調用那個函數,需要能夠引用舊的和新的數量 FOR EACH 子句 FOR EACH ROW。即使有多行被更新,對函數的調用也是逐行進行的 動作 update books set status = updateQuantity(…) where id = NEW.id;
下面是在 ij 中發出的用於創建觸發器的語句:
清單 11. CREATE TRIGGER 語句
create trigger updateQuantityTrig after update of quantity on books
referencing OLD as OLD NEW as NEW for each row mode db2sql
update books set status = updateQuantity(NEW.id, NEW.title, NEW.author,
OLD.quantity, NEW.quantity) where id = NEW.id;
檢查觸發器是否有效的一種簡便方法是使用以下命令從 ij 工具中更新 book 表:update books set quantity=10 where id=1; 對表的修改將觸發函數的調用,從而導致執行 Java 方法。這將更新書的狀態,並發送一條消息,這條消息可以通過切換到網絡服務器控制台視圖來查看。
由於觸發器直接存儲在數據庫中,因此無論如何更新數據,對觸發器的調用都將是一致性的。由於這個原因,如果您試圖使用客戶機應用程序更新數量,那麼您將看到,適當的時候就會生成電子郵件消息,不需要對應用程序作任何更改。
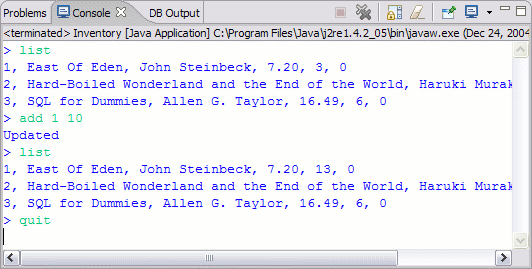
下圖展示了客戶機應用程序的輸出,用的是原始數據。注意,這一次書的狀態會獲得更新,並生成了一條消息:
圖 9. Inventory 應用程序的示例輸出
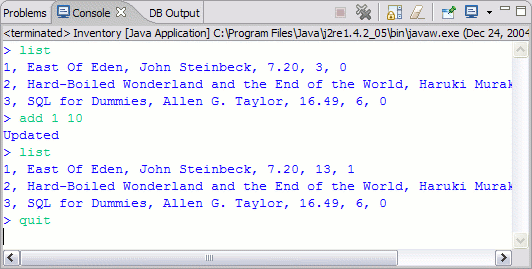
圖 10. Network Server 的示例輸出
部署應用程序
至此,您已經有了一個功能完備的數據庫和客戶機應用程序,但它們仍然只能在 Eclipse 環境中運行,在生產環境中不被接受。因此,還需要執行應用程序的部署。
將 Java 函數存儲在數據庫中
如前所述,Derby Java 函數或過程是由數據庫引擎自身來執行的。因此,數據庫引擎必須能夠訪問 Java 類。在這個例子中,這一點是沒有問題的,因為 Derby 網絡服務器運行在 Eclipse 項目中,並且使用項目的類路徑,該類路徑包含了已創建的所有 Java 類。
在一個典型的生產環境中,您不需要更改用於 Derby 網絡服務器的類路徑。Derby 提供了一些可以解決這個問題的過程:
sqlj.install_jar 過程將一個 JAR 文件安裝到數據庫中。JAR 文件在安裝好之後便無法修改,但是可以使用 sqlj.remove_jar 和 sqlj.replace_jar 來刪除或更新 JAR。
derby.database.classpath 屬性包含數據庫將要使用的附加類路徑條目。可以通過使用 syscs_util.syscs_set_database_property 過程更新這個屬性,以便更新屬性和包含已安裝的 JAR。
對於本文中的例子,首先要創建一個 JAR 文件,這個 JAR 文件包含 DerbyFunctions 類。這可以在 Eclipse 中通過右擊這個類並選擇 Export->JAR file 來完成創建任務。
然後可以使用下列命令(在 ij 中)將 JAR 文件安裝到數據庫中,並將其添加到類路徑中:
清單 12. 將 JAR 文件存儲在 Derby 數據庫中
CALL sqlj.install_jar('functions.jar', 'bookstore.functionsjar', 0);
CALL SYSCS_UTIL.SYSCS_SET_DATABASE_PROPERTY(
'derby.database.classpath', 'bookstore.functionsjar');
做完這些後,Java 代碼便屬於數據庫,這使得數據庫的轉移和啟動變得很容易。整個數據庫目錄可以直接轉移到一個完全不同的環境中,並且可以正常運行。
網絡服務器配置
在開發應用程序時,我們使用了網絡服務器配置,這樣一來,應用程序的部署就會按正確的方式打包各個組件。
在服務器端,需要安裝:
derby.jar,其中包含 Derby 數據庫引擎。
derbynet.jar,其中包含網絡服務器。
bookstoredb/ 目錄,其中包含數據庫,還包括帶有函數的 JAR 文件。
這些組件可以復制到任何裝有 JVM 的機器上,網絡服務器可以使用下列命令來啟動:
清單 13. 啟動 Derby 網絡服務器
java -cp derby.jar;derbynet.jar org.apache.derby.drda.NetworkServerControl start
可以使用下列命令可以停止網絡服務器:
清單 14. 停止 Derby 網絡服務器
java -cp derby.jar;derbynet.jar org.apache.derby.drda.NetworkServerControl shutdown
在客戶端,需要安裝:
db2jcc.jar 和 db2jcc_license_c.jar,用於 JDBC 驅動程序。
inventory.jar,這個 jar 包含了應用程序的各個類。通過使用 eclipse 導出功能,可以很容易地基於應用程序包創建這個 JAR。
這些組件可以復制到任何裝有 JVM 的機器上。當網絡服務器正在運行時,可以使用以下命令啟動應用程序:
清單 15. 啟動客戶機應用程序
java -cp db2jcc.jar;db2jcc_license_c.jar;inventory.jar bookstoreapp.clientside.Inventory
下圖闡明了網絡服務器配置中應用程序的部署:
圖 11. 網絡服務器部署配置
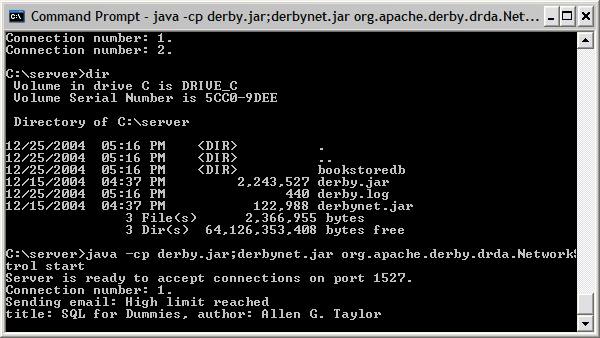
下圖展示了應用程序在生產環境中的執行:
圖 12. 已部署的網絡服務器的執行
圖 13. 已部署的客戶機應用程序的執行
嵌入式服務器配置
網絡服務器配置也許最適合這種類型的應用程序,但是也可以使用嵌入式服務器配置,比如出於性能方面的原因。
在部署應用程序之前,需要在代碼中作一下修改,使連接指向嵌入式服務器,而不是遠程服務器。這可以通過修改 JDBC 驅動程序類名和連接 URL 來實現這一點:
清單 16. 新的連接代碼
Class.forName("org.apachy.derby.jdbc.EmbeddedDriver");
String url = "jdbc:derby:bookstoredb";
完成這些修改之後,便可以使用 Eclipse 導出功能將應用程序的類打包到 JAR 文件中,並將下列文件部署到生產機器上:
derby.jar,其中包含 Derby 數據庫引擎和 JDBC 驅動程序。
inventory.jar,其中包含應用程序的類。
bookstoredb/ 目錄,其中包含數據庫,還包括帶有存儲過程和函數的 JAR 文件。
可以使用下列命令啟動應用程序:
清單 17. 啟動應用程序
java -cp derby.jar;inventory.jar bookstoreapp.clientside.Inventory
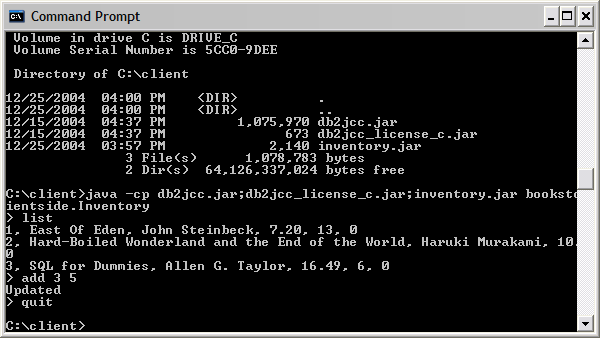
下圖闡明了應用程序在嵌入式服務器配置中的部署:
圖 14. 嵌入式服務器部署配置
遷移到 DB2
雖然 Apache Derby 是一種非常健壯的、可伸縮的數據庫,但是由於以下原因,您有理由轉而使用企業數據庫,例如 DB2 UDB:
功能缺乏。
性能受限。
需要與其他數據庫集成。
由於有了 DB2 plug-ins for Eclipse,並且客戶機應用程序是基於標准 JDBC 接口的,所以從 Derby 到 DB2 的遷移很容易完成。
遷移數據庫
第一步是遷移數據庫本身。DB2 plug-ins for Eclipse 提供了一個工具來自動地將 Apache Derby 數據庫遷移到 DB2 for Linux、Unix 和 Windows。
首先通過在 DB2 CLP 中發出 create database bookstoredb 命令創建一個 DB2 數據庫。
然後可以通過在 Database Explorer 視圖中右擊之前創建的 derby 數據庫條目並選擇 ‘Migrate to DB2 UDB…’ 動作來調用遷移工具。確保 DB2 服務器已經啟動,並遵循使用說明來創建 DB2 數據庫、遷移數據庫對象和遷移實際數據。
圖 15. 使用 DB2 plug-ins for Eclipse 遷移 Derby 數據庫
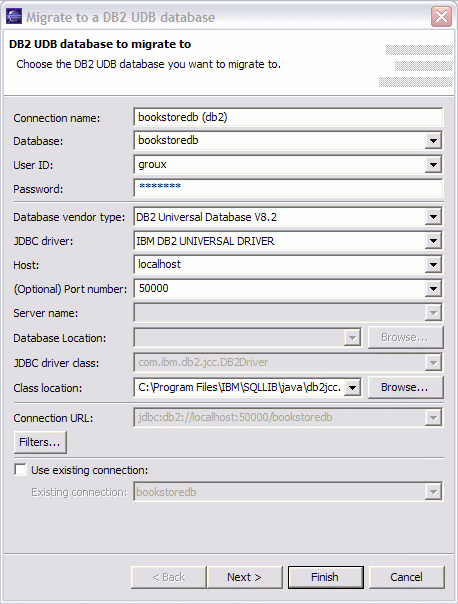
手動遷移不受支持的對象
完成了數據庫的遷移之後,遷移工具會給出一個報告,指出遷移獲得成功,但是有些對象不能遷移。當前版本的遷移工具不支持觸發器和函數,因此需要手動遷移這些對象。
Apache Derby SQL 語言是與 DB2 兼容的語言,因此可以重復使用以前的 SQL 語句來創建丟失的對象。在 Database Explorer 中右擊 DB2 連接,並打開一個新的 SQL Scrapbook。
包含 Java 函數的 JAR 文件的安裝與 Derby 的安裝類似,惟一的區別是無需將 JAR 文件添加到類路徑。從 DB2 連接打開一個 SQL scrapbook,並輸入以下命令:
清單 18. 在 DB2 中安裝 JAR 文件
CALL sqlj.install_jar('functions.jar', 'bookstore.jar1', 0)
為了創建函數和觸發器,只需將之前使用的 SQL 語句復制和粘貼到 SQL scrapbook 中。記住,一次只能執行一條語句,因而不能使用冒號作為結束符。
清單 19. 在 DB2 中創建函數和觸發器
create function bookstore.updateQuantity(id int, title varchar(128), author varchar(128),
oldQuantity int, newQuantity int) returns int
PARAMETER STYLE JAVA NO SQL LANGUAGE JAVA
EXTERNAL NAME 'bookstoreapp.StoredProcs.updateQuantity'
create trigger bookstore.updateQuantityTrig after update of quantity on books
referencing OLD as OLD NEW as NEW for each row mode db2sql
VALUES(updateQuantity(NEW.id, NEW.title, NEW.author, OLD.quantity, NEW.quantity))
遷移客戶機應用程序
遷移客戶機應用程序的主要工作是修改建立數據庫連接的那部分代碼:
既然不再使用 Derby,那麼右擊 bookstore 項目並選擇“Apache Derby->Remove Apache Derby nature”。這將從構建路徑中刪除 Derby JAR 文件。
編輯項目的 Java 構建路徑,並添加 DB2 JDBC 驅動程序 jar 文件:db2jcc.jar and db2jcc_license_cisuz.jar,對於 Windows 機器,這兩個文件通常可以在 C:\Program Files\IBM\SQLLIB\java\ 目錄下找到。
在 Java 代碼中,將 JDBC 驅動程序的類名更改為 com.ibm.db2.jcc.DB2Driver。
再將連接 URL 更改為:jdbc:db2://localhost:50000/BOOKSTORE,並更改用戶名和密碼。
由於可能沒有 bookstore 用戶名,因此需要更改 DB2 默認模式。這可以通過在客戶機應用程序初始化時發出以下命令來完成:stmt.execute("SET CURRENT SCHEMA = bookstore");
雖然 JDBC API 允許以相同的方式連接到任何數據庫,但發送到數據庫的實際的 SQL 查詢必須遵從數據庫 SQL 語言。因此,遷移 JDBC 應用程序時需要重新編寫某些 SQL 查詢。在這個例子中,Derby 語言是 DB2 語言的一個子集,因此不存在這方面的問題,您無需對 SQL 查詢作任何修改。
現在應用程序應該可以進行編譯,並且可以成功地在 DB2 數據庫上運行。還可以像在 Derby 網絡服務器配置中那樣部署應用程序。
結束語
在閱讀本文之後,您應該能夠有效地使用為 Derby 提供的基於 Eclipse 的不同工具開發 Apache Derby 應用程序。您還應該可以執行一些相關的任務,例如在各種可能的配置中部署這種應用程序,或者將數據庫和應用程序遷移到 DB2 UDB。