十五年前,多處理器系統是高度專用系統,要花費數十萬美元(大多數具有 兩個到四個處理器)。現在,多處理器系統很便宜,而且數量很多,幾乎每個主 要微處理器都內置了多處理支持,其中許多系統支持數十個或數百個處理器。
要使用多處理器系統的功能,通常需要使用多線程構造應用程序。但是正如 任何編寫並發應用程序的人可以告訴你的那樣,要獲得好的硬件利用率,只是簡 單地在多個線程中分割工作是不夠的,還必須確保線程確實大部分時間都在工作 ,而不是在等待更多的工作,或等待鎖定共享數據結構。
問題:線程之間的協調
如果線程之間 不需要協調,那麼幾乎沒有任務可以真正地並行。以線程池為 例,其中執行的任務通常相互獨立。如果線程池利用公共工作隊列,則從工作隊 列中刪除元素或向工作隊列添加元素的過程必須是線程安全的,並且這意味著要 協調對頭、尾或節點間鏈接指針所進行的訪問。正是這種協調導致了所有問題。
標准方法:鎖定
在 Java 語言中,協調對共享字段的訪問的傳統方法是使用同步,確保完成 對共享字段的所有訪問,同時具有適當的鎖定。通過同步,可以確定(假設類編 寫正確)具有保護一組給定變量的鎖定的所有線程都將擁有對這些變量的獨占訪 問權,並且以後其他線程獲得該鎖定時,將可以看到對這些變量進行的更改。弊 端是如果鎖定競爭太厲害(線程常常在其他線程具有鎖定時要求獲得該鎖定), 會損害吞吐量,因為競爭的同步非常昂貴。(Public Service Announcement: 對於現代 JVM 而言,無競爭的同步現在非常便宜。
基於鎖定的算法的另一個問題是:如果延遲具有鎖定的線程(因為頁面錯誤 、計劃延遲或其他意料之外的延遲),則 沒有要求獲得該鎖定的線程可以繼續 運行。
還可以使用可變變量來以比同步更低的成本存儲共享變量,但它們有局限性 。雖然可以保證其他變量可以立即看到對可變變量的寫入,但無法呈現原子操作 的讀-修改-寫順序,這意味著(比如說)可變變量無法用來可靠地實現互斥(互 斥鎖定)或計數器。
使用鎖定實現計數器和互斥
假如開發線程安全的計數器類,那麼這將暴露 get()、 increment() 和 decrement() 操作。清單 1 顯示了如何使用鎖定(同步)實現該類的例子。注 意所有方法,甚至需要同步 get(),使類成為線程安全的類,從而確保沒有任何 更新信息丟失,所有線程都看到計數器的最新值。
清單 1. 同步的計數器類
public class SynchronizedCounter {
private int value;
public synchronized int getValue() { return value; }
public synchronized int increment() { return ++value; }
public synchronized int decrement() { return --value; }
}
increment() 和 decrement() 操作是原子的讀-修改-寫操作,為了安全實現 計數器,必須使用當前值,並為其添加一個值,或寫出新值,所有這些均視為一 項操作,其他線程不能打斷它。否則,如果兩個線程試圖同時執行增加,操作的 不幸交叉將導致計數器只被實現了一次,而不是被實現兩次。(注意,通過使值 實例變量成為可變變量並不能可靠地完成這項操作。)
許多並發算法中都顯示了原子的讀-修改-寫組合。清單 2 中的代碼實現了簡 單的互斥, acquire() 方法也是原子的讀-修改-寫操作。要獲得互斥,必須確 保沒有其他人具有該互斥( curOwner = Thread.currentThread()),然後記錄 您擁有該互斥的事實( curOwner = Thread.currentThread()),所有這些使其 他線程不可能在中間出現以及修改 curOwner field。
清單 2. 同步的互斥類
public class SynchronizedMutex {
private Thread curOwner = null;
public synchronized void acquire() throws InterruptedException {
if (Thread.interrupted()) throw new InterruptedException ();
while (curOwner != null)
wait();
curOwner = Thread.currentThread();
}
public synchronized void release() {
if (curOwner == Thread.currentThread()) {
curOwner = null;
notify();
} else
throw new IllegalStateException("not owner of mutex");
}
}
清單 1 中的計數器類可以可靠地工作,在競爭很小或沒有競爭時都可以很好 地執行。然而,在競爭激烈時,這將大大損害性能,因為 JVM 用了更多的時間 來調度線程,管理競爭和等待線程隊列,而實際工作(如增加計數器)的時間卻 很少。您可以回想 上月專欄中的圖,該圖顯示了一旦多個線程使用同步競爭一 個內置監視器,吞吐量將如何大幅度下降。雖然該專欄說明了新的 ReentrantLock 類如何可以更可伸縮地替代同步,但是對於一些問題,還有更好 的解決方法。
鎖定問題
使用鎖定,如果一個線程試圖獲取其他線程已經具有的鎖定,那麼該線程將 被阻塞,直到該鎖定可用。此方法具有一些明顯的缺點,其中包括當線程被阻塞 來等待鎖定時,它無法進行其他任何操作。如果阻塞的線程是高優先級的任務, 那麼該方案可能造成非常不好的結果(稱為 優先級倒置的危險)。
使用鎖定還有一些其他危險,如死鎖(當以不一致的順序獲得多個鎖定時會 發生死鎖)。甚至沒有這種危險,鎖定也僅是相對的粗粒度協調機制,同樣非常 適合管理簡單操作,如增加計數器或更新互斥擁有者。如果有更細粒度的機制來 可靠管理對單獨變量的並發更新,則會更好一些;在大多數現代處理器都有這種 機制。
硬件同步原語
如前所述,大多數現代處理器都包含對多處理的支持。當然這種支持包括多 處理器可以共享外部設備和主內存,同時它通常還包括對指令系統的增加來支持 多處理的特殊要求。特別是,幾乎每個現代處理器都有通過可以檢測或阻止其他 處理器的並發訪問的方式來更新共享變量的指令。
比較並交換 (CAS)
支持並發的第一個處理器提供原子的測試並設置操作,通常在單位上運行這 項操作。現在的處理器(包括 Intel 和 Sparc 處理器)使用的最通用的方法是 實現名為 比較並轉換或 CAS 的原語。(在 Intel 處理器中,比較並交換通過 指令的 cmpxchg 系列實現。PowerPC 處理器有一對名為“加載並保留”和“條 件存儲”的指令,它們實現相同的目地;MIPS 與 PowerPC 處理器相似,除了第 一個指令稱為“加載鏈接”。)
CAS 操作包含三個操作數 —— 內存位置(V)、預期原值(A)和新值(B)。 如果內存位置的值與預期原值相匹配,那麼處理器會自動將該位置值更新為新值 。否則,處理器不做任何操作。無論哪種情況,它都會在 CAS 指令之前返回該 位置的值。(在 CAS 的一些特殊情況下將僅返回 CAS 是否成功,而不提取當前 值。)CAS 有效地說明了“我認為位置 V 應該包含值 A;如果包含該值,則將 B 放到這個位置;否則,不要更改該位置,只告訴我這個位置現在的值即可。”
通常將 CAS 用於同步的方式是從地址 V 讀取值 A,執行多步計算來獲得新 值 B,然後使用 CAS 將 V 的值從 A 改為 B。如果 V 處的值尚未同時更改,則 CAS 操作成功。
類似於 CAS 的指令允許算法執行讀-修改-寫操作,而無需害怕其他線程同時 修改變量,因為如果其他線程修改變量,那麼 CAS 會檢測它(並失敗),算法 可以對該操作重新計算。清單 3 說明了 CAS 操作的行為(而不是性能特征), 但是 CAS 的價值是它可以在硬件中實現,並且是極輕量級的(在大多數處理器 中):
清單 3. 說明比較並交換的行為(而不是性能)的代碼
public class SimulatedCAS {
private int value;
public synchronized int getValue() { return value; }
public synchronized int compareAndSwap(int expectedValue, int newValue) {
if (value == expectedValue)
value = newValue;
return value;
}
}
使用 CAS 實現計數器
基於 CAS 的並發算法稱為 無鎖定算法,因為線程不必再等待鎖定(有時稱 為互斥或關鍵部分,這取決於線程平台的術語)。無論 CAS 操作成功還是失敗 ,在任何一種情況中,它都在可預知的時間內完成。如果 CAS 失敗,調用者可 以重試 CAS 操作或采取其他適合的操作。清單 4 顯示了重新編寫的計數器類來 使用 CAS 替代鎖定:
清單 4. 使用比較並交換實現計數器
public class CasCounter {
private SimulatedCAS value;
public int getValue() {
return value.getValue();
}
public int increment() {
int oldValue = value.getValue();
while (value.compareAndSwap(oldValue, oldValue + 1) != oldValue)
oldValue = value.getValue();
return oldValue + 1;
}
}
無鎖定且無等待算法
如果每個線程在其他線程任意延遲(或甚至失敗)時都將持續進行操作,就 可以說該算法是 無等待的。與此形成對比的是, 無鎖定算法要求僅 某個線程 總是執行操作。(無等待的另一種定義是保證每個線程在其有限的步驟中正確計 算自己的操作,而不管其他線程的操作、計時、交叉或速度。這一限制可以是系 統中線程數的函數;例如,如果有 10 個線程,每個線程都執行一次 CasCounter.increment() 操作,最壞的情況下,每個線程將必須重試最多九次 ,才能完成增加。)
再過去的 15 年裡,人們已經對無等待且無鎖定算法(也稱為 無阻塞算法) 進行了大量研究,許多人通用數據結構已經發現了無阻塞算法。無阻塞算法被廣 泛用於操作系統和 JVM 級別,進行諸如線程和進程調度等任務。雖然它們的實 現比較復雜,但相對於基於鎖定的備選算法,它們有許多優點:可以避免優先級 倒置和死鎖等危險,競爭比較便宜,協調發生在更細的粒度級別,允許更高程度 的並行機制等等。
原子變量類
在 JDK 5.0 之前,如果不使用本機代碼,就不能用 Java 語言編寫無等待、 無鎖定的算法。在 java.util.concurrent.atomic 包中添加原子變量類之後, 這種情況才發生了改變。所有原子變量類都公開比較並設置原語(與比較並交換 類似),這些原語都是使用平台上可用的最快本機結構(比較並交換、加載鏈接 /條件存儲,最壞的情況下是旋轉鎖)來實現的。java.util.concurrent.atomic 包中提供了原子變量的 9 種風格( AtomicInteger; AtomicLong; AtomicReference; AtomicBoolean;原子整型;長型;引用;及原子標記引用 和戳記引用類的數組形式,其原子地更新一對值)。
原子變量類可以認為是 volatile 變量的泛化,它擴展了可變變量的概念, 來支持原子條件的比較並設置更新。讀取和寫入原子變量與讀取和寫入對可變變 量的訪問具有相同的存取語義。
雖然原子變量類表面看起來與清單 1 中的 SynchronizedCounter 例子一樣 ,但相似僅是表面的。在表面之下,原子變量的操作會變為平台提供的用於並發 訪問的硬件原語,比如比較並交換。
更細粒度意味著更輕量級
調整具有競爭的並發應用程序的可伸縮性的通用技術是降低使用的鎖定對象 的粒度,希望更多的鎖定請求從競爭變為不競爭。從鎖定轉換為原子變量可以獲 得相同的結果,通過切換為更細粒度的協調機制,競爭的操作就更少,從而提高 了吞吐量。
java.util.concurrent 中的原子變量
無論是直接的還是間接的,幾乎 java.util.concurrent 包中的所有類都使 用原子變量,而不使用同步。類似 ConcurrentLinkedQueue 的類也使用原子變 量直接實現無等待算法,而類似 ConcurrentHashMap 的類使用 ReentrantLock 在需要時進行鎖定。然後, ReentrantLock 使用原子變量來維護等待鎖定的線 程隊列。
如果沒有 JDK 5.0 中的 JVM 改進,將無法構造這些類,這些改進暴露了( 向類庫,而不是用戶類)接口來訪問硬件級的同步原語。然後, java.util.concurrent 中的原子變量類和其他類向用戶類公開這些功能。
使用原子變量獲得更高的吞吐量
上月,我介紹了 ReentrantLock 如何相對於同步提供可伸縮性優勢,以及構 造通過偽隨機數生成器模擬旋轉骰子的簡單、高競爭示例基准。我向您顯示了通 過同步、 ReentrantLock 和公平 ReentrantLock 來進行協調的實現,並顯示了 結果。本月,我將向該基准添加其他實現,使用 AtomicLong 更新 PRNG 狀態的 實現。
清單 5 顯示了使用同步的 PRNG 實現和使用 CAS 備選實現。注意,要在循 環中執行 CAS,因為它可能會失敗一次或多次才能獲得成功,使用 CAS 的代碼 總是這樣。
清單 5. 使用同步和原子變量實現線程安全 PRNG
public class PseudoRandomUsingSynch implements PseudoRandom {
private int seed;
public PseudoRandomUsingSynch(int s) { seed = s; }
public synchronized int nextInt(int n) {
int s = seed;
seed = Util.calculateNext(seed);
return s % n;
}
}
public class PseudoRandomUsingAtomic implements PseudoRandom {
private final AtomicInteger seed;
public PseudoRandomUsingAtomic(int s) {
seed = new AtomicInteger(s);
}
public int nextInt(int n) {
for (;;) {
int s = seed.get();
int nexts = Util.calculateNext(s);
if (seed.compareAndSet(s, nexts))
return s % n;
}
}
}
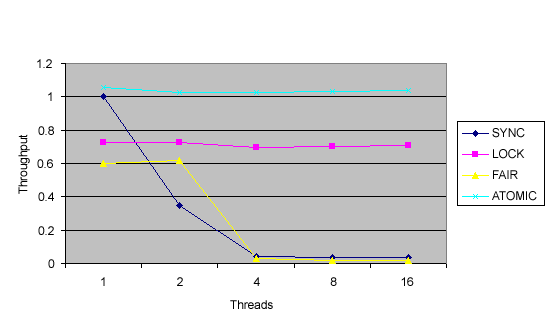
下面圖 1 和圖 2 中的圖與上月那些圖相似,只是為基於原子的方法多添加 了一行。這些圖顯示了在 8-way Ultrasparc3 和單處理器 Pentium 4 上使用不 同數量線程的隨機發生的吞吐量(以每秒轉數為單位)。測試中的線程數不是真 實的;這些線程所表現的競爭比通常多得多,所以它們以比實際程序中低得多的 線程數顯示了 ReentrantLock 與原子變量之間的平衡。您將看到,雖然 ReentrantLock 擁有比同步更多的優點,但相對於 ReentrantLock,原子變量提 供了其他改進。(因為在每個工作單元中完成的工作很少,所以下圖可能無法完 全地說明與 ReentrantLock 相比,原子變量具有哪些可伸縮性優點。)
圖 1. 8-way Ultrasparc3 中同步、ReentrantLock、公平 Lock 和 AtomicLong 的基准吞吐量
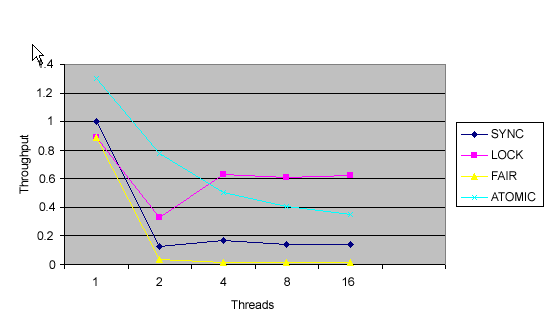
圖 2. 單處理器 Pentium 4 中的同步、ReentrantLock、公平 Lock 和 AtomicLong 的基准吞吐量
大多數用戶都不太可能使用原子變量自己開發無阻塞算法 — 他們更可能使 用 java.util.concurrent 中提供的版本,如 ConcurrentLinkedQueue。但是萬 一您想知道對比以前 JDK 中的相類似的功能,這些類的性能是如何改進的,可 以使用通過原子變量類公開的細粒度、硬件級別的並發原語。
開發人員可以直接將原子變量用作共享計數器、序號生成器和其他獨立共享 變量的高性能替代,否則必須通過同步保護這些變量。
結束語
JDK 5.0 是開發高性能並發類的巨大進步。通過內部公開新的低級協調原語 ,和提供一組公共原子變量類,現在用 Java 語言開發無等待、無鎖定算法首次 變為可行。然後, java.util.concurrent 中的類基於這些低級原子變量工具構 建,為它們提供比以前執行相似功能的類更顯著的可伸縮性優點。雖然您可能永 遠不會直接使用原子變量,還是應該為它們的存在而歡呼。