Java 阻塞隊列詳解及簡單使用。本站提示廣大學習愛好者:(Java 阻塞隊列詳解及簡單使用)文章只能為提供參考,不一定能成為您想要的結果。以下是Java 阻塞隊列詳解及簡單使用正文
Java 阻塞隊列詳解
概要:
在新增的Concurrent包中,BlockingQueue很好的解決了多線程中,如何高效安全“傳輸”數據的問題。通過這些高效並且線程安全的隊列類,為我們快速搭建高質量的多線程程序帶來極大的便利。本文詳細介紹了BlockingQueue家庭中的所有成員,包括他們各自的功能以及常見使用場景。
認識BlockingQueue阻塞隊列,顧名思義,首先它是一個隊列,而一個隊列在數據結構中所起的作用大致如下圖所示:
從上圖我們可以很清楚看到,通過一個共享的隊列,可以使得數據由隊列的一端輸入,從另外一端輸出;
常用的隊列主要有以下兩種:(當然通過不同的實現方式,還可以延伸出很多不同類型的隊列,DelayQueue就是其中的一種)
1. 先進先出(FIFO):先插入的隊列的元素也最先出隊列,類似於排隊的功能。從某種程度上來說這種隊列也體現了一種公平性。
2. 後進先出(LIFO):後插入隊列的元素最先出隊列,這種隊列優先處理最近發生的事件。
多線程環境中,通過隊列可以很容易實現數據共享,比如經典的“生產者”和“消費者”模型中,通過隊列可以很便利地實現兩者之間的數據共享。假設我們有若干生產者線程,另外又有若干個消費者線程。如果生產者線程需要把准備好的數據共享給消費者線程,利用隊列的方式來傳遞數據,就可以很方便地解決他們之間的數據共享問題。但如果生產者和消費者在某個時間段內,萬一發生數據處理速度不匹配的情況呢?理想情況下,如果生產者產出數據的速度大於消費者消費的速度,並且當生產出來的數據累積到一定程度的時候,那麼生產者必須暫停等待一下(阻塞生產者線程),以便等待消費者線程把累積的數據處理完畢,反之亦然。然而,在concurrent包發布以前,在多線程環境下,我們每個程序員都必須去自己控制這些細節,尤其還要兼顧效率和線程安全,而這會給我們的程序帶來不小的復雜度。好在此時,強大的concurrent包橫空出世了,而他也給我們帶來了強大的BlockingQueue。(在多線程領域:所謂阻塞,在某些情況下會掛起線程(即阻塞),一旦條件滿足,被掛起的線程又會自動被喚醒)
下面兩幅圖演示了BlockingQueue的兩個常見阻塞場景:
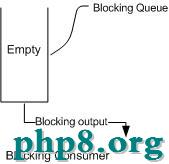
如上圖所示:當隊列中沒有數據的情況下,消費者端的所有線程都會被自動阻塞(掛起),直到有數據放入隊列。
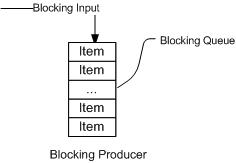
如上圖所示:當隊列中填滿數據的情況下,生產者端的所有線程都會被自動阻塞(掛起),直到隊列中有空的位置,線程被自動喚醒。
這也是我們在多線程環境下,為什麼需要BlockingQueue的原因。作為BlockingQueue的使用者,我們再也不需要關心什麼時候需要阻塞線程,什麼時候需要喚醒線程,因為這一切BlockingQueue都給你一手包辦了。既然BlockingQueue如此神通廣大,讓我們一起來見識下它的常用方法:
BlockingQueue的核心方法:
放入數據:
offer(anObject):表示如果可能的話,將anObject加到BlockingQueue裡,即如果BlockingQueue可以容納, 則返回true,否則返回false
(本方法不阻塞當前執行方法的線程)
offer(E o, long timeout, TimeUnit unit),可以設定等待的時間,如果在指定的時間內,還不能往隊列中加入BlockingQueue,則返回失敗。
put(anObject):把anObject加到BlockingQueue裡,如果BlockQueue沒有空間,則調用此方法的線程被阻斷直到BlockingQueue裡面有空間再繼續.
獲取數據:
poll(time):取走BlockingQueue裡排在首位的對象,若不能立即取出,則可以等time參數規定的時間,
取不到時返回null;
poll(long timeout, TimeUnit unit):從BlockingQueue取出一個隊首的對象,如果在指定時間內,
隊列一旦有數據可取,則立即返回隊列中的數據。否則知道時間超時還沒有數據可取,返回失敗。
take():取走BlockingQueue裡排在首位的對象,若BlockingQueue為空,阻斷進入等待狀態直到
BlockingQueue有新的數據被加入;
drainTo():一次性從BlockingQueue獲取所有可用的數據對象(還可以指定獲取數據的個數),
通過該方法,可以提升獲取數據效率;不需要多次分批加鎖或釋放鎖。
常見BlockingQueue
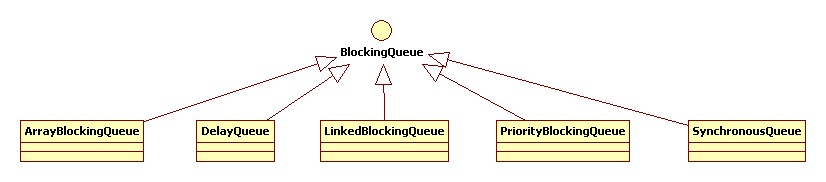
在了解了BlockingQueue的基本功能後,讓我們來看看BlockingQueue家庭大致有哪些成員?
BlockingQueue成員詳細介紹
1. ArrayBlockingQueue
基於數組的阻塞隊列實現,在ArrayBlockingQueue內部,維護了一個定長數組,以便緩存隊列中的數據對象,這是一個常用的阻塞隊列,除了一個定長數組外,ArrayBlockingQueue內部還保存著兩個整形變量,分別標識著隊列的頭部和尾部在數組中的位置。
ArrayBlockingQueue在生產者放入數據和消費者獲取數據,都是共用同一個鎖對象,由此也意味著兩者無法真正並行運行,這點尤其不同於LinkedBlockingQueue;按照實現原理來分析,ArrayBlockingQueue完全可以采用分離鎖,從而實現生產者和消費者操作的完全並行運行。Doug Lea之所以沒這樣去做,也許是因為ArrayBlockingQueue的數據寫入和獲取操作已經足夠輕巧,以至於引入獨立的鎖機制,除了給代碼帶來額外的復雜性外,其在性能上完全占不到任何便宜。 ArrayBlockingQueue和LinkedBlockingQueue間還有一個明顯的不同之處在於,前者在插入或刪除元素時不會產生或銷毀任何額外的對象實例,而後者則會生成一個額外的Node對象。這在長時間內需要高效並發地處理大批量數據的系統中,其對於GC的影響還是存在一定的區別。而在創建ArrayBlockingQueue時,我們還可以控制對象的內部鎖是否采用公平鎖,默認采用非公平鎖。
2. LinkedBlockingQueue
基於鏈表的阻塞隊列,同ArrayListBlockingQueue類似,其內部也維持著一個數據緩沖隊列(該隊列由一個鏈表構成),當生產者往隊列中放入一個數據時,隊列會從生產者手中獲取數據,並緩存在隊列內部,而生產者立即返回;只有當隊列緩沖區達到最大值緩存容量時(LinkedBlockingQueue可以通過構造函數指定該值),才會阻塞生產者隊列,直到消費者從隊列中消費掉一份數據,生產者線程會被喚醒,反之對於消費者這端的處理也基於同樣的原理。而LinkedBlockingQueue之所以能夠高效的處理並發數據,還因為其對於生產者端和消費者端分別采用了獨立的鎖來控制數據同步,這也意味著在高並發的情況下生產者和消費者可以並行地操作隊列中的數據,以此來提高整個隊列的並發性能。
作為開發者,我們需要注意的是,如果構造一個LinkedBlockingQueue對象,而沒有指定其容量大小,LinkedBlockingQueue會默認一個類似無限大小的容量(Integer.MAX_VALUE),這樣的話,如果生產者的速度一旦大於消費者的速度,也許還沒有等到隊列滿阻塞產生,系統內存就有可能已被消耗殆盡了。
ArrayBlockingQueue和LinkedBlockingQueue是兩個最普通也是最常用的阻塞隊列,一般情況下,在處理多線程間的生產者消費者問題,使用這兩個類足以。
下面的代碼演示了如何使用BlockingQueue:
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.LinkedBlockingQueue;
/**
* @author jackyuj
*/
public class BlockingQueueTest {
public static void main(String[] args) throws InterruptedException {
// 聲明一個容量為10的緩存隊列
BlockingQueue<String> queue = new LinkedBlockingQueue<String>(10);
Producer producer1 = new Producer(queue);
Producer producer2 = new Producer(queue);
Producer producer3 = new Producer(queue);
Consumer consumer = new Consumer(queue);
// 借助Executors
ExecutorService service = Executors.newCachedThreadPool();
// 啟動線程
service.execute(producer1);
service.execute(producer2);
service.execute(producer3);
service.execute(consumer);
// 執行10s
Thread.sleep(10 * 1000);
producer1.stop();
producer2.stop();
producer3.stop();
Thread.sleep(2000);
// 退出Executor
service.shutdown();
}
}
import java.util.Random;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.TimeUnit;
/**
* 消費者線程
*
* @author jackyuj
*/
public class Consumer implements Runnable {
public Consumer(BlockingQueue<String> queue) {
this.queue = queue;
}
public void run() {
System.out.println("啟動消費者線程!");
Random r = new Random();
boolean isRunning = true;
try {
while (isRunning) {
System.out.println("正從隊列獲取數據...");
String data = queue.poll(2, TimeUnit.SECONDS);
if (null != data) {
System.out.println("拿到數據:" + data);
System.out.println("正在消費數據:" + data);
Thread.sleep(r.nextInt(DEFAULT_RANGE_FOR_SLEEP));
} else {
// 超過2s還沒數據,認為所有生產線程都已經退出,自動退出消費線程。
isRunning = false;
}
}
} catch (InterruptedException e) {
e.printStackTrace();
Thread.currentThread().interrupt();
} finally {
System.out.println("退出消費者線程!");
}
}
private BlockingQueue<String> queue;
private static final int DEFAULT_RANGE_FOR_SLEEP = 1000;
}
import java.util.Random;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicInteger;
/**
* 生產者線程
*
* @author jackyuj
*/
public class Producer implements Runnable {
public Producer(BlockingQueue queue) {
this.queue = queue;
}
public void run() {
String data = null;
Random r = new Random();
System.out.println("啟動生產者線程!");
try {
while (isRunning) {
System.out.println("正在生產數據...");
Thread.sleep(r.nextInt(DEFAULT_RANGE_FOR_SLEEP));
data = "data:" + count.incrementAndGet();
System.out.println("將數據:" + data + "放入隊列...");
if (!queue.offer(data, 2, TimeUnit.SECONDS)) {
System.out.println("放入數據失敗:" + data);
}
}
} catch (InterruptedException e) {
e.printStackTrace();
Thread.currentThread().interrupt();
} finally {
System.out.println("退出生產者線程!");
}
}
public void stop() {
isRunning = false;
}
private volatile boolean isRunning = true;
private BlockingQueue queue;
private static AtomicInteger count = new AtomicInteger();
private static final int DEFAULT_RANGE_FOR_SLEEP = 1000;
}
1.DelayQueue
DelayQueue中的元素只有當其指定的延遲時間到了,才能夠從隊列中獲取到該元素。DelayQueue是一個沒有大小限制的隊列,因此往隊列中插入數據的操作(生產者)永遠不會被阻塞,而只有獲取數據的操作(消費者)才會被阻塞。
使用場景:
DelayQueue使用場景較少,但都相當巧妙,常見的例子比如使用一個DelayQueue來管理一個超時未響應的連接隊列。
2.PriorityBlockingQueue
基於優先級的阻塞隊列(優先級的判斷通過構造函數傳入的Compator對象來決定),但需要注意的是PriorityBlockingQueue並不會阻塞數據生產者,而只會在沒有可消費的數據時,阻塞數據的消費者。因此使用的時候要特別注意,生產者生產數據的速度絕對不能快於消費者消費數據的速度,否則時間一長,會最終耗盡所有的可用堆內存空間。在實現PriorityBlockingQueue時,內部控制線程同步的鎖采用的是公平鎖。
3.SynchronousQueue
一種無緩沖的等待隊列,類似於無中介的直接交易,有點像原始社會中的生產者和消費者,生產者拿著產品去集市銷售給產品的最終消費者,而消費者必須親自去集市找到所要商品的直接生產者,如果一方沒有找到合適的目標,那麼對不起,大家都在集市等待。相對於有緩沖的BlockingQueue來說,少了一個中間經銷商的環節(緩沖區),如果有經銷商,生產者直接把產品批發給經銷商,而無需在意經銷商最終會將這些產品賣給那些消費者,由於經銷商可以庫存一部分商品,因此相對於直接交易模式,總體來說采用中間經銷商的模式會吞吐量高一些(可以批量買賣);但另一方面,又因為經銷商的引入,使得產品從生產者到消費者中間增加了額外的交易環節,單個產品的及時響應性能可能會降低。
聲明一個SynchronousQueue有兩種不同的方式,它們之間有著不太一樣的行為。公平模式和非公平模式的區別:
如果采用公平模式:SynchronousQueue會采用公平鎖,並配合一個FIFO隊列來阻塞多余的生產者和消費者,從而體系整體的公平策略;
但如果是非公平模式(SynchronousQueue默認):SynchronousQueue采用非公平鎖,同時配合一個LIFO隊列來管理多余的生產者和消費者,而後一種模式,如果生產者和消費者的處理速度有差距,則很容易出現饑渴的情況,即可能有某些生產者或者是消費者的數據永遠都得不到處理。
小結
BlockingQueue不光實現了一個完整隊列所具有的基本功能,同時在多線程環境下,他還自動管理了多線間的自動等待於喚醒功能,從而使得程序員可以忽略這些細節,關注更高級的功能。
感謝閱讀,希望能幫助到大家,謝謝大家對本站的支持!