疾速排序的深刻詳解和java完成。本站提示廣大學習愛好者:(疾速排序的深刻詳解和java完成)文章只能為提供參考,不一定能成為您想要的結果。以下是疾速排序的深刻詳解和java完成正文
直接上需乞降代碼
起首是須要爬取的鏈接和網頁:http://211.81.31.34/uhtbin/cgisirsi/x/0/0/57/49?user_id=LIBSCI_ENGI&password=LIBSC

上岸出來以後進入我的賬號——借閱、預定及請求記載——借經歷史便可以看到所要爬取的內容

然後將借經歷史中的落款、著者、借閱日期、清償日期、索書號存入Mongodb數據庫中,以上就是此次爬蟲的需求。
上面開端:
各軟件版本為:
1、上岸模塊
python中的上岸普通都是用urllib和urllib2這兩個模塊,起首我們要檢查網頁的源代碼:
<form name="loginform" method="post" action="/uhtbin/cgisirsi/?ps=nPdFje4RP9/理工年夜學館/125620449/303">
<!-- Copyright (c) 2004, Sirsi Corporation - myProfile login or view myFavorites -->
<!-- Copyright (c) 1998 - 2003, Sirsi Corporation - Sets the default values for USER_ID, ALT_ID, and PIN prompts. - The USER_ID, ALT_ID, and PIN page variables will be returned. -->
<!-- If the user has not logged in, first try to default to the ID based on the IP address - the $UO and $Uf will be set. If that fails, then default to the IDs in the config file. If the user has already logged in, default to the logged in user's IDs, unless the user is a shared login. -->
<!-- only user ID is used if both on -->
<div class="user_name">
<label for="user_id">借閱證號碼:</label>
<input class="user_name_input" type="text" name="user_id" id="user_id" maxlength="20" value=""/>
</div>
<div class="password">
<label for="password">小我暗碼:</label>
<input class="password_input" type="password" name="password" id="password" maxlength="20" value=""/>
</div>
<input type="submit" value="用戶登錄" class="login_button"/>
查找網頁中的form表單中的action,辦法為post,然則隨後我們發明,該網頁中的action地址不是必定的,是隨機變更的,刷新一下就釀成了上面如許子的:
<form name="loginform" method="post" action="/uhtbin/cgisirsi/?ps=1Nimt5K1Lt/理工年夜學館/202330426/303">
我們可以看到/?ps到/之間的字符串是隨機變更的(加粗部門),因而我們須要用到另外一個模塊——BeautifulSoup及時獲得該鏈接:
url = "http://211.81.31.34/uhtbin/cgisirsi/x/0/0/57/49?user_id=LIBSCI_ENGI&password=LIBSC"
res = urllib2.urlopen(url).read()
soup = BeautifulSoup(res, "html.parser")
login_url = "http://211.81.31.34" + soup.findAll("form")[1]['action'].encode("utf8")
以後便可以正常應用urllib和urllib來模仿上岸了,上面羅列一下BeautifulSoup的經常使用辦法,以後的HTML解析須要:
1.soup.contents 該屬性可以將tag的子節點以列表的方法輸入
2.soup.children 經由過程tag的.children生成器,可以對tag的子節點停止輪回
3.soup.parent 獲得某個元素的父節點
4.soup.find_all(name,attrs,recursive,text,**kwargs) 搜刮以後tag的一切tag子節點,並斷定能否相符過濾器的前提
5.soup.find_all("a",class="xx") 按CSS搜刮
6.find(name,attrs,recursive,text,**kwargs) 可以經由過程limit和find_all辨別開
2、解析所取得的HTML
先看看需求中的HTML的特色:
<tbody id="tblSuspensions">
<!-- OCLN changed Listcode to Le to support charge history -->
<!-- SIRSI_List Listcode="LN" -->
<tr>
<td class="accountstyle" align="left">
<!-- SIRSI_Conditional IF List_DC_Exists="IB" AND NOT List_DC_Comp="IB^" -->
<!-- Start title here -->
<!-- Title -->
做人要低調,措辭要滑稽 孫郡铠編著
</td>
<td class="accountstyle author" align="left">
<!-- Author -->
孫郡铠 編著
</td>
<td class="accountstyle due_date" align="center">
<!-- Date Charged -->
2015/9/10,16:16
</td>
<td class="accountstyle due_date" align="left">
<!-- Date Returned -->
2015/9/23,15:15
</td>
<td class="accountstyle author" align="center">
<!-- Call Number -->
B821-49/S65
</td>
</tr>
<tr>
<td class="accountstyle" align="left">
<!-- SIRSI_Conditional IF List_DC_Exists="IB" AND NOT List_DC_Comp="IB^" -->
<!-- Start title here -->
<!-- Title -->
我用平生去尋覓 潘石屹的人生哲學 潘石屹著
</td>
<td class="accountstyle author" align="left">
<!-- Author -->
潘石屹, 1963- 著
</td>
<td class="accountstyle due_date" align="center">
<!-- Date Charged -->
2015/9/10,16:16
</td>
<td class="accountstyle due_date" align="left">
<!-- Date Returned -->
2015/9/25,15:23
</td>
<td class="accountstyle author" align="center">
<!-- Call Number -->
B821-49/P89
</td>
</tr>
由一切代碼,留意這行:
<tbody id="tblSuspensions">
該標簽表現上面的內容將是借閱書本的相干信息,我們采取遍歷該網頁一切子節點的辦法取得id="tblSuspensions"的內容:
for i, k in enumerate(BeautifulSoup(detail, "html.parser").find(id='tblSuspensions').children):
# print i,k
if isinstance(k, element.Tag):
bookhtml.append(k)
# print type(k)
3、提取所須要的內容
這一步比擬簡略,bs4中的BeautifulSoup可以隨意馬虎的提取:
for i in bookhtml:
# p
# rint i
name = i.find(class_="accountstyle").getText()
author = i.find(class_="accountstyle author", align="left").getText()
Date_Charged = i.find(class_="accountstyle due_date", align="center").getText()
Date_Returned = i.find(class_="accountstyle due_date", align="left").getText()
bookid = i.find(class_="accountstyle author", align="center").getText()
bookinfo.append(
[name.strip(), author.strip(), Date_Charged.strip(), Date_Returned.strip(), bookid.strip()])
這一步采取getText()的辦法將text中內容提掏出來;strip()辦法是去失落前後空格,同時可以保存之間的空格,好比:s=" a a ",應用s.strip()以後即為"a a"
4、銜接數據庫
聽說NoSQL今後會很風行,隨後采取了Mongodb數據庫圖圖新穎,成果一折騰真是煩,詳細裝置辦法在上一篇日志中記錄了。
1.導入python銜接Mongodb的模塊
import pymongo
2.創立python和Mongodb的鏈接:
# connection database
conn = pymongo.MongoClient("mongodb://root:root@localhost:27017")
db = conn.book
collection = db.book
3.將取得的內容保留到數據庫:
user = {"_id": xuehao_ben,
"Bookname": name.strip(),
"Author": author.strip(),
"Rent_Day": Date_Charged.strip(),
"Return_Day": Date_Returned.strip()}
j += 1
collection.insert(user)
下面根本完成了,然則爬蟲做到這個沒成心義,重點鄙人面
5、獲得全校先生的借閱記載
我們黉捨的藏書樓的暗碼都是一樣的,應當沒有人閒得無聊改暗碼,乃至沒有人用過這個網站去查詢本身的借閱記載,所以,做個輪回,便可以隨意馬虎的獲得到全校的借閱記載了,然後並沒有那末簡略,str(0001)強迫將int釀成string,然則在cmd的python中是報錯的(在1地位),在pycharm後面三個0是疏忽的,只能用傻瓜式的四個for輪回了。好了,上面是一切代碼:
# encoding=utf8
import urllib2
import urllib
import pymongo
import socket
from bs4 import BeautifulSoup
from bs4 import element
# connection database
conn = pymongo.MongoClient("mongodb://root:root@localhost:27017")
db = conn.book
collection = db.book
# 輪回開端
def xunhuan(xuehao):
try:
socket.setdefaulttimeout(60)
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.bind(("127.0.0.1", 80))
url = "http://211.81.31.34/uhtbin/cgisirsi/x/0/0/57/49?user_id=LIBSCI_ENGI&password=LIBSC"
res = urllib2.urlopen(url).read()
soup = BeautifulSoup(res, "html.parser")
login_url = "http://211.81.31.34" + soup.findAll("form")[1]['action'].encode("utf8")
params = {
"user_id": "賬號前綴你猜你猜" + xuehao,
"password": "暗碼你猜猜"
}
print params
params = urllib.urlencode(params)
req = urllib2.Request(login_url, params)
lianjie = urllib2.urlopen(req)
# print lianjie
jieyue_res = lianjie.read()
# print jieyue_res 首頁的HTML代碼
houmian = BeautifulSoup(jieyue_res, "html.parser").find_all('a', class_='rootbar')[1]['href']
# print houmian
houmian = urllib.quote(houmian.encode('utf8'))
url_myaccount = "http://211.81.31.34" + houmian
# print url_myaccount
# print urllib.urlencode(BeautifulSoup(jieyue_res, "html.parser").find_all('a',class_ = 'rootbar')[0]['href'])
lianjie2 = urllib.urlopen(url_myaccount)
myaccounthtml = lianjie2.read()
detail_url = ''
# print (BeautifulSoup(myaccounthtml).find_all('ul',class_='gatelist_table')[0]).children
print "銜接完成,開端爬取數據"
for i in (BeautifulSoup(myaccounthtml, "html.parser").find_all('ul', class_='gatelist_table')[0]).children:
if isinstance(i, element.NavigableString):
continue
for ii in i.children:
detail_url = ii['href']
break
detail_url = "http://211.81.31.34" + urllib.quote(detail_url.encode('utf8'))
detail = urllib.urlopen(detail_url).read()
# print detail
bookhtml = []
bookinfo = []
# 處理沒有借書
try:
for i, k in enumerate(BeautifulSoup(detail, "html.parser").find(id='tblSuspensions').children):
# print i,k
if isinstance(k, element.Tag):
bookhtml.append(k)
# print type(k)
print "look here!!!"
j = 1
for i in bookhtml:
# p
# rint i
name = i.find(class_="accountstyle").getText()
author = i.find(class_="accountstyle author", align="left").getText()
Date_Charged = i.find(class_="accountstyle due_date", align="center").getText()
Date_Returned = i.find(class_="accountstyle due_date", align="left").getText()
bookid = i.find(class_="accountstyle author", align="center").getText()
bookinfo.append(
[name.strip(), author.strip(), Date_Charged.strip(), Date_Returned.strip(), bookid.strip()])
xuehao_ben = str(xuehao) + str("_") + str(j)
user = {"_id": xuehao_ben,
"Bookname": name.strip(),
"Author": author.strip(),
"Rent_Day": Date_Charged.strip(),
"Return_Day": Date_Returned.strip()}
j += 1
collection.insert(user)
except Exception, ee:
print ee
print "這人沒有借過書"
user = {"_id": xuehao,
"Bookname": "這人",
"Author": "沒有",
"Rent_Day": "借過",
"Return_Day": "書"}
collection.insert(user)
print "********" + str(xuehao) + "_Finish"+"**********"
except Exception, e:
s.close()
print e
print "socket超時,從新運轉"
xunhuan(xuehao)
# with contextlib.closing(urllib.urlopen(req)) as A:
# print A
# print xuehao
# print req
for i1 in range(0, 6):
for i2 in range(0, 9):
for i3 in range(0, 9):
for i4 in range(0, 9):
xueha = str(i1) + str(i2) + str(i3) + str(i4)
chushi = '0000'
if chushi == xueha:
print "=======爬蟲開端=========="
else:
print xueha + "begin"
xunhuan(xueha)
conn.close()
print "End!!!"
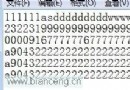
上面是Mongodb Management Studio的顯示內容(部門):

總結:此次爬蟲碰到了許多成績,問了許多人,然則終究後果還不是很幻想,固然用了try except語句,然則照樣會報錯10060,銜接超時(我只能質疑黉捨的辦事器了TT),還有就是,你可以看到數據庫中列的次序紛歧樣=。=這個我臨時未懂得,願望年夜家可以給出處理辦法。
以上就是本文的全體內容,願望對年夜家的進修有所贊助。